# 为什么有了大模型还需要RAG?幻觉、私有知识、时效性四大问题
常看公众号文章的朋友们肯定知道,我们在之前几篇推文已经建立了应用开发的基础认知。从这篇开始,我们进入一个具体的系统方向——大模型主要落地项目之一、面试里最频繁被问到的 RAG。
# 一、从一个真实的困境说起
假设你们公司有几千份内部文档:产品手册、操作规范、历史项目经验、客户合同……领导想做一个 AI 问答系统,让员工随时可以问"我们的退款政策是什么"、"这个客户签了哪些条款",系统能直接给出准确答案。
你直接用大模型来做,第一轮测试效果还不错——但很快发现几个绕不开的问题:
- 模型对公司内部文档一无所知,回答全靠"编"
- 产品文档上周刚更新,但模型说的还是老版本的内容
- 模型回答的很流畅,但根本无法知道它说的是真是假,也无法追溯来源
- 文档加载到 Prompt 里,token 成本高到无法接受
这不是模型能力不够的问题,而是大模型作为一种技术,有几个根本性的天花板——而 RAG 就是为了突破这些天花板而诞生的。
# 二、大模型的局限性
要理解 RAG,必须先想清楚大模型到底有哪些内生局限。
下面这张图展示了纯大模型在知识层面存在的几个边界:
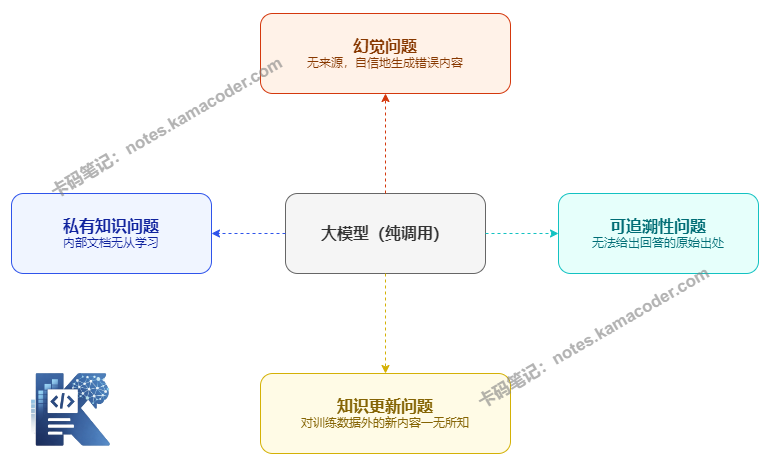
# 1. 幻觉问题(Hallucination)
大模型的本质是一个概率语言模型,它在生成每个 token 时做的是"预测下一个最可能的词",而不是"从知识库里查询正确答案"。
这意味着当它不知道答案时,它不会说"我不知道"——它会生成一个"听起来最合理"的答案。这个答案可能完全是捏造的,但语气坚定、格式工整,让人难以判断真假。
在企业场景里,幻觉的危害远比"回答错误"更严重——它会以可信的方式传播错误信息,而用户毫不知情。
# 2. 私有知识问题
大模型是在公开数据上训练的。你们公司的内部文档、客户合同、产品手册、会议记录,这些内容它从未见过,也不可能知道。
有人会想:那把文档全部放进 Prompt 里呢?对于少量文档这是可行的,但当文档量达到几百份、几千份时,token 成本和上下文长度都会成为瓶颈。而且模型在极长上下文里的注意力会严重稀释,对中间内容的利用率极低。
# 3. 知识更新问题
模型的训练是有截止日期的,通常落后现实 6 个月到一年。产品价格变了、政策修订了、新的竞争对手出现了——这些模型全不知道。
你不可能每隔几个月就重新训练一遍模型来"更新知识",这在成本和时间上都不可接受。
# 4. 可追溯性问题
当模型给出一个答案时,它无法告诉你"这句话来自哪份文档的第几页"。对于法律、医疗、金融等对准确性要求极高的场景,没有来源引用的答案往往是不可接受的。
# 三、RAG 是怎么应对大模型的缺点的?
RAG 的全称是 Retrieval-Augmented Generation,检索增强生成。它的核心思路非常直觉:在让模型回答之前,先去知识库里检索出最相关的内容,把这些内容作为上下文一起喂给模型,让模型"看着资料"来回答。
下面这张图展示了 RAG 如何对应地解决上面四个问题:
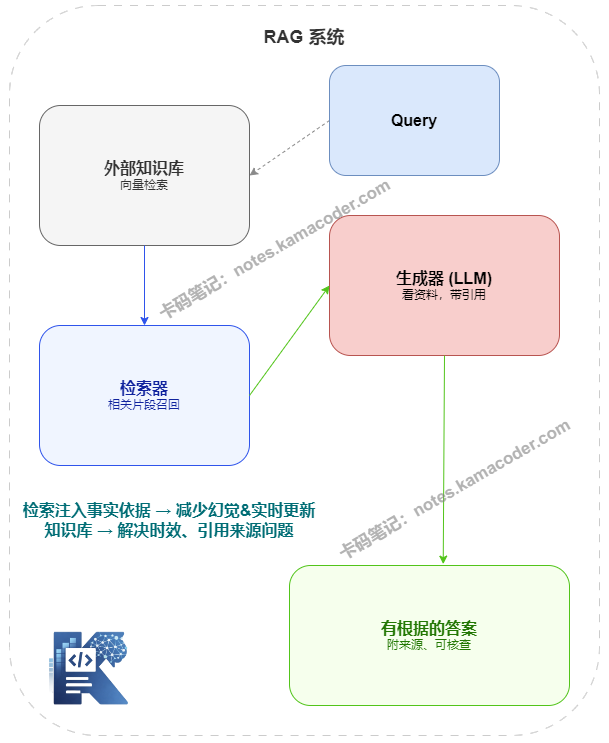
RAG 针对四个问题各有应对:
对幻觉问题: 检索到的原文片段作为上下文传入模型,模型被要求"根据以下资料回答",而不是凭空生成。有了事实依据的约束,幻觉概率大幅降低——但注意,不是归零,这个后面会讲。
对私有知识问题: 知识库完全由你自己构建和维护,可以包含任何内部文档。模型不需要知道这些内容,只需要在被检索到的片段基础上进行推理和组织语言。
对知识更新问题: 更新知识库不需要重新训练模型,只需要更新文档、重新做向量化索引即可。知识的新鲜度完全由知识库决定,和模型训练截止日期解耦。
对可追溯性问题: 每次检索都能知道具体命中了哪份文档的哪个片段,可以在答案里附上引用来源,用户可以自行核查。
# 四、RAG 不是万能的:什么场景适合,什么场景不适合
很多人看到 RAG 的思路后,产生了一个误区:是不是所有大模型应用都应该加 RAG?不是的。
适合 RAG 的场景:
知识密集型的问答系统,比如企业内部知识库、产品手册问答、法律法规查询——这类场景对事实准确性要求高,内容量大,且需要明确的来源追溯。
内容频繁更新的业务,比如新闻摘要、竞品分析、政策解读——这类场景下知识库可以持续接入实时数据,而模型本身不需要动。
长尾事实查询,比如"我们公司在上海的办公地址是什么""这个合同的甲方是谁"——这类问题的答案藏在特定文档里,必须检索才能找到。
# 五、面试可能怎么问
Q:为什么有了大模型还需要 RAG?
参考思路:大模型有几个局限性——幻觉、私有知识盲区、知识时效性、无法溯源。RAG 通过在回答前先检索外部知识库,把相关文档片段注入上下文,让模型"看资料回答",从而有针对性地缓解以上问题。
Q:RAG 能解决幻觉问题吗?
参考思路:能显著缓解,但无法根治。有了检索到的事实作为锚点,模型乱编的概率大幅降低,且答案可以附上来源供核查。但模型仍然可能在检索结果上做出错误推理,或者在检索质量差时进行"补充生成"。RAG 降低幻觉概率,不消灭幻觉根因。
Q:什么场景下你会推荐用 RAG,什么场景下不用?
参考思路:适合 RAG 的是知识密集、内容频繁更新、需要溯源的场景,比如企业知识库问答、法规查询。不适合的是创意生成、强推理任务、以及模型训练数据已良好覆盖的稳定领域——在这些场景下,RAG 只是增加延迟和成本,没有实质收益。
# 六、结语
RAG 不是大模型能力的升级,而是大模型的外置数据库——让模型在回答时能检索自己的cheat sheet,从而有据可依。
评论
验证登录状态...