# 众安后端一面面经
# 对juc包有什么了解?
- 回答:
- JUC包就是java.util.concurrent包,主要用于解决多线程场景下的同步、协作和管理问题。我常用的模块有线程池框架比如ThreadPoolExecutor,能够灵活配置参数满足不同的并发需求。同步工具类的CountDownLatch可以控制多个线程等待其他线程完成后再继续执行,原子类AtomicInteger可以保证线程安全,用来做状态标记比较方便,还有像ConcurrentHashMap这样的并发容器也是JUC提供的,用于替代HashMap保证线程安全,性能也比传统的HashTable好。
- JUC能够解决原生语法中的局限性,将并发编程中的高频需求如线程复用、线程安全和同步等封装成工具,开发者不用重复实现这些功能,提高了开发效率。
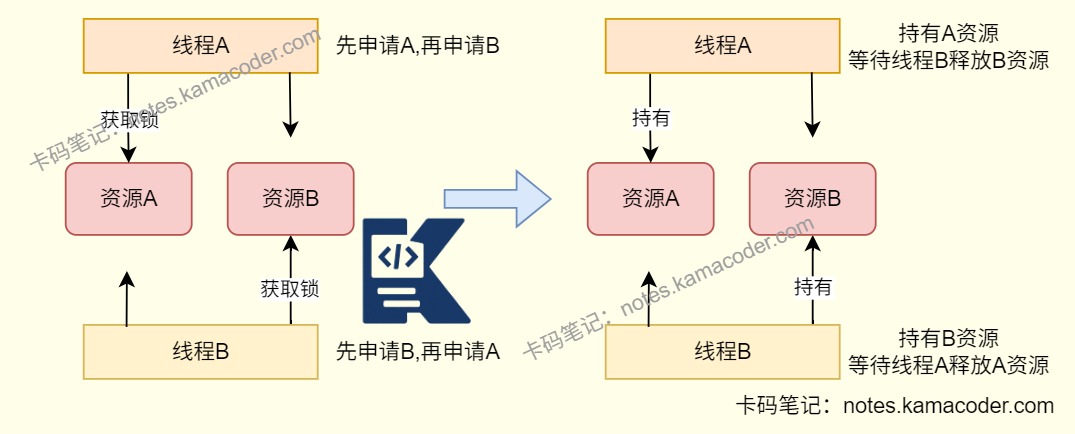
# 死锁是什么?怎么解决?
- 回答:1. 死锁是多线程或进程在竞争资源时,互相等待对方释放已持有的资源,导致所有线程都无法继续执行的永久阻塞状态。2. 发生死锁需要同时满足四个条件,分别是互斥、不可剥夺、持有并等待和出现环路等待。互斥条件是多个线程不能同时使用同一个资源,当一个线程占用了资源,其他线程不能使用该资源,必须等待占用资源的线程释放;不可剥夺条件是指线程已经持有资源时自己使用完之前不能被其他线程获取,只能由自己主动释放;持有并等待条件是线程在等待其他线程释放资源的时候不会释放自己已经持有的资源;环路等待则是在死锁出现是有多个线程获取资源的顺序构成资源请求循环(线程A等待线程B的资源,线程B等待线程A的资源)。3. 避免死锁发生只需要破坏上述的任意一个条件。比如破坏环路等待条件,可以使用资源有序分配法,即确保线程获取的资源顺序一致,是比较常用的方法;除此之外还可以破坏不可剥夺条件,给锁添加超时属性,超时后自动释放锁,使用JUC的ReentrantLock类和tryLock方法就可以实现超时释放,还有ReentrantLock类的lockInterruptibly()方法可以实现可以被其他线程调用interrupt()方法中断的锁;如果想破坏请求与保持条件可以让线程在执行前一次性申请所有资源,如果某一资源无法获取则释放所有已获取的资源。
# 常用的linux命令有哪些?
- 回答:
- 我使用linux命令主要在文件操作、进程、网络和测试这几个方面。
- 在文件操作中我会使用ls命令列出目录内容参数-a查看详细信息、cd命令切换目录、mkdir创建目录;同时也可以使用rm命令删除文件或目录,cat+文件名来查看文件内容,tail -f +文件可以对文件进行动态监控。
- 对进程我会使用ps命令查看进程、top命令查看进程信息;
- 如果需要进行权限管理,我会使用chmod命令修改权限、chown命令修改所有者。
- 需要检查网络的时候会使用netstat命令查看网络状态、ifconfig命令查看网络接口信息,也会通过ping命令测试网络是否连通。
# 集合
# 常用的集合有哪些?
- 回答:
- Java中的集合框架包括Collection接口和Map接口。可以根据需求进行对应选择,如是否需要去重、排序和实现线程安全。
- Collection接口包括List和Set两个子接口,我常用ArrayList来存储经常访问的数据,因为它基于动态数组实现的,查询数据快;如果经常遇到插入和删除数据或者对首尾操作,那么我会使用LinkedList。面对需要去重的数据我会使用Set接口来完成,比如HashSet,LinkedHashSet和TreeSet,其中LinkedHashSet可以保留插入顺序,TreeSet则会按照自然顺序,可以根据需要进行选择。
- Map接口的特点是数据是以键值对的形式保存,键唯一而值可以重复。HashMap是比较常用的类,与Set类似,LinkedHashMap能够保留插入顺序,TreeMap可以按照自然顺序排序。但是他们都是线程不安全的,如果是多线程环境下需要考虑线程安全可以使用JUC包下的ConcurrentHashMap。
# 如果List里面放了整型数字,怎么排序?
- 回答:
- 如果进行升序排序,可以使用Collections.sort(list)方法,也可以使用list.sort()方法。如果需要降序排序,可以传入Collections.reverseOrder()参数,即list.sort(Comparator.reverseOrder())。
- 还可以通过自定义排序规则实现,即通过Comparator接口指定排序规则。
- 扩展:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class SortList {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(3);
numbers.add(1);
numbers.add(2);
// 方法1:使用Collections工具类
Collections.sort(numbers);
// 方法2:使用List自身的sort方法
// numbers.sort(null); // 参数为null时使用自然排序
// 方法3:匿名内部类
numbers.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// 降序:o2 - o1(升序为o1 - o2)
return o2 - o1;
}
});
// 方法4:Lambda表达式
numbers.sort((o1, o2) -> o2 - o1);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 在数据量很少的情况下维护数据,有没有索引有什么区别?
- 回答:
- 如果数据量很少,那么不需要设置索引,索引对查询的性能没有太大的提升,但是对索引的维护成本成为主要影响。
- 无索引的情况下,对于少量数据查询极快,修改时也可以直接操作数据,没有额外成本和空间占用。
- 有索引的情况下,查询数据前要读取索引结构并定位数据行,在更改数据时也有同步更新索引结构,和占用少量存储空间,可能会比无索引的速度慢。
# 什么情况下设置索引,有什么规则?
- 回答:
- 索引适合用在对字段有唯一性限制的情况、经常用于WHERE查询条件的字段和经常用于排序的字段。
- WHERE条件,ORDER BY和GROUP BY语句用不到的字段不用创建索引,因为查询时不会用到索引,也不会对查询性能有提升;大量重复的数据也不适合创建索引,因为查询结果仍有大量重复,无法有效利用索引提升速度;表格数据过少时使用索引会增加维护成本,对效率提升不明显;如果字段经常更新也不适合创建索引,因为索引字段也会随更新而频繁修改,导致性能下降。
# Redis
# Redis的持久化策略是什么?
- 回答:
- Redis持久化就是把内存中的数据写到磁盘中,防止服务宕机导致数据丢失。主要方式有RDB(内存快照)和AOF(日志文件),还有Redis4.0新增的AOF+RDB混合持久化方式。
- RDB(Redis Database)会按照一定时间间隔把内存的数据以快照方式保存到硬盘的二进制文件,可以通过save参数定义快照的周期。产生的数据文件是dump.rdb,可以执行save或bgsave命令进行保存。如果两次快照之间宕机,可能会造成一定的数据丢失。
- AOF(Append Only File)会将每一个收到的写命令写入AOF缓冲区(server.aof_buf)中,然后将缓存中的数据写入AOF文件并调用fsync()函数将数据写入磁盘appendonly.aof文件。如果Redis重启会重新执行文件中保存的写命令从而在内存中重建整个数据库的内容。如果日志文件较大,可能恢复速度比较慢。
- 使用混合持久化,AOF在重写时会把RDB的内容写到AOF开头,可以在快速加载的同时避免丢失过多数据。
# RDB的时候不向外提供服务吗?
- 回答:
- Redis提供了两个命令生成rdb快照,分别是save和bgsave。
- 如果使用的是save命令,那么会阻塞服务,无法对外提供服务。
- 如果使用bgsave命令,那么会通过fork()系统调用创建“子线程”,异步生成rdb快照,不会阻塞服务,可以对外提供服务。
# 缓存穿透、缓存击穿和缓存雪崩的区别?
- 回答:
- 缓存穿透是指大量查询不存在的数据,缓存中没有数据,数据库查询不到也不会写入缓存,每次请求都查数据库,导致数据库压力增大。
- 缓存击穿是指对于设置了过期时间的key,缓存过期的时候有大量并发请求,在数据库重新加载并写入缓存前,冲垮数据库。
- 缓存雪崩是指在同一时间段大量的缓存key同时失效或者Redis服务宕机,大量请求到达数据库导致数据库压力过大崩溃。
- 缓存穿透主要原因是查询不存在的数据,而缓存雪崩和缓存击穿则是数据不在缓存中,有大量并发请求导致数据库压力过大。
- 扩展:
- 解决缓存穿透
- 缓存空数据,避免反复请求数据库
- 使用布隆过滤器,在请求Redis之前使用布隆过滤器可以判断数据是否存在,如果不存在则直接返回。
- 解决缓存击穿
- 在缓存未命中时使用互斥锁,等到数据库查询到数据写入缓存后返回。
- 不给热点数据设置过期时间,在过期时更新缓存并重新设置过期时间。
- 解决缓存雪崩
- 给不同的key设置随机的过期时间(TTL)
- 搭建Redis高可用的服务,如哨兵或集群模式
- 使用服务熔断或请求限流的机制
- 解决缓存穿透
# springBoot
# 介绍一下springBoot的自动装配原理?
- SpringBoot的自动装配是基于Spring Framework的条件化配置和@EnableAutoConfiguration注解实现的,可以通过注解或少量配置就能在SpringBoot帮助下开启和配置各种功能。
- 在@EnableAutoConfiguration注解中,@AutoConfigurationPackage注解将项目src的main包下所有组件注册到容器中,@Import({AutoConfigurationImportSelector.class})是自动装配的核心。
- AutoConfigurationImportSelector类实现了ImportSelector接口,实现自动配置的选择和导入,能够分析项目的类路径和条件决定哪些自动配置类需要被导入。
# 实现单例模式的方法有哪些?
使用饿汉式:类加载时就创建实例,线程安全但可能导致资源浪费。
public class SingletonUtil { // 类加载时直接创建实例 private static final SingletonUtil INSTANCE = new SingletonUtil(); // 私有构造,防止外部实例化 private SingletonUtil() {} // 全局访问点 public static SingletonUtil getInstance() { return INSTANCE; } }1
2
3
4
5
6
7
8
9
10
11
12使用懒汉式:在第一次使用时才创建实例,线程不安全,但延迟加载,避免了资源浪费。如果想实现线程安全,可以使用 synchronized 关键字修饰 getInstance() 方法。
public class Singleton { private static Singleton instance; private Singleton (){} public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }1
2
3
4
5
6
7
8
9
10
11使用双重校验锁(DCL-Double Check Locking)也可以实现单例模式,能够在多线程环境下保证线程安全并具有高性能。由volatile和synchronized实现。
public class Singleton { private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
评论
验证登录状态...