# Claude Skills实战:Anthropic用了几百个Skill,总结出9大分类和写好Skill的全部经验
录友们好,今天聊 Claude Code 里这一阵最火、但也最容易被用浅的一个能力:Skill(技能)。
前面我们专门讲过 CLAUDE.md 到底怎么写,那篇说的是怎么给 Claude Code 写一份「always-on 的项目规则」。Skill 是另一回事:它是按需加载的专项能力,平时不占上下文,用到了才被调起来。
正好 Anthropic 团队发了一篇博客《Lessons from building Claude Code: How we use skills》,把他们内部的实践摊开讲了。这家公司内部已经在用几百个 Skill,这篇是我目前看到关于 Skill 写得最实、最有信息量的一篇。
我把它读完,挑出最值得录友们记住的东西,加上我自己的理解,讲给你听。
# 先纠正一个误解:Skill 不是一个 markdown 文件
很多录友一听 Skill,第一反应是「不就是写个 .md 文件告诉 Claude 怎么做嘛」。
这个理解是错的,而且会让你写出来的 Skill 特别弱。
官方原话:Skill 是「指令、脚本和资源的文件夹」(folders of instructions, scripts, and resources)。注意,是文件夹,不是文件。
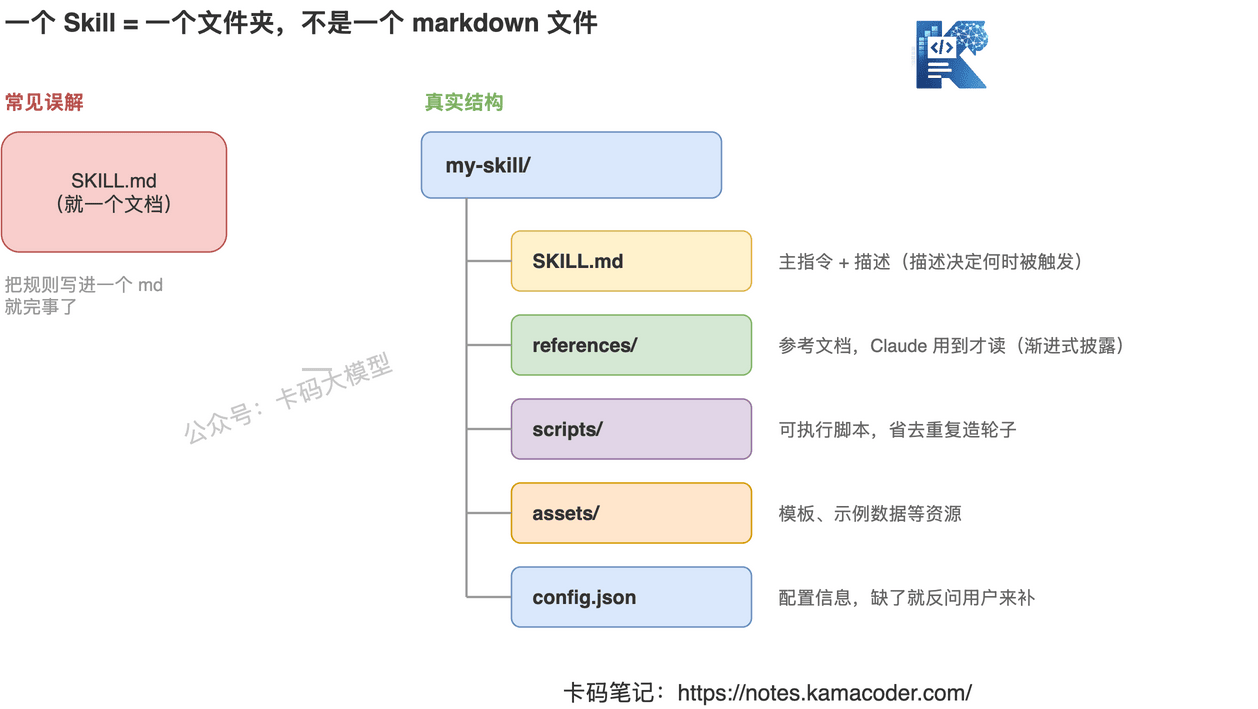
一个像样的 Skill 长这样:
SKILL.md:主指令 + 一段描述。这段描述很关键,它决定了 Claude 什么时候会触发这个 Skill。references/:参考文档。Claude 不会一上来全读,而是用到哪份才读哪份。scripts/:可执行脚本。能跑代码就别让 Claude 现写,直接调。assets/:模板、示例数据这类资源。config.json:配置信息,缺了 Claude 还能反问你来补。
为什么这个区别重要?因为一旦你把 Skill 当成「一个文档」,你就会拼命往一个 md 里塞东西,最后塞成一坨谁也读不动的长文。而把它当成「一个文件夹」,你才会去想:哪些是脚本、哪些是按需读的参考、哪些是模板。这才是 Skill 真正的威力。
# Anthropic 把几百个 Skill,归成了 9 类
Anthropic 内部把所有 Skill 盘了一遍,发现它们能干净地落进 9 个分类。而且他们有个很重要的观察:
最好的 Skill 只干一类事;什么都想干的 Skill,反而会把 Claude 搞糊涂。
这 9 类长这样:
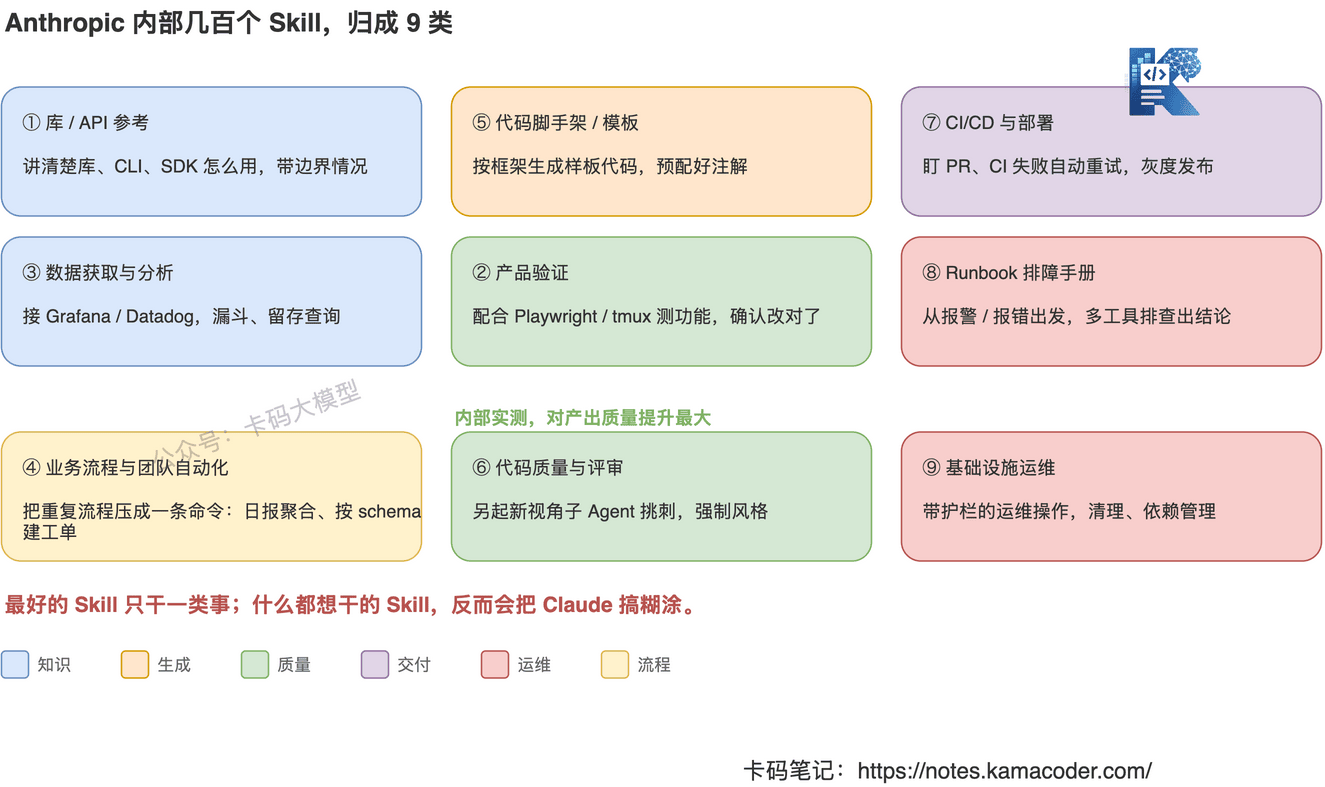
挨个说一下,对照着看你自己手头哪些活能做成 Skill:
- 库 / API 参考:讲清楚某个库、CLI、SDK 怎么用,重点是把边界情况写明白。比如内部计费库的各种坑、内部平台 CLI 的子命令示例。
- 产品验证:写完代码怎么验证它真的跑通了、真的能用。常配合 Playwright、tmux 这类工具。原文专门点名——这一类在内部对产出质量的提升是最可量化、最明显的。
- 数据获取与分析:接上数据和监控,比如漏斗查询、留存对比、Grafana / Datadog 的字段映射。
- 业务流程与团队自动化:把重复的协作流程压成一条命令。比如自动聚合大家的日报、按固定 schema 建工单。
- 代码脚手架 / 模板:按框架生成样板代码,注解、配置都预先填好。
- 代码质量与评审:强制代码规范、辅助 review。一个很妙的玩法是「对抗式评审」——另起一个全新视角的子 Agent 来挑刺。
- CI/CD 与部署:拉代码、推代码、发布。比如盯着 PR、CI 挂了自动重试,灰度放量、出问题自动回滚。
- Runbook 排障手册:从一个症状出发(一条 Slack 报错、一个报警),用多个工具一步步查,最后产出一份结构化的排查报告。
- 基础设施运维:带护栏的运维操作,比如清理孤儿资源、依赖管理。
这 9 类不用背,关键是那个原则:一个 Skill 对应一类事。你要是发现自己在写一个「既能查数据又能发布还能排障」的超级 Skill,停一下,拆开。
# 怎么写好一个 Skill?这几条最硬
分类讲完,重头戏是怎么把一个 Skill 写好。原文给了一长串原则,我挑出对录友们最有用的几条。
# 别说废话,只写能把 Claude「推出惯性」的东西
Claude 本身就懂很多编程知识。所以如果你的 Skill 主要是传递知识,别去写它本来就会的东西。
把笔墨花在那些能把 Claude 推出默认思路的信息上。原文举的例子是前端设计 Skill:与其告诉 Claude「怎么写 CSS」(它会),不如告诉它「我们团队的设计偏好是什么」(它不知道,而且默认风格往往不是你要的)。
一句话:写 Claude 不知道的,别写它已经知道的。
# Gotchas(坑)区,是整个 Skill 信号最强的部分
原文有个判断我特别认同:一个 Skill 里信息密度最高、最值钱的部分,是「坑」。
什么叫坑?就是那种「不告诉你,你一定会踩」的东西。比如:
- 同一个字段,在 A 系统叫
user_id,在 B 系统叫uid; - 某张表是 append-only 的,你以为能 update,其实只能插入。
这种知识在文档里通常找不到,全靠人踩出来。把它写进 Skill 的 Gotchas 区,价值远大于你复述十遍官方文档。
# 渐进式披露:SKILL.md 当索引,用到才读
这条是 Skill 设计的精髓,也是它和「一个长 md」最本质的区别。
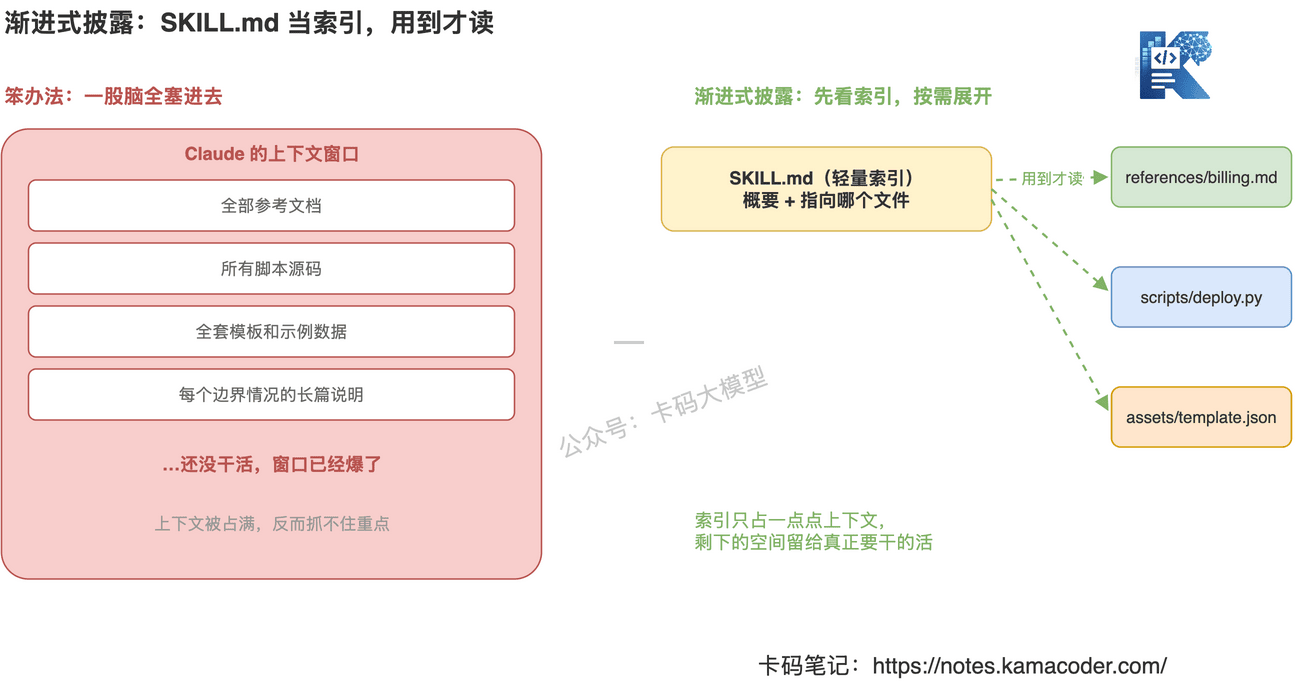
笨办法是:把所有参考文档、所有脚本源码、所有模板、每个边界情况的长篇说明,一股脑全塞进上下文。结果还没开始干活,上下文窗口就满了,Claude 反而抓不住重点。
聪明办法叫渐进式披露(progressive disclosure):SKILL.md 只放一个轻量的概要和「指针」——告诉 Claude「要做计费相关的事,去看 references/billing.md」。Claude 真用到了,才去读那个文件。
这其实就是上下文工程。文件夹结构本身就是你给 Claude 安排的上下文加载顺序。关于 Claude Code 怎么管理上下文、怎么读大代码库,我们在 Claude Code 作者说「不写 Prompt,写 Loop」 里聊过同一套思路,可以串起来看。
# 描述(description)是写给模型看的,不是写给人看的
SKILL.md 里那段描述,决定了 Claude 什么时候触发这个 Skill。
所以它不是给人看的简介,是给模型看的「触发条件」。原文的建议很直接:把触发关键词直接塞进去。比如一个盯 PR 的 Skill,描述里就该出现「babysit」这种用户真会说的词,而不是写一句文绉绉的「本技能用于持续监控合并请求的状态」。
录友们写的时候换个视角:用户会用什么话来唤起这个能力?把那些词写进描述。
# 让 Claude 记住自己干过什么
这条很容易被忽略,但很实用:Skill 可以存数据,让 Claude 读自己的历史。
做法是在 Skill 里维护一个 append-only 的日志或 JSON 文件,Claude 每次跑的时候读一眼自己上次的记录,据此调整这次的行为。官方还提了一个 ${CLAUDE_PLUGIN_DATA} 环境变量,用来做持久化存储。
相当于给 Skill 加了一层「记忆」。Agent 的记忆怎么分短期、长期,我们在 Agent 的记忆 里专门拆过,Skill 这个用法本质上就是在做长期记忆。
# 存脚本、给现成代码,让 Claude 把算力花在「决策」上
还有一条工程味很重的建议:能给现成脚本和函数,就别让 Claude 现写。
原文说得很到位——这样 Claude 就能「把它的回合花在组合上,决定下一步做什么,而不是重新拼样板代码」。
翻译成人话:Claude 的每一步推理都是有成本的。你把重复的样板活做成脚本,它就能省下脑子去想真正需要判断的事。这跟我们一直强调的 工具设计决定 Agent 上限 是一个道理。
# 别想着一上来就写个完美 Skill
最后这条,是我觉得整篇博客最让人安心的一句话。
Anthropic 内部那些最好用的 Skill,几乎都不是设计出来的,是养出来的。
原文:大多数 Skill 一开始就是几行字 + 一个坑,后来变好,是因为大家在 Claude 不断撞到新边界情况的时候,一条一条往里加。
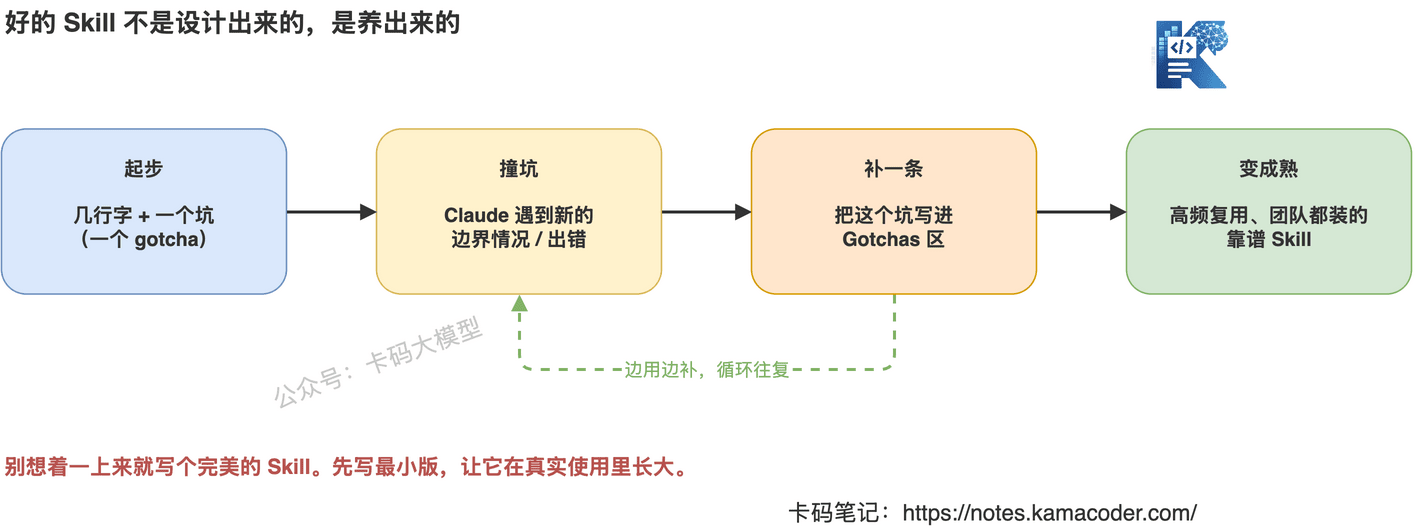
所以路径很清楚:
- 起步:写最小版,几行字 + 一个你已知的坑;
- 撞坑:Claude 在真实使用里遇到新情况、出了错;
- 补一条:把这个坑写进 Gotchas;
- 重复上面两步,循环往复,它就慢慢长成了一个靠谱、高频复用的 Skill。
别一上来就憋大招,憋出来的往往是个又长又没人用的文档。先写最小版,让它在真实使用里长大。
# 写在最后
Skill 这套东西,官方自己都说「最佳实践还在演进中」。但方向已经很明确了:它不是「一个 md 文件」,而是一个带脚本、带资源、带记忆、按需加载的文件夹;它最好只干一类事;它最值钱的部分是坑;它最该有的姿势是先小再长大。
录友们与其纠结理论,不如挑一个你每天都在重复的活——验证某个功能、查某张表、走某个发布流程——写成一个最小的 Skill,明天就开始用。
# 参考链接
- Anthropic 官方博客(How we use skills):https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
评论
验证登录状态...