# 用上Claude之后,只发了一句「你好」,为什么消耗了十万 token?一篇讲清你的 token 到底花哪了
最近这两天 Claude 疯癫,开始大封号。
我的号也被封了,所有就转头走API的方式用 opus4.8 。
大家平时如果是用 Claude pro会员,可能对 token消耗没概念。
但是一旦用上了API调用,你对token消耗就会敏感了,毕竟token画的越多,钱就哗哗的。
估计很多读者,当你用Claude Code打开你的一个项目要开始大干特干,第一句话礼貌性地发了个「你好」。
结果一看后台账单,傻眼了。
我特别给大家做一个测试,
使用 Claude Opus 4.8 ,在我的卡码笔记项目里输入一个:“你好”。
在后台看一下 计费:
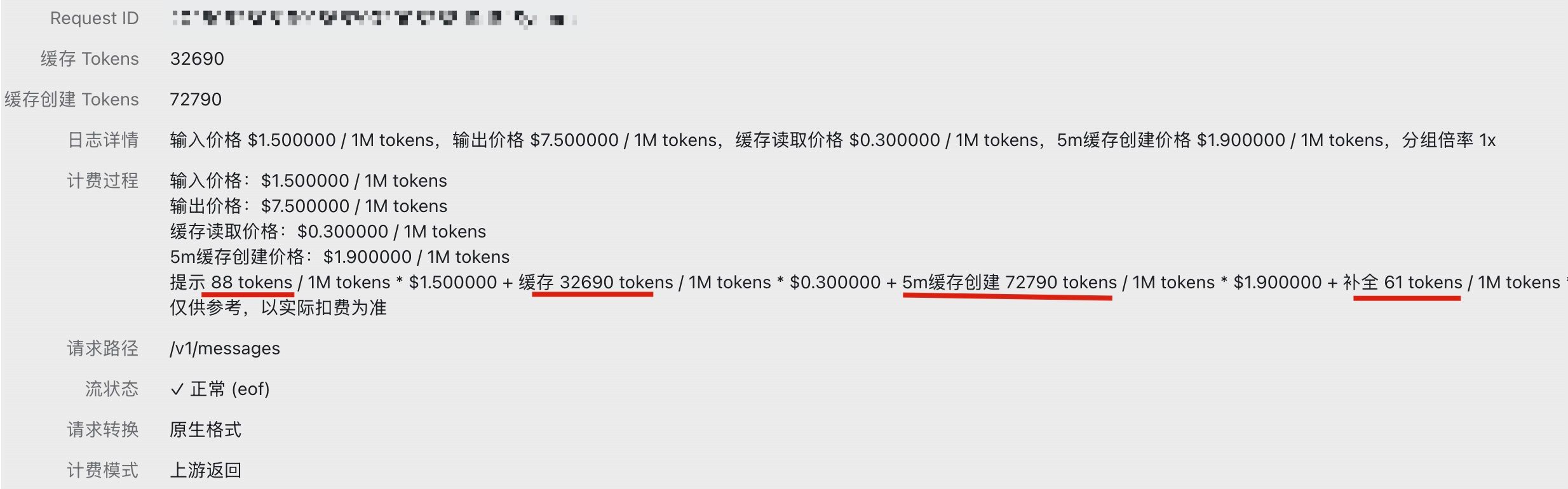
(这个计费截图是 apidock.ai (opens new window) 的后端截图)
- 输入 token:88
- 缓存读:32690
- 缓存创建:72790
- 输入 token:61
加起来十万出头。
就一句「你好」啊。两个字。
第一反应往往是:是不是被坑了?是不是哪里算错了?
接下来,看看这十万 token 到底花在哪,一笔一笔讲清楚。
用不了Claude opus 4.8的录友,可以试试 apidock.ai (opens new window) ,我目前用的是这个,比较稳定
# 一、模型没有记忆
很多人对 AI 的想象是这样的:它记得我们刚才聊了什么,我发新的一句,它接着上文回我就行。
错。大模型本身是没有记忆的。
它不是一个一直在线、记着你的助理。它更像一个每次都失忆的专家——你每问一次,它就被叫醒一次,回答完立刻忘光。
那它怎么能接着上文聊?
靠的是:每一轮请求,都把前面所有该知道的东西,重新完整地发给它一遍。
你以为你只发了「你好」。
实际上发过去的,是「一大坨它必须先读完才能干活的上下文」 + 你那句「你好」。
那句你好确实只值几十个 token(就是后台那个 88 和 61)。剩下十万,全是你看不见的那一大坨。
# 二、那一大坨到底是什么?
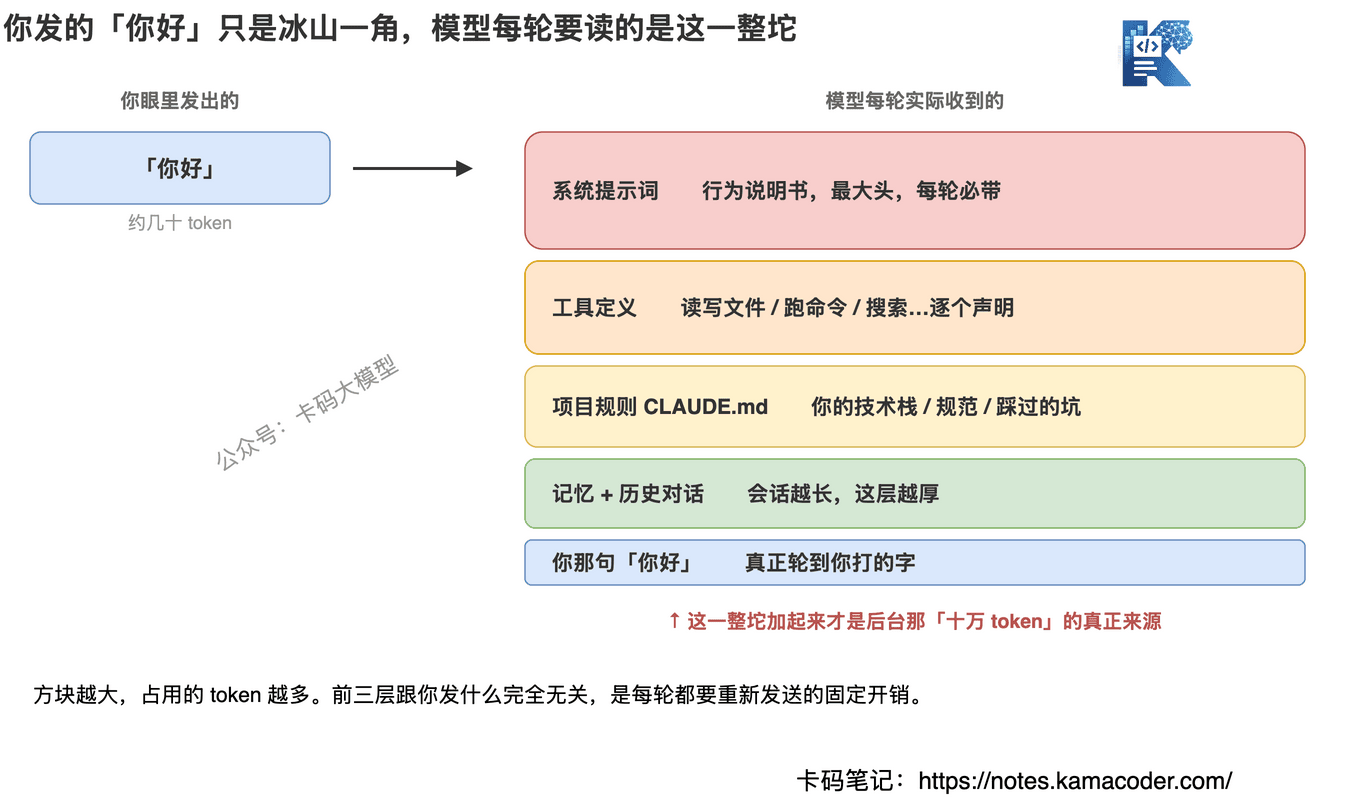
我们把一次请求拆开看。模型每轮实际收到的内容,大致分这么几层:
第一层:系统提示词(最大的一块)
这是工具厂商预先写好、塞在每次请求最前面的「行为说明书」:你是谁、你能干什么、安全规范、回答风格、怎么用工具……
Claude Code 这类 Agent 工具的系统提示词非常长,因为它要把一整套工作规则讲清楚。这部分跟你发什么完全无关,每轮都带,雷打不动。
之前在聊 fable5时候,也聊过 Claude Fable 5被破解了?12万字系统提示词全曝光 (opens new window)
用堆提示词的方法,造不出来一个好用的Agent,但一个好用的Agent,一定有海量提示词。
第二层:工具定义
Claude Code 能读文件、改文件、跑命令、搜索代码、调 MCP……这十几个工具,每一个都要用一段结构化的 JSON 告诉模型「这个工具叫什么、接收什么参数、什么时候用」。
工具越多,这段越长。这也是为什么后面我们会说,工具不能随便乱加。
第三层:项目规则文件(CLAUDE.md 这类)
如果你在一个项目里用 Claude Code,它每次开会话都会先读项目根目录的 CLAUDE.md——你的技术栈、代码规范、踩过的坑、常用命令,全在里面。
这文件写得越详细,越「贴合你的项目」,但也越占 token。它是个双刃剑,后面讲怎么平衡。怎么把它写得管用又不臃肿,我们专门写过一篇:CLAUDE.md 到底怎么写。
而且用来做测试的这个项目,目录本来就有比较长的CALUDE.md ,里面写了——仓库概述、画图规范、drawio 样式、文章风格、简历四要素…… 全文每次都会加载进来,这样Claude才知道这个项目的规矩。
这一项就贡献了好几千 token。
第四层:记忆和历史对话
跨会话的自动记忆、本轮之前已经聊过的内容,也都要重新发一遍。
会话越长,这层越厚——你聊到第 20 轮时,前 19 轮的内容每一轮都还在被重新发送。
第五层:你那句「你好」
到这才轮到你真正打的字。几十个 token。
把这五层叠起来你就明白了:「你好」是露在水面上的冰山一角,水面下那一大坨系统提示词、工具定义、项目规则,才是十万 token 的真正来源。
# 三、再来看那四个数字:输入、缓存创建、缓存读
拆完构成,回头看后台那几个名词就不懵了。
为什么同样是「发给模型的内容」,却分成了输入、缓存创建、缓存读三种?
因为厂商发现了一个规律:每轮请求里那一大坨(系统提示词、工具定义、项目规则)几乎是一模一样的。 每轮都让模型从头重新计算一遍,太浪费了。
于是有了 Prompt Cache(提示词缓存):把这些稳定不变的内容,第一次算完就缓存下来,下一轮直接复用,不用重算。
对应到那四个数字:
| 名词 | 是什么 | 价格 |
|---|---|---|
| 输入 token | 没走缓存的普通输入(比如你新打的「你好」) | 标准价 |
| 缓存创建 | 第一次把那一大坨写进缓存 | 比标准价贵一点(约 1.25 倍) |
| 缓存读 | 从缓存里直接读取,不用重算 | 比标准价便宜约 5-10 倍 |
所以你那组数据翻译过来就是:
- 缓存创建 72790:第一轮,把系统提示词、工具定义、CLAUDE.md 这一大坨第一次写进缓存。这是一次性的「建仓」动作,单价略贵。
- 缓存读 32690:有一部分上下文已经在缓存里了,直接读,便宜得多。
- 输入 88 / 61:你真正新增的内容,包括那句「你好」。
关键在于:缓存创建是「贵但只发生一次」,缓存读是「便宜且反复发生」。
Prompt Cache 缓存的不是你的答案,而是模型处理上下文时的中间计算。这背后还有一整套工程设计——为什么系统提示词不能随便改、工具不能随便加,都是为了不破坏缓存。想深挖的录友看这篇:Claude Code 为什么快?Prompt Cache 一篇讲明白。
# 四、这钱花得冤吗?
不冤。而且恰恰相反——这是在帮你省钱。
我们做个对比。
假设那十万 token 全部按「标准输入价」算,那才是真的贵。但实际上:
- 占大头的那部分走了「缓存读」,便宜五到十倍;
- 「缓存创建」虽然略贵,但只在第一轮发生一次。
更关键的是看趋势。别只盯着第一句「你好」。
- 第 1 轮:大量缓存创建(建仓,看着贵)
- 第 2 轮:那一大坨基本都命中缓存,转为缓存读(便宜)
- 第 3 轮、第 4 轮……:持续走缓存读
第一轮的「贵」,是给整个会话铺路。后面每一轮都在吃第一轮建好的缓存红利。 你聊得越久,这笔一次性开销摊得越薄。
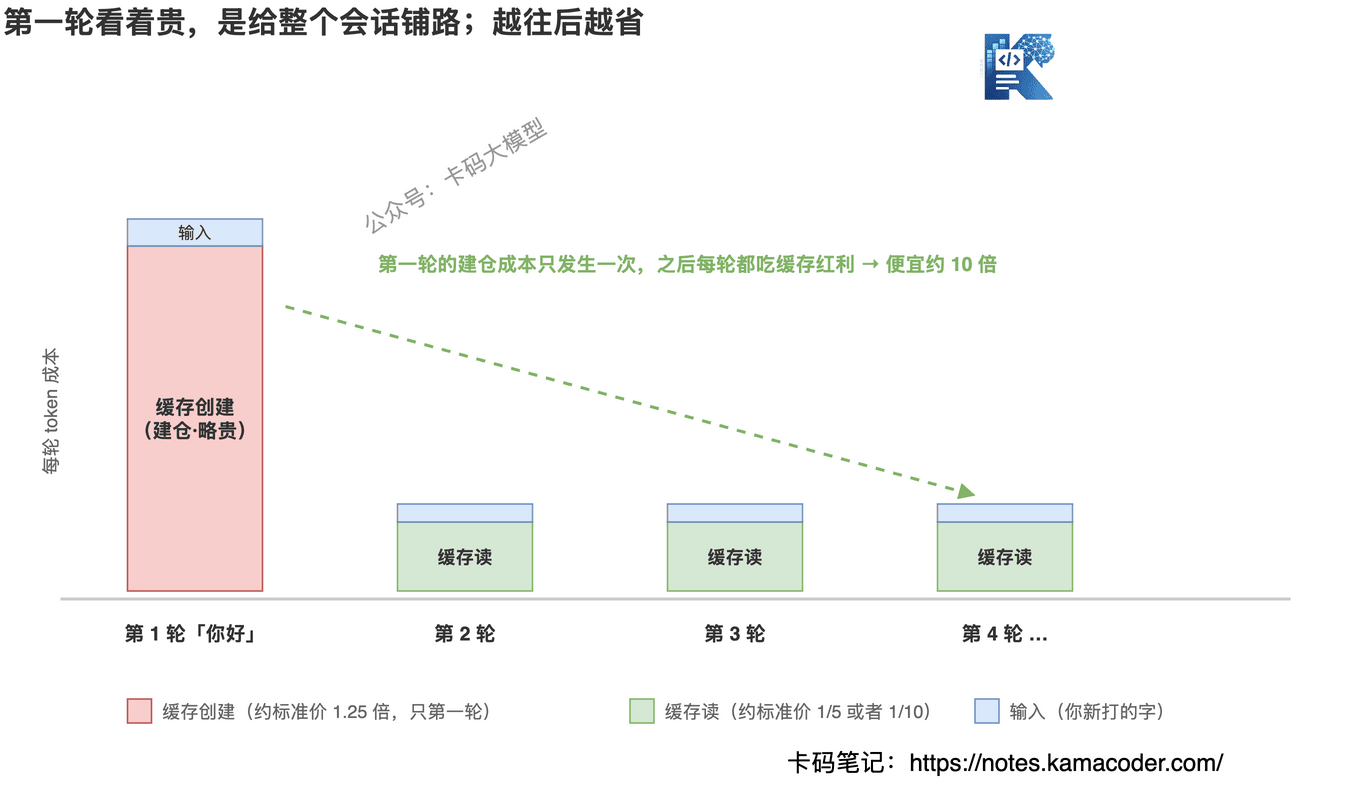
所以「发一句你好花十万 token」这个现象,本质是:
你不是在为「你好」付费,你是在为「让模型具备给你干活的完整能力」付一次性的铺垫费。 而缓存机制,已经在尽力帮你把这笔费用压到最低了。
# 五、那还能再省吗?能
知道了钱花哪,省钱的方向就清楚了——盯着那一大坨「固定开销」里你能控制的部分。
1. 精简 CLAUDE.md
系统提示词和工具定义你改不了,但 CLAUDE.md 是自己的。
其实我这个项目的 CLAUDE.md 确实应该精简一下了。
而且还有很多人把它写成了一本几千字的百科全书,每轮都全量加载。
该拆的拆成 Skill(按需加载、平时不占上下文),该删的删。
2. 别动不动开新会话
每开一个新会话,那一大坨就要重新「缓存创建」一次(走贵的那档)。在同一个会话里把相关的事一次做完,比反复新建会话划算得多。
3. 长任务比碎问题划算
既然第一轮的建仓成本是固定的,那把它摊到一个能干很多活的长会话里,平均每件事的成本就低。反过来,开个会话只问一句就关,那笔建仓费就白花了。
所以,大家不要在Claude code 的Agent里 做日常提问(今天天气怎么样、肚子疼了吃点啥、程序员如何学习大模型等等),这些日常提问去 web端提问就好。
因为你在项目目录里提问日常内容,每次都要加载项目目录,这和日常问题 没关系。
4. 注意上下文别无限膨胀
会话太长,历史对话那层会越堆越厚。Claude Code 有上下文自动压缩,必要时也可以主动开新会话——这是另一个权衡,具体怎么管理上下文,可以看Claude上线文管理。
# 最后
下次再看到「发一句你好消耗十万 token」,你应该能秒懂了:
那十万里,绝大部分是系统提示词、工具定义、项目规则这些你看不见、但模型每轮都得读的上下文;「你好」本身只值几十个。而其中大头走的是便宜五到十倍的缓存读,贵的缓存创建只发生一次。
不是被坑,是机制。看懂了,你才知道怎么用得更省。
评论
验证登录状态...