# Claude Code 为什么快?Prompt Cache、Plan Mode、MCP工具加载和上下文压缩一篇讲明白
录友们好,今天继续聊 Claude Code。
前面我们写过两篇:
CLAUDE.md到底怎么写,讲的是项目规则、团队规范、上下文管理怎么沉淀。
Claude Code怎么读懂大代码库,讲的是大代码库里 Claude Code 怎么靠 Agentic Search、Hooks、Skills、MCP、LSP 这些工程支架跑起来。
今天这篇,继续往底层挖一层。
Anthropic 在 2026 年 4 月 30 日发了一篇博客:Lessons from building Claude Code: Prompt caching is everything:https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything
这篇文章看标题像是在讲“缓存优化”。
但如果你真这么理解,那就浅了。
它真正讲的是:
一个长期运行的 Agent 产品,不能把 Prompt Cache 当成后期优化,而要从第一天就围着缓存设计。
Claude Code 为什么能在一个长会话里反复读代码、调用工具、跑命令,还不至于每一轮都慢到离谱、贵到离谱?
核心就是 Prompt Cache。
不是普通意义上的“把结果缓存起来”。
而是把每次请求里稳定不变的前缀缓存起来,让下一轮请求不用重新计算前面那一大坨上下文。
这件事听起来简单。
不少读者问我,如何充值Claude会员,我在这里篇单独讲一下:国内Claude充值会员的方法
但 Anthropic 这篇文章最有价值的地方在于,它把几个反直觉的工程结论讲出来了:
- 系统提示词不能随便动
- 工具定义不能随便增删
- Plan Mode 不能靠换工具集实现
- MCP 工具多了不能靠动态删工具省 token
- 模型中途切换可能反而更贵
- 上下文压缩也要复用父会话缓存
这些不是细枝末节。
这些决定了一个 Agent 产品到底是“能演示”,还是“能长期用”。
# 一、先搞清楚:Prompt Cache 缓存的不是答案
很多录友一听缓存,第一反应是:
是不是用户问过的问题,下次直接把答案拿出来?
不是。
Prompt Cache 缓存的不是模型回答。
它缓存的是模型处理输入上下文时的中间计算。
你可以这么理解。
Claude Code 每一轮跟模型交互,并不是只把你刚输入的那句话发过去。
它要把一整套东西重新发给模型:
- 系统提示词
- 工具定义
- CLAUDE.md 里的项目规则
- 当前项目上下文
- 前面所有对话消息
- 工具调用结果
- 你这一轮的新输入
模型本身并不会在两次 API 请求之间“记住”上一次聊到哪了。
所以每一轮请求都要带上完整上下文。
如果没有缓存,那长会话越聊越贵,越聊越慢。
这也是为什么很多 Agent demo 一开始看起来很丝滑,但跑一会儿就开始变慢。
它不是突然变笨了。
是上下文越来越长,每次都在重算。
Prompt Cache 解决的就是这个问题:
前面已经算过、下一轮又完全一样的部分,就不要再算一遍。
但这里有一个关键限制。
它靠的是前缀匹配。
不是“这段内容大概一样”。
也不是“这个文件之前读过”。
而是从请求开头开始,连续一段内容必须一致,才能命中缓存。
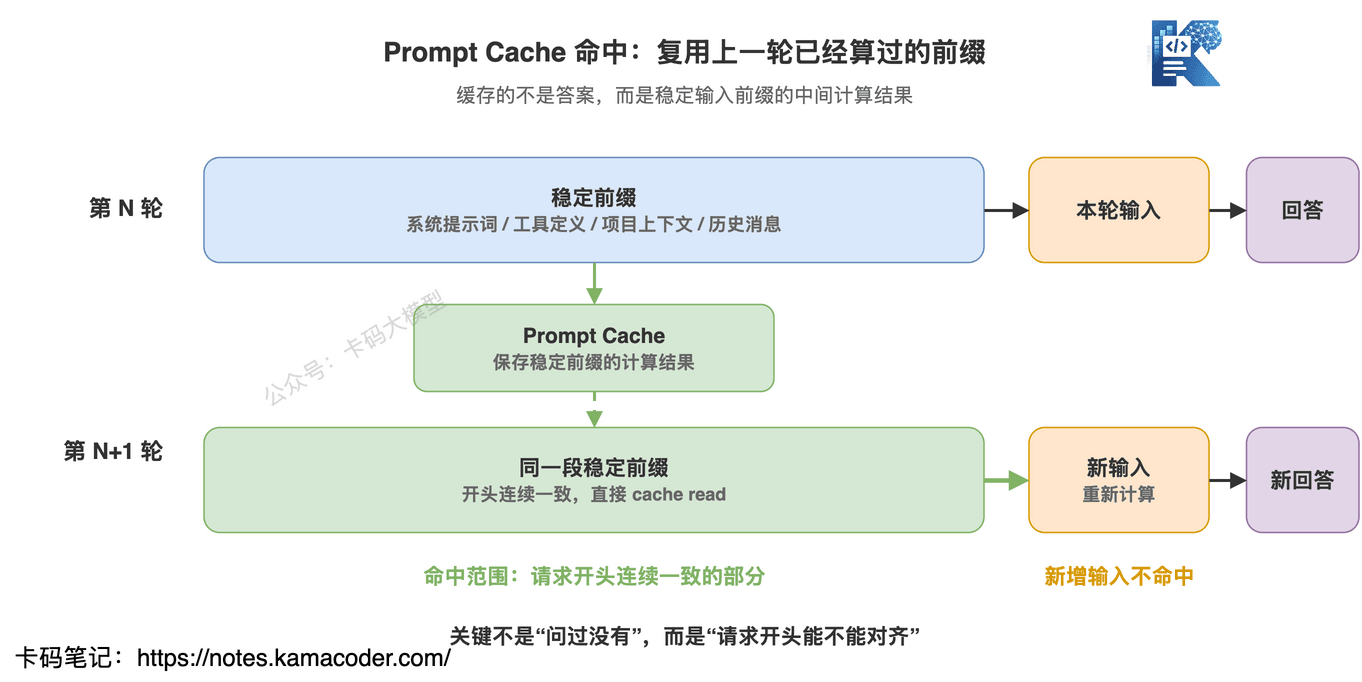
所以 Claude Code 的请求组织方式很讲究:
第一层,静态系统提示词和工具定义。
这部分最好全局稳定,不同项目都能复用。
第二层,CLAUDE.md 和项目上下文。
这部分在同一个项目里稳定。
第三层,会话上下文。
这部分在同一个会话里稳定。
第四层,对话消息和工具结果。
这部分会随着聊天增长。
第五层,本轮新增输入。
每一轮只让最后一点点内容变化。
这样前面大部分内容都能命中缓存。
静态内容放前面,动态内容放后面。
这是做 Agent 产品时最朴素、也最容易被忽略的缓存原则。
# 二、为什么“改一个小东西”也会让缓存断掉?
Prompt Cache 最反直觉的地方在这里。
很多人觉得:
我只是改了一下系统提示词里的时间。
我只是调整了一下工具顺序。
我只是把某个工具参数更新了一下。
应该没什么大问题吧?
有问题。
因为它会让前缀发生变化。
前缀一变,后面的缓存就接不上。
Anthropic 在原文里提到,他们也踩过类似坑:比如把详细时间戳放进静态系统提示词、工具定义顺序不是确定的、更新工具参数等。
这些变化看着都不大。
但从缓存角度看,都是前缀污染。
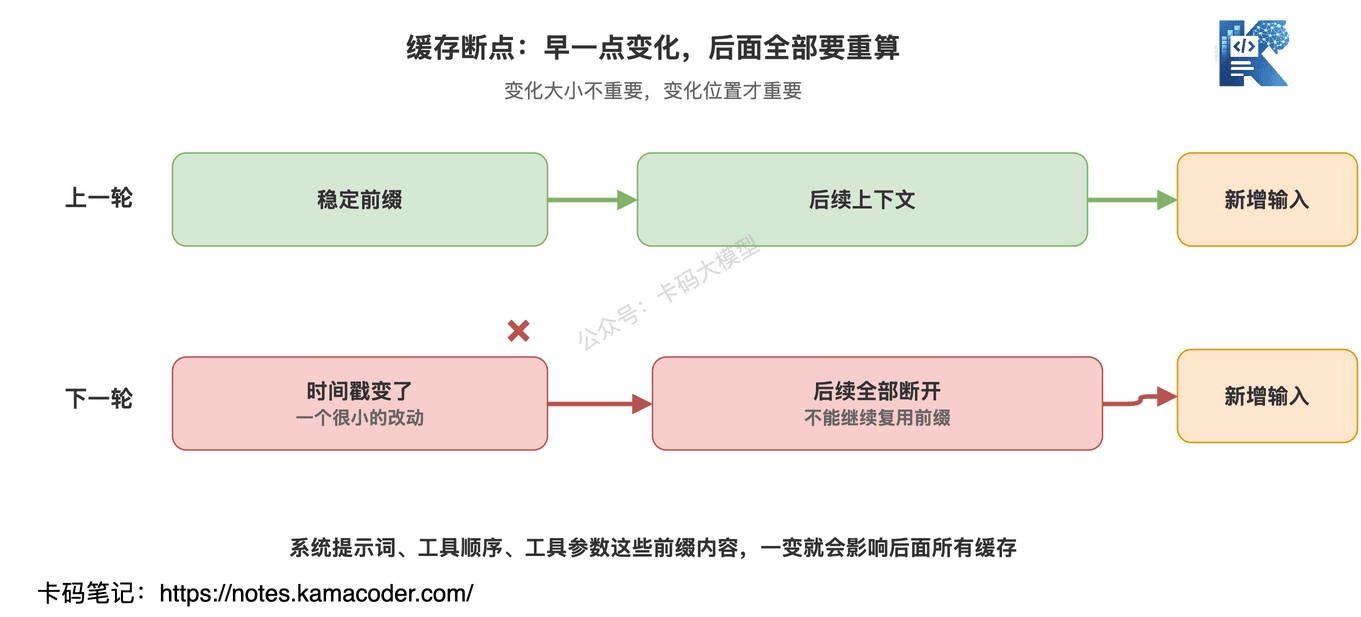
这就像你在一个大项目里改构建缓存 key。
你可能只改了一行配置。
但缓存系统看到的是:
不一样了。
那就重新构建。
对 Agent 也是一样。
如果系统提示词每轮都带一个实时日期,或者工具定义每轮顺序都不稳定,那缓存命中率就会很难看。
所以做 Agent 不能只问:
这段 Prompt 对模型有没有帮助?
还要问:
这段内容是不是应该出现在稳定前缀里?
如果它每轮都变,那就别放前面。
放到消息里。
# 三、动态信息别改系统提示词,放进消息里
Agent 运行过程中,确实会遇到很多动态信息。
比如:
- 当前时间变了
- 用户改了文件
- 权限状态变了
- 进入了某种工作模式
- 某个工具结果需要提醒模型
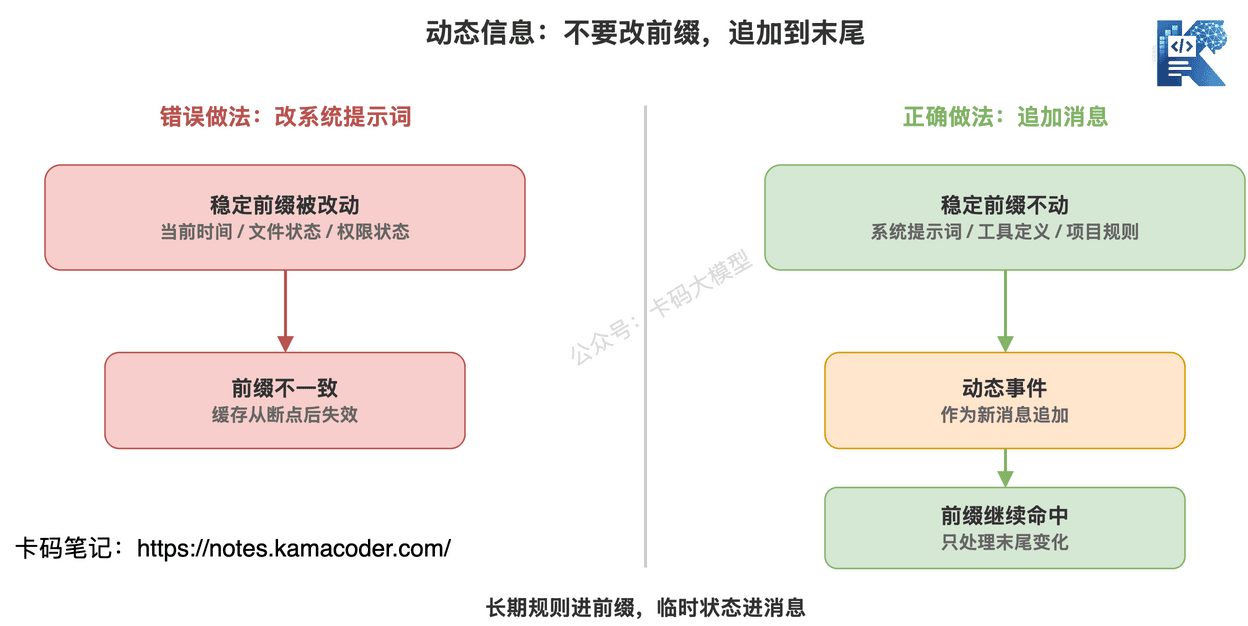
直觉上,你可能想更新系统提示词。
比如把“当前时间是 2026 年 5 月 28 日”写进系统提示词。
或者用户改了文件,就把“某文件已修改”更新到项目上下文里。
这在功能上没问题。
但在缓存上很差。
因为系统提示词和项目上下文都在前面。
你一改,后面全断。
Claude Code 的做法更聪明:
动态信息尽量通过下一轮消息追加进去,而不是修改前面的稳定前缀。
例如文件变化,可以在下一条用户消息或工具结果里追加一个系统提醒,告诉模型“这个文件已经变了,需要时重新读取”。
这样做的好处是:
前面的系统提示词、工具定义、CLAUDE.md 都不动。
只是末尾多了一条新消息。
缓存还能继续命中。
这也是为什么我们前面讲 CLAUDE.md 时反复强调:
CLAUDE.md 适合放长期稳定规则。
不要把一次性任务、临时状态、当前进度都塞进去。
长期规则进 CLAUDE.md,临时变化进消息。
这个分流,不只是为了上下文清爽。
也是为了缓存稳定。
# 四、不要中途切模型,可能更贵
这点也很反直觉。
很多人会想:
复杂问题用强模型。
简单问题切便宜模型。
听起来很合理。
但在长会话里,不一定省钱。
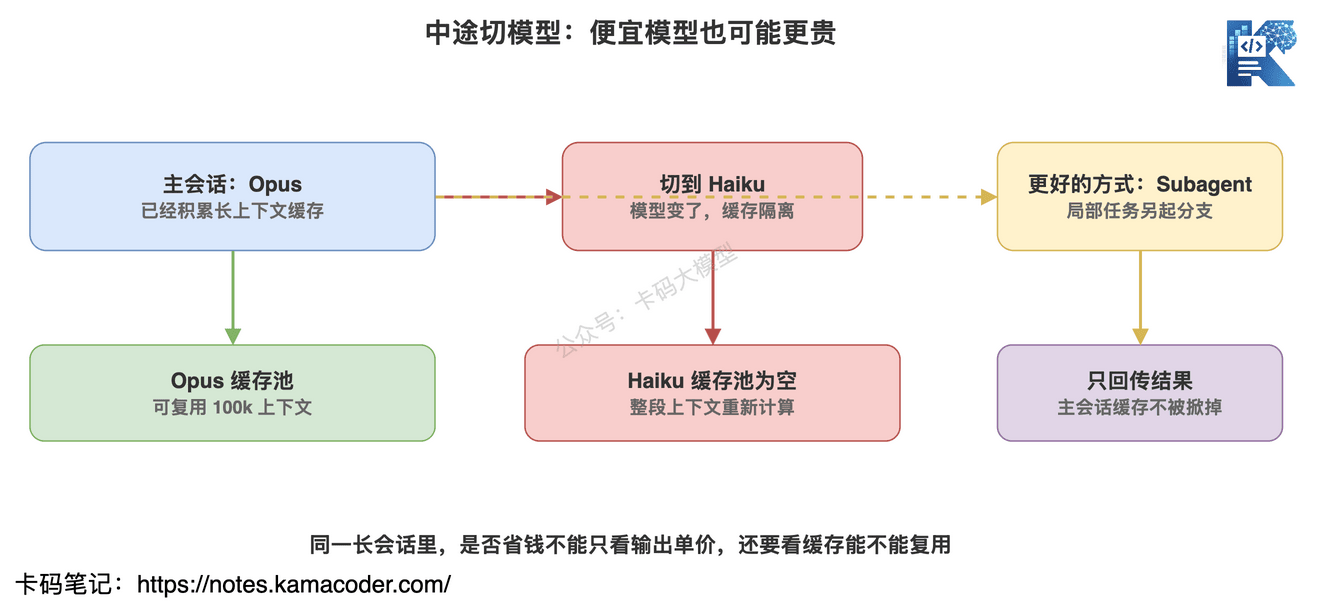
因为 Prompt Cache 是按模型隔离的。
你在 Opus 里聊了 100k token,上下文已经缓存好了。
这时候你觉得下一个问题很简单,切到 Haiku。
从单次输出价格看,Haiku 便宜。
但 Haiku 没有 Opus 的缓存。
它要重新处理整段上下文。
这就可能出现一个很尴尬的情况:
为了省一点输出成本,反而付出一大笔未缓存输入成本。
所以 Anthropic 的建议是:不要在同一个长会话中随便换模型。
如果确实需要换模型,更好的方式是用 subagent。
主会话继续保持自己的模型和缓存。
子 Agent 用另一个模型处理局部任务。
然后把结果返回给主会话。
这其实又回到一个原则:
不要破坏主会话的稳定前缀。
主会话是主干。
子 Agent 是分支。
分支可以另起缓存。
但不要让主干为了一个小任务把整个缓存掀掉。
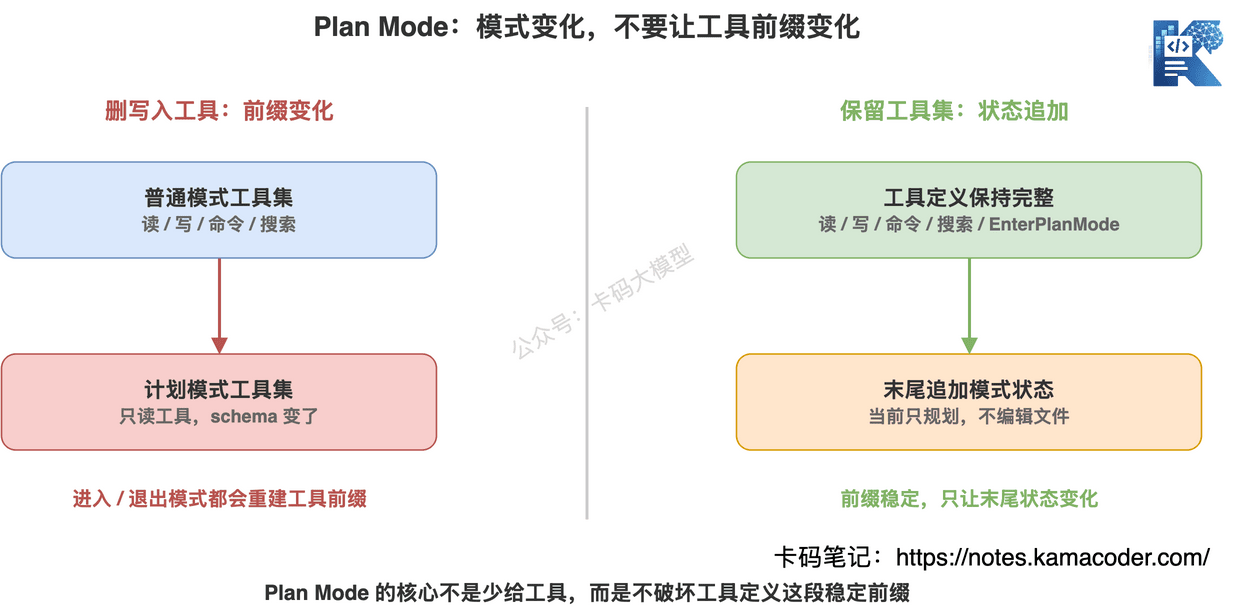
# 五、Plan Mode 为什么不能靠“删掉写入工具”实现?
Claude Code 的 Plan Mode,录友应该不陌生。
进入 Plan Mode 之后,Claude Code 会先读代码、分析问题、给计划,不直接改文件。
很多人如果自己设计这个功能,第一反应大概是:
计划模式只保留只读工具。
编辑工具、写文件工具、执行危险命令的工具都先移除。
听起来很安全。
但这会破坏缓存。
因为工具定义是前缀的一部分。
你一进入 Plan Mode,就把工具集合换了。
退出 Plan Mode,又换回来。
每次模式切换都在动前缀。
这就很亏。
Claude Code 的设计更有意思。
它不是通过“换工具集合”来表达 Plan Mode。
而是始终保留完整工具集。
同时把 EnterPlanMode 和 ExitPlanMode 也设计成工具。
当用户进入 Plan Mode 时,系统在消息末尾追加说明:
当前处于计划模式,要探索代码库,不要编辑文件,计划完成后调用退出计划模式。
注意重点:
工具定义没变。
变化发生在对话末尾。
所以缓存前缀还能命中。
这就是工程产品和普通 demo 的差别。
普通 demo 可能只关心“功能能不能实现”。
Claude Code 这种产品还要关心:
这个功能会不会让每一次模式切换都变贵、变慢?
更妙的是,因为 EnterPlanMode 本身也是工具,模型在遇到复杂任务时,还可以自己判断进入计划模式。
功能更灵活。
缓存也没被破坏。
# 六、MCP 工具多了,不能每轮动态删工具
现在大家做 Agent,很容易接一堆 MCP。
GitHub 一个。
数据库一个。
浏览器一个。
文件系统一个。
内部平台再接几个。
工具越来越多。
然后就会遇到一个问题:
每次请求都把几十个工具的完整 schema 发给模型,太贵了。
那怎么办?
很多人的第一反应是:
本轮用不到的工具就删掉。
比如这轮只需要读文件,那数据库工具、浏览器工具都先不发。
听起来省 token。
但这又踩中了缓存雷区。
因为工具集合变了。
工具定义顺序变了。
缓存前缀就变了。
所以 Claude Code 的思路不是“动态删工具”,而是“延迟加载工具详情”。
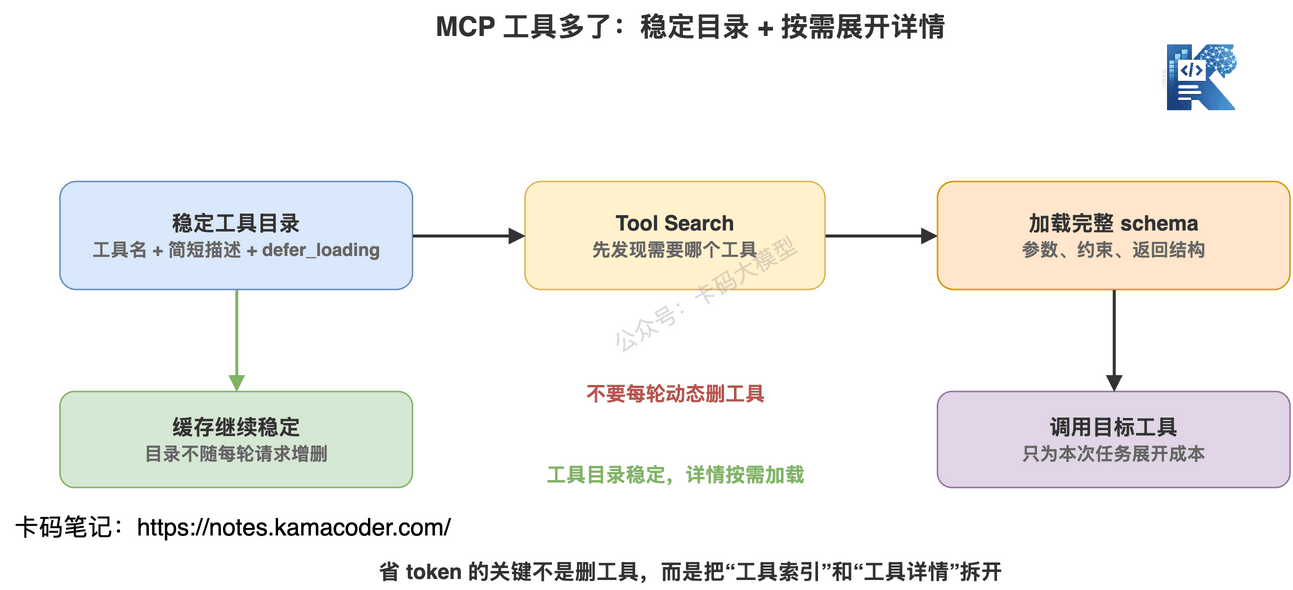
它可以先在稳定前缀里放轻量 stub。
也就是工具名、很少的元信息、以及 defer_loading 这样的标记。
完整工具 schema 先不塞进去。
当模型真的需要某个工具时,再通过 tool search 发现并加载完整 schema。
这样有两个好处:
第一,稳定前缀不会因为工具删来删去而变化。
第二,不常用工具的完整定义不会每轮都占 token。
所以 MCP 工具管理的核心不是:
我这一轮到底要不要给模型这个工具?
而是:
哪些工具信息必须稳定存在,哪些工具详情可以按需展开?
这个思路对我们自己做 Agent 也很重要。
不要一上来就把所有系统能力、所有接口文档、所有工具参数全塞进 Prompt。
先给工具目录。
需要时再展开详情。
# 七、上下文压缩不是另起一个总结请求
长会话跑久了,一定会遇到上下文窗口不够的问题。
Claude Code 里常见的处理方式就是 compact。
把前面的对话总结成一段摘要,然后用摘要替换原来的长历史,继续往下做。
这看起来很简单。
但从缓存角度看,这里面也有坑。
最容易想到的做法是:
单独发一个请求给模型。
系统提示词写“请总结下面这段对话”。
不带工具。
把完整历史塞进去。
让模型返回摘要。
这当然能跑。
但很贵。
因为这个总结请求的系统提示词、工具定义、上下文结构,和父会话完全不一样。
从第一个 token 开始就不匹配。
父会话前面攒下来的缓存,全用不上。
更糟的是:
越是需要 compact,说明对话越长。
对话越长,单独总结请求越贵。
这就是典型的“问题越严重,解决问题越贵”。
Claude Code 的做法是缓存友好分叉。
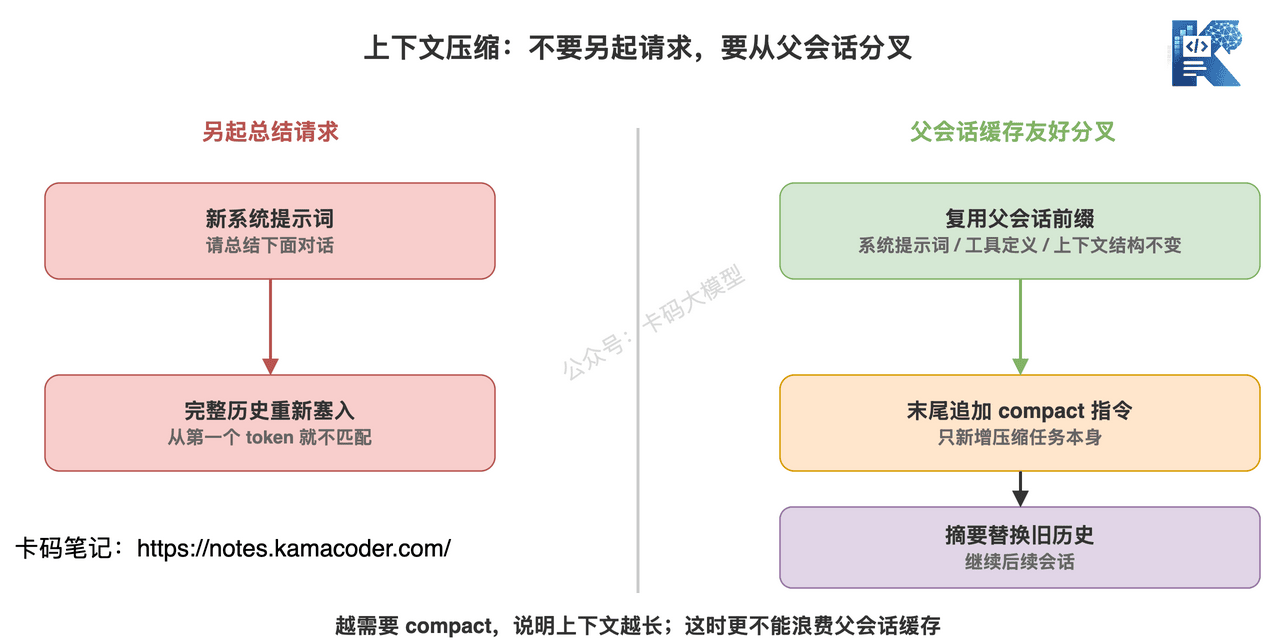
它在做压缩时,使用和父会话一样的系统提示词、用户上下文、系统上下文和工具定义。
先带上父会话的消息。
然后在末尾追加一条压缩指令。
从 API 视角看,这个请求和父会话上一次请求非常像。
前面大段前缀都一样。
只有末尾的压缩指令是新的。
这样就能复用父会话缓存。
当然,这也带来另一个工程要求:
系统必须预留压缩缓冲区。
不能等上下文窗口真的塞满了,再想着“现在总结一下吧”。
那时候已经没空间放压缩指令和摘要输出了。
所以成熟 Agent 产品会在上下文还没彻底满之前,就留出 compact buffer。
这点对我们自己做 Agent 也很关键。
不要把 compact 当成最后一刻的急救。
它应该是上下文生命周期管理的一部分。
# 八、缓存命中率要像服务可用性一样监控
Anthropic 在原文里有个细节很值得注意:
Claude Code 团队会监控 Prompt Cache 命中率。
命中率太低,会触发告警,甚至当成事故处理。
这个态度很说明问题。
很多团队做大模型应用,只监控这些指标:
- QPS
- 延迟
- 错误率
- token 消耗
- 单次请求成本
这些当然要看。
但做 Agent,还要看缓存。
尤其是长会话 Agent。
缓存命中率一掉,延迟和成本会一起变差。
用户体感就是:
怎么突然变慢了?
怎么同样的任务今天额度掉得特别快?
而研发侧如果只看请求成功率,可能完全看不出问题。
因为请求都成功了。
只是每次都在重算。
所以做 Agent 要多看两类 token:
cache creation input tokens:本轮写入缓存的输入 token。
cache read input tokens:本轮从缓存读取的输入 token。
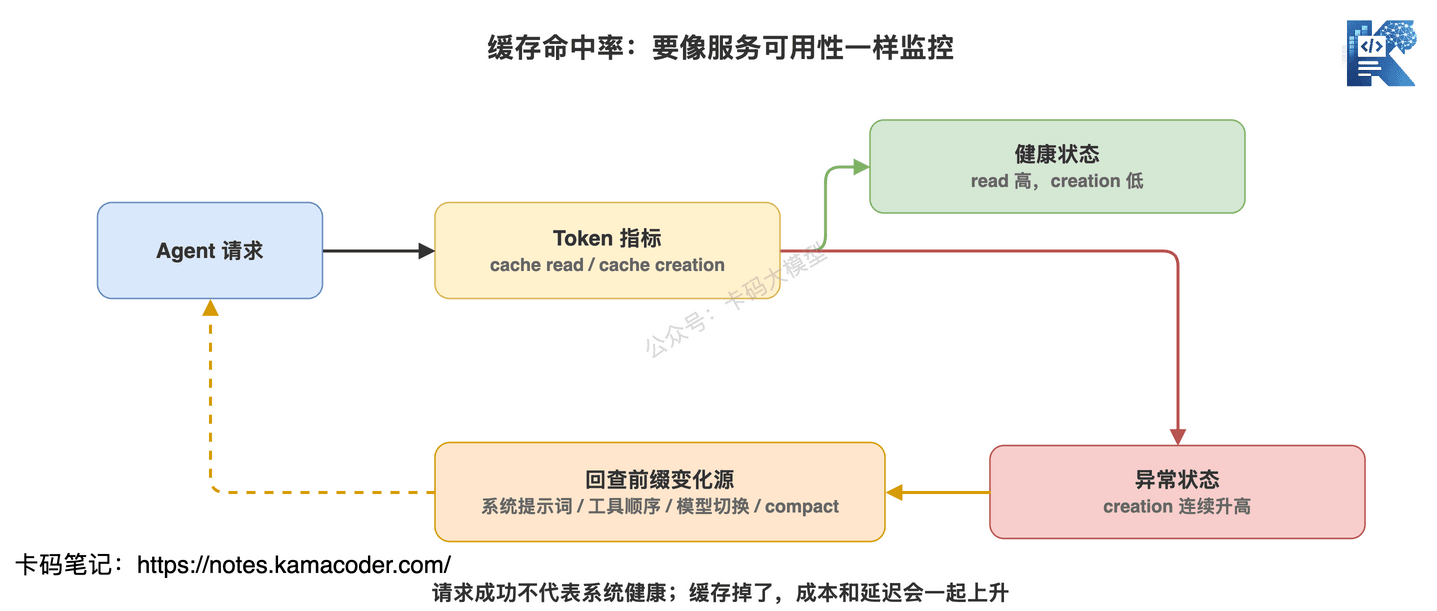
如果 read 很高,creation 很低,说明缓存用得好。
如果 creation 连续很高,说明你的前缀可能一直在变。
这时候不要先怀疑模型。
先查:
- 系统提示词是不是每轮都变
- 工具定义顺序是不是不稳定
- MCP 工具是不是动态增删
- 是否中途切了模型
- compact 是否另起了一个请求
- 是否把时间、文件变化、模式状态写进了前缀
很多 Agent 性能问题,不是模型问题。
是上下文组织问题。
# 九、这篇文章对普通开发者有什么用?
可能有录友会说:
这些都是 Claude Code 团队做产品的细节,我只是用 Claude Code 或者做一点大模型应用,有必要关心吗?
有必要。
因为这篇文章其实告诉我们一个大趋势:
Agent 工程不是只会调 Prompt,也不是只会接几个工具。
真正要做稳,要懂上下文结构、缓存策略、工具边界、模型切换、长会话生命周期。
如果你只是日常使用 Claude Code,可以记住这几条:
第一,别在长任务中频繁切模型。
切一次模型,下一轮可能会明显变慢,因为缓存要重建。
第二,CLAUDE.md 改完不一定立刻生效。
它属于会话开头加载的项目上下文,中途改了不一定会影响当前会话。要么重新开会话,要么在当前对话里明确补充。
第三,MCP 不要边做任务边频繁接入、断开。
MCP 工具定义会影响缓存,最好在一个任务开始前就把需要的 MCP 配好。
第四,compact 最好放在自然断点。
比如一个子任务完成后再压缩,而不是在关键编辑中间突然压缩。
第五,别把所有临时要求都塞进项目规则文件。
稳定规则写进 CLAUDE.md。
临时要求直接在当前对话里说。
如果你是做 Agent 产品的,那要再进一步:
- Prompt 结构按稳定性分层
- 工具定义顺序必须确定
- 工具集合尽量会话内稳定
- 动态状态用消息追加
- 多模型用 subagent 隔离
- 工具详情用延迟加载
- compact 走父会话缓存友好分叉
- 缓存命中率纳入监控
这不是优化清单。
这是架构清单。
# 十、最后说一句:缓存不是省钱小技巧,是 Agent 的地基
现在很多人讲 Agent,喜欢讲规划、记忆、工具调用、多 Agent 协作。
这些都重要。
但如果底层上下文每轮都在重算,工具集合每轮都在变,系统提示词每轮都不一样,模型动不动就切。
那这个 Agent 越跑越贵、越跑越慢,是迟早的事。
所以 Anthropic 这篇文章的价值,不在于告诉你“Prompt Cache 可以省钱”。
而在于告诉你:
Agent 产品的功能设计,要服从缓存约束。
Plan Mode 是这样。
MCP 工具加载是这样。
上下文压缩也是这样。
很多看起来是产品交互的问题,背后其实是缓存架构问题。
这也是 Claude Code 值得研究的地方。
它不是只把一个强模型塞进 CLI。
它是在模型之外,做了一整套能长期运行的 Agent harness。
而 Prompt Cache,就是这套 harness 里最容易被低估的一根主梁。
录友如果想做 AI 编程工具,或者想做真正可用的 Agent 系统,这篇原文建议认真读。
别只看它怎么省 token。
要看它怎么把缓存变成产品设计原则。
这才是重点。
评论
验证登录状态...