# 12.4美团面经
# 计算机网络
# TCP四次挥手的过程是怎样的?
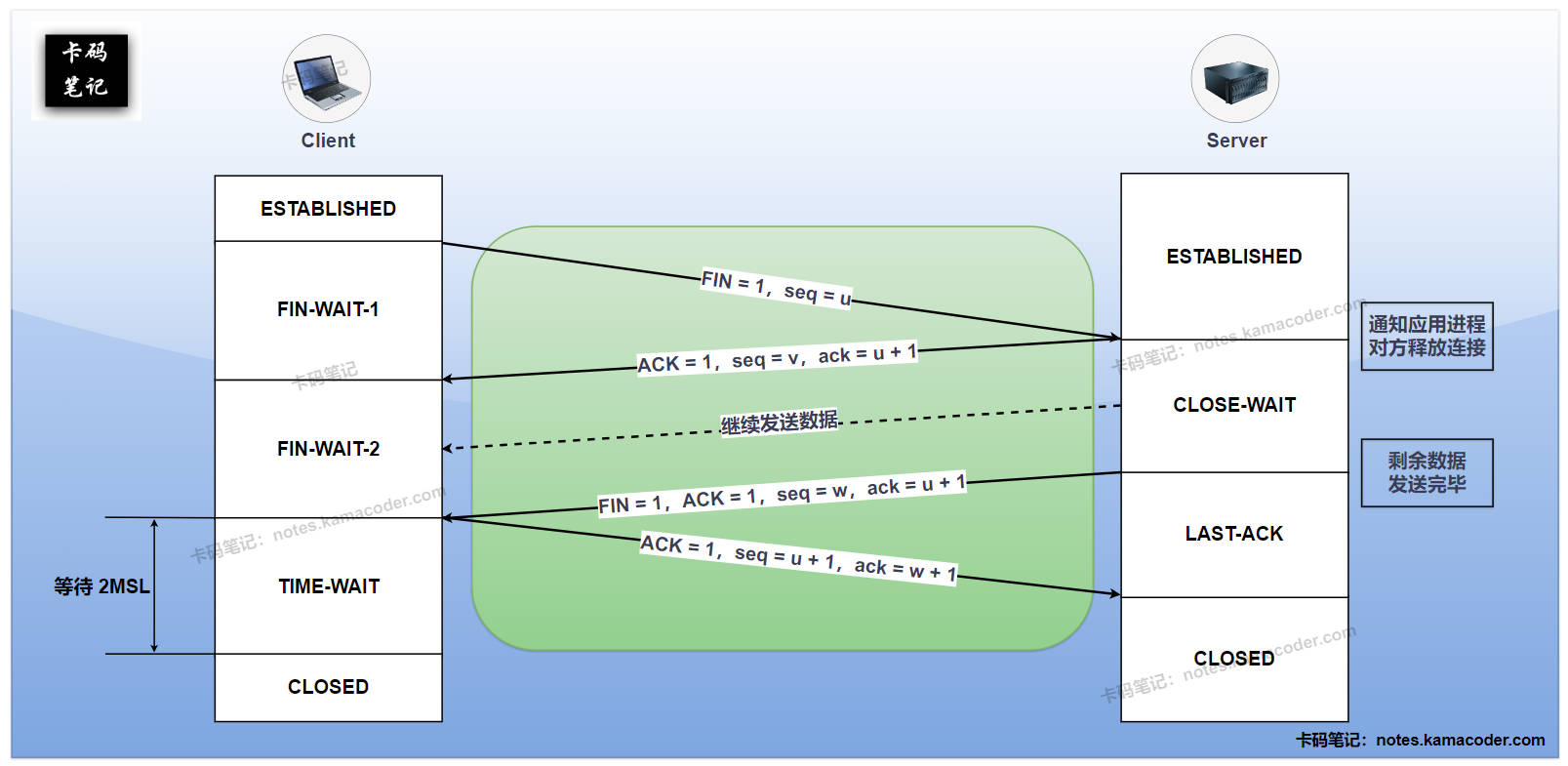
- 初始状态下双方都是ESTABLISHED状态,任意一方都可以关闭连接。
- 假设客户端为主动关闭方,第一次挥手是客户端先向服务器发送FIN连接释放报文,并进入FIN_WAIT_1状态;
- 第二次挥手是服务器收到FIN报文后,会发送一个ACK确认报文并进入CLOSE_WAIT状态。此时客户端到服务器的连接关闭,客户端收到ACK报文后进入FIN_WAIT_2状态;
- 第三次挥手是服务器处理完剩余数据后,向客户端发送FIN报文,并进入LAST_ACK状态;
- 第四次挥手是客户端收到FIN报文后,向服务端发送一个ACK报文并进入TIME_WAIT状态,等待2MSL(最长报文寿命)后关闭,服务器收到ACK报文就进入CLOSED状态,关闭本次连接。
# 为什么第四次挥手客户端需要等待2*MSL时间才进入CLOSED状态?
- MSL就是一个片段在网络中最大的存活时间。2MSL则是一个发送和回复的时间,客户端等待2MSL可以确定服务端已经接受ACK报文,从而保证结束TCP连接。
- 第四次挥手时,如果客户端给服务端发送的ACK报文丢失或者服务端没有收到该报文的话,服务端会重发FIN报文。如果客户端收到了FIN就会重新发送ACK报文并再次等待2*MSL,这样可以防止服务端没有收到ACK报文,一直重发FIN。
# TCP三次握手过程中可以携带数据吗?
- TCP的第三次握手可以携带数据,因为客户端发送完ACK确认报文后就进入ESTABLISHED状态了,因此数据可以在第三次握手时开始传输。如果第三次握手的ACK确认报文丢失,客户端发送携带数据的包中包含了ACK标记作为补传确认消息,服务端会将其视为有效的第三次握手确认。后续服务端会处理该数据包并进行正常数据传输流程。
# TCP协议如何保证可靠传输?
- TCP通过序列号和确认号机制让发送方给每个字节的数据分配唯一序号,接收方收到数据后返回期望接收到的下一个字节序号作为确认,保证成功接收。
- 发送方发送数据后会启动计时器,超时没有收到ACK会自动重传;如果发送方收到三个重复的ACK包说明前一个数据包丢失,无需等待超时,此时会立即重传,提升效率。
- 接收方可以通过TCP头部的窗口大小字段告诉发送方自己缓冲区剩余容量,发送方按照窗口大小进行流量控制,实现按需发送,防止缓冲区溢出。
- TCP使用拥塞控制适配网络状态,动态调整发送速率,避免因为网络拥堵而导致的数据丢失。
- TCP协议计算数据包的校验和,接收方校验时发现校验和不匹配会丢弃数据包,等待发送方重传。
- 网络传输中数据包可能乱序到达,接收方会根据序列号重排序,并丢弃重复数据,确保应用层收到的是完整有序的数据。
# 数据结构
# 二叉树有哪些遍历算法?
- 二叉树的核心遍历算法可以分成DFS深度优先和BFS广度优先遍历两大类。
- 深度优先是优先遍历子树,可以用递归或者迭代实现。如前序遍历的顺序是根节点、左节点、右节点,中序遍历的遍历顺序是左节点、根节点和右节点,后序遍历的顺序是左节点、右节点和根节点。
- 广度优先是按层级进行遍历的,从根节点开始按照树的层次访问节点。可以使用队列结构实现二叉树的层序遍历。
# 前缀树是什么?
- 前缀树(字典树)是树形的数据结构,前缀树除了根节点之外每一个节点都包含一个字符,路径上经过的字符连接起来就是对应的字符串,每个节点的所有子节点字符不同。
- 前缀树可以利用字符串的公共前缀来减少查询时间,提升字符串的查询效率。
# 什么时候需要使用前缀树?
- 在开发搜索功能时,搜索引擎可以利用前缀树找到以该关键词为前缀的所有相关词条,实现自动补全;
- 前缀树可以进行词频统计,将每个单词插入前缀树后,在尾节点记录出现次数,可以快速查询到单词的频次。
- 在路由器转发数据包时,可以使用前缀树匹配IP地址的最长前缀,高效找到数据包的转发路径。
# 数据库
# Redis为什么快?
- Redis是纯内存的操作,读写无需磁盘IO,所以执行速度很快,可以达到微秒级。
- Redis采用的是单线程,没有线程上下文切换和锁竞争开销,不会导致死锁,还能减少资源损耗。
- 使用I/O多路复用模型,单线程可以同时监听多个网络连接,高效处理并发请求。
# 介绍一下I/O多路复用模型?
- I/O多路复用模型利用单个线程同时监听多个Socket(客户端连接),当某个Socket可读、可写(就绪状态)时得到通知,避免无效等待,可以充分利用CPU资源。
- 常采用epoll模式实现,在通知用户进程Socket就绪的同时把已就绪的Socket写入用户空间。
# I/O多路复用机制还有哪些实现?
- 早期实现I/O多路复用还有select和poll。epoll模式对他们进行了改进,没有FD数量限制,内核通过回调机制将就绪的Socket写入用户空间,无需遍历,并且只需一次拷贝,减少消耗。
- select是使用固定大小的位图进行存储,存储的数量有限,且寻找就绪的Socket需要遍历所有Socket,下次调用要重新初始化集合。
- poll使用动态数组进行存储,解决了select存储数量固定的问题,但是依旧需要遍历整个数组,存在拷贝开销。
# 什么是回表查询?
- 索引可以分为聚簇索引和非聚簇索引,也叫二级索引。聚簇索引是将数据和索引放在一块,B+树索引的叶子节点直接存储完整的数据行,查询效率高;而非聚簇索引则是数据与索引分开存储,叶子节点存储的是主键值。
- 在InnoDB存储引擎中,如果查询的数据不在二级索引中,就会触发回表查询,通过二级索引找到对应的主键值,再到聚集索引中查找整行数据。
# 什么是覆盖索引?
- 覆盖索引是指查询使用了索引,并且需要返回的列在该索引中已经全部可以找到的情况。
- 如果返回的列中没有创建索引,有可能会触发回表查询,需要避免使用select *语句。
# MySQL中超大分页怎么处理?
- 在数据量很大时,如果进行limit分页查询,需要对数据进行排序,越往后分页查询的效率越低;
- 创建覆盖索引可以提高性能,通过覆盖索引加子查询形式可以进行优化。
# 创建索引的原则有哪些?
- 对于数据量较大,查询比较频繁的表建立索引,增加用户体验。
- 对常常作为查询条件、排序和分组操作的字段建立索引。
- 选择区分度高的字段创建索引,尽量创建唯一索引。
- 对于字符串类型的字段可以建立前缀索引。
- 尽量创建联合索引,减少单列索引,联合索引有时可以覆盖索引,避免回表。
- 控制索引数量,索引数量过多会增大维护索引的成本
- 如果索引列不能存储NULL值,在创建表时使用NOT NULL约束,以便优化器高效选择。
# 多线程
# 线程池是怎么处理线程的?
- 当有任务被提交到线程池中时,如果当前线程池中线程数小于核心线程数,则新建线程执行该任务;如果线程数大于等于核心线程数且当前任务队列未满时将当前任务添加到任务队列中等待执行;如果任务队列已满,且当前线程池中线程数小于最大线程数,则创建新线程执行任务;如果当前线程数已经等于最大线程数了,线程池会调用拒绝策略方法。
# 线程池有哪些拒绝策略?哪个是默认的拒绝策略?
- AbortPolicy是默认的拒绝策略,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。
- DiscardPolicy是AbortPolicy的slient版本,直接丢掉任务而不产生异常。
- DiscardOldestPolicy是丢弃最老的策略,会将最早进入队列的任务删掉,也就是把队头移除再尝试入队。
- CallerRunsPolicy是添加到线程池失败时调用线程自己去执行任务,不会等待线程池中的线程去执行。
# 创建和使用线程池需要注意什么?
- 需要根据任务类型设置合理的核心线程数,如果是CPU密集型任务核心线程数可以设置为CPU的核心数+1,充分利用CPU资源;如果是I/O密集型任务,线程大部分时间在等待I/O操作,可以设置大一点的核心线程数。
- 考虑系统的资源限制设置最大线程数,如果过大可能会耗尽系统资源。
- 需要根据场景设置合理的阻塞队列大小和设置优先级规则。
- 需要确保启动线程池后再提交并执行任务,可以使用shutdown或shutdownNow方法关闭线程池;shutdown会等待执行中的任务完成再关闭线程池,shutdownNow则会尝试中断正在执行的任务,关闭线程池的同时返回尚未执行的任务列表。
- 如果业务不允许任务重复执行,需要在向线程池提交任务前对任务进行去重,或者在任务本身中增设标志位标识完成情况。还可以避免网络不稳定时浪费线程池资源。
- 如果任务涉及共享资源需要采取同步措施,防止线程池并发执行任务时出现数据不一致或者资源竞争的情况。
# 你了解哪些阻塞队列?
- ArrayBlockingQueue是一个有数组结构组成的有界阻塞队列
- LinkedBlockingQueue是一个由链表结构组成的阻塞队列,默认容量是Integer.MAX_VALUE,使用时可以重新指定容量。
- LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列,可以运用在工作窃取模式中。
- PriorityBlockingQueue是一个支持优先级排序的无界阻塞队列,默认情况下元素采取自然顺序升序排列,也可以自定义类实现compareTo()方法指定元素排序规则
- DelayQueue使用的是优先级队列,队列中的元素实现Delayed接口,创建元素时可以指定延迟多久获取当前元素,适合定时场景。
- SynchronousQueue是不存储元素的阻塞队列,一个put操作对应一个take操作,适合传递性场景。
- LinkedTransferQueue是一个链表结构组成的单向无界阻塞队列,设计了一种直接在生产者和消费者之间传输元素的机制,适合需要高效地在生产者和消费者之间直接传输数据的场景。
评论
验证登录状态...