# 大模型结构化输出:为什么自然语言不稳定,JSON Schema怎么约束

前段时间有个录友来找我复盘,他面了字节的大模型应用岗,简历项目里做了一套信息提取与入库系统。
他的系统在模型调用上做得相当不错 —— 选了该领域能力最强的模型,上下文给得够全,提取内容也基本准确。但面试官偏偏不问模型选型、不问数据量,直接奔着输出格式去了。
对话大致如下:
面试官:“你内容提取得准,那一入库就乱、解析失败,问题出在哪?”
他:“可能是我正则写得不够好……”
面试官:“我刚说了内容本身是准的。再想想。”
他:“我在Prompt里写了请输出JSON,不要加其他话……”
面试官:“那你靠什么保证它一定遵守?模型怎么知道必须按你定义的结构输出,不能自由发挥?”
他卡住了,支支吾吾说不清楚。
结构化输出是大模型工程化的第一道门槛,内容准不算赢,格式稳才能被程序真正用起来。今天我们来discuss一下为什么大模型越来越强调结构化输出。
# 一、先从一个真实场景说起
假设你做了一个AI应用,功能是:用户输入一段商品描述,模型帮你提取出"商品名称、价格、类别"三个字段,然后写入数据库。
你测试了几次,效果很好,模型总是输出这样的内容:
商品名称:无线蓝牙耳机
价格:299元
类别:电子产品
然后你写了一段代码来解析这个输出,用冒号分割,提取每一行的值,上线了。
结果两天后,业务同事反映数据库里一片乱。你去查日志,发现模型输出变成了这些:
这款商品是无线蓝牙耳机,售价299元,属于电子产品类别。
{"name": "无线蓝牙耳机", "price": "¥299", "category": "电子产品"}
名称:无线蓝牙耳机
价格:约299元
类别:3C/电子产品
这不是bug,这是大模型输出的本质特征:它是概率生成的,每次输出格式都可能不一样。
# 二、自然语言输出为什么不稳定?
理解这个问题,需要先建立一个基本认知:大模型输出的每一个token,本质上都是在做一次概率采样。
模型不是在"执行格式规则",它是在"预测什么词接下来最可能出现"。即便你在Prompt里写了"请输出JSON格式",模型也只是在学习"什么样的输出符合JSON这个描述",而不是真的在运行一个格式化函数。
这带来了几个实际问题:
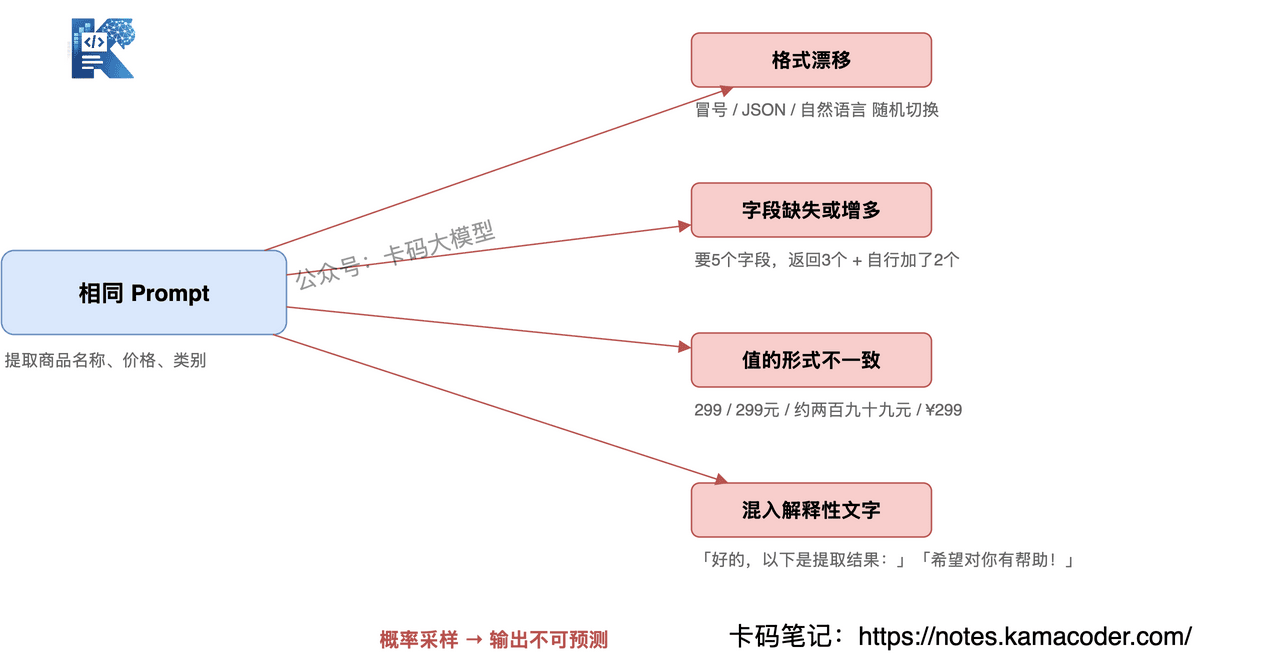
格式漂移: 同一个Prompt,不同调用之间,模型可能输出冒号格式、JSON格式、Markdown 列表格式,甚至是自然语言段落。
字段缺失或增多: 你让模型提取 5 个字段,它可能只返回 3 个,或者额外加了你没要的字段,还附上了一段"总结"。
值的形式不一致: 你要"价格",它可能返回 299、299元、约299元、¥299、 两百九十九元。
混入解释性文字: 模型喜欢在给出结构化内容之前或之后,加上"好的,以下是提取结果:"或者"希望这对你有帮助!"这类内容。
# 三、什么是结构化输出?
结构化输出,就是让模型按照你预先定义好的格式和字段生成内容,而不是自由发挥。
最常见的形式是让模型返回JSON,并且这个JSON的结构是固定的——哪些字段必须有,每个字段是什么类型,哪些是可选的,全部提前定义好。
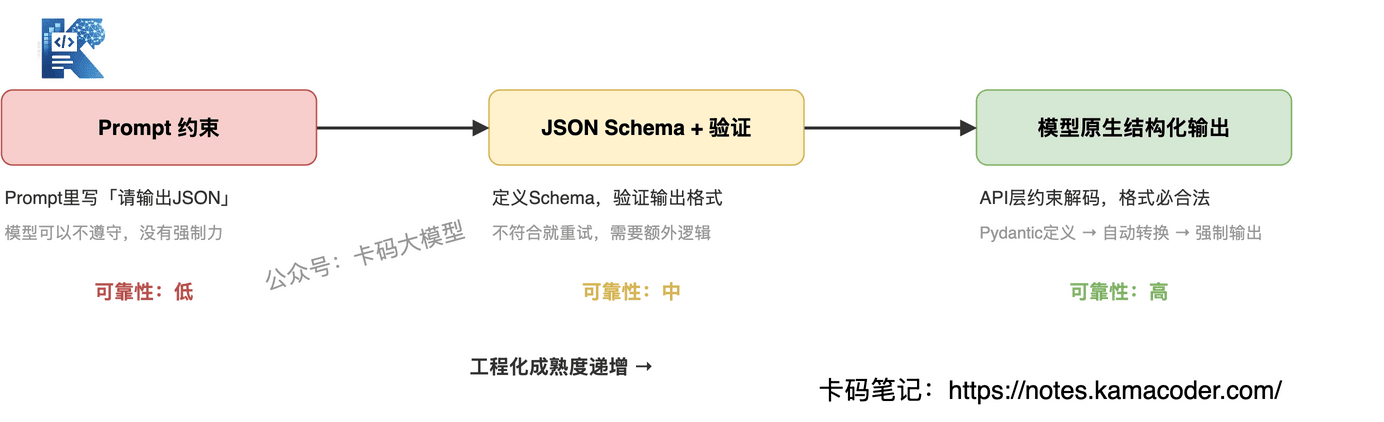
目前实现结构化输出主要有三种方式,难度和可靠性递增:
方式一:Prompt 约束(最简单,最不稳定)
在 Prompt 里写"请只输出 JSON,不要有任何其他文字",然后自己去解析输出。这个方式对简单场景勉强够用,但对于格式敏感的业务,失败率相当高。
方式二:JSON Schema + 输出验证
给模型提供一个JSON Schema(一种用于描述、验证和文档化JSON数据结构的标准化规范),告诉它输出的结构应该是什么样的,字段名是什么,类型是什么。收到输出后,用schema验证一遍,如果不符合就重试。这个方式可靠性明显提升,但需要处理重试逻辑。
方式三:模型原生结构化输出(最可靠)
OpenAI、Anthropic等主流模型API都支持 response_format 或 tool_use 参数,可以在API层面强制模型按照你给的schema输出,模型内部会做约束解码(constrained decoding),保证输出的JSON结构一定合法。这是目前工程上最推荐的方式。
在Python生态里,Pydantic是最常用的schema定义工具。你用Pydantic定义一个数据模型,框架(比如Instructor、LangChain)会自动把它转成JSON Schema传给模型,拿到输出后再自动反序列化成Python对象。整个过程对业务代码几乎透明。
# 四、结构化输出适合哪些业务场景?
不是所有业务都需要结构化输出,判断是否合适的标准很简单:你的下游逻辑,是否依赖模型输出的某个具体字段?
适合做结构化输出的典型场景:
信息提取类任务,比如从合同文本里提取甲方、乙方、金额、签署日期,写入 CRM 系统。输出必须是固定字段,不能是一段话。
内容生成后的元数据附加,比如生成一篇文章的同时,要求模型一并输出文章的标题、摘要、关键词列表、预计阅读时间,这些字段需要分别存储和使用。
不太适合的场景:纯粹的对话、内容创作等输出本身就是给人看的,不需要程序进一步处理。
# 五、面试可能怎么问
Q:为什么要做结构化输出?
参考思路:大模型的输出是概率生成的,格式存在随机漂移,不做约束就无法被下游程序可靠地消费。结构化输出通过schema 定义+ 约束解码,把"自然语言"变成"机器可读的数据结构",是大模型应用工程化的基础能力之一。
Q:你们项目里输出不稳定怎么处理的?
参考思路:分三个层次回答。第一层是 Prompt 层,明确要求输出格式;第二层是API层,使用 response_format做强约束;第三层是业务层,拿到输出后做 schema 验证,不通过则重试(通常重试 2-3 次),同时记录失败日志用于迭代Prompt。
# 六、结语
自然语言输出的不稳定,是大模型从demo走向生产最先遇到的工程挑战之一。结构化输出不是什么高级技巧,而是让模型输出可以被代码消化的基本前提。
评论
验证登录状态...