# Claude Code 动态工作流详解:让 Claude 自己现写一套 harness,把一个任务拆给一队 Claude 去干
录友们好,继续聊 Claude。
上一篇 Managed Agents 我们讲了 Anthropic 怎么把 harness(Agent 的「外壳」)连同整套基础设施一起托管起来——那篇的主角是「平台替你管 harness」。这一篇正好反过来:Claude Code 现在能自己现写一套 harness,针对你当前这个任务,临时造一套专属外壳。
这就是 Anthropic 刚推出的「动态工作流(Dynamic Workflows)」。
# 先搞清楚:默认那套 harness,是为「写代码」定制的
harness 是什么?就是控制 Claude 读什么、什么时候动手、产出怎么验证的那层编排。Claude Code 自带的 harness 打磨得很好,但有个前提——它是冲着写代码这件事调出来的。
可你实际让 Claude Code 干的活,远不止写代码:深度调研、安全审计、给一队 Agent 分工、代码评审……这些任务的「最佳跑法」和写代码不一样。过去要把它们做到极致,你得自己在 Claude Code 之上手搓一套 harness。
动态工作流的意思就一句话:这套针对任务的 harness,不用你手搓了,Claude 自己现场写。
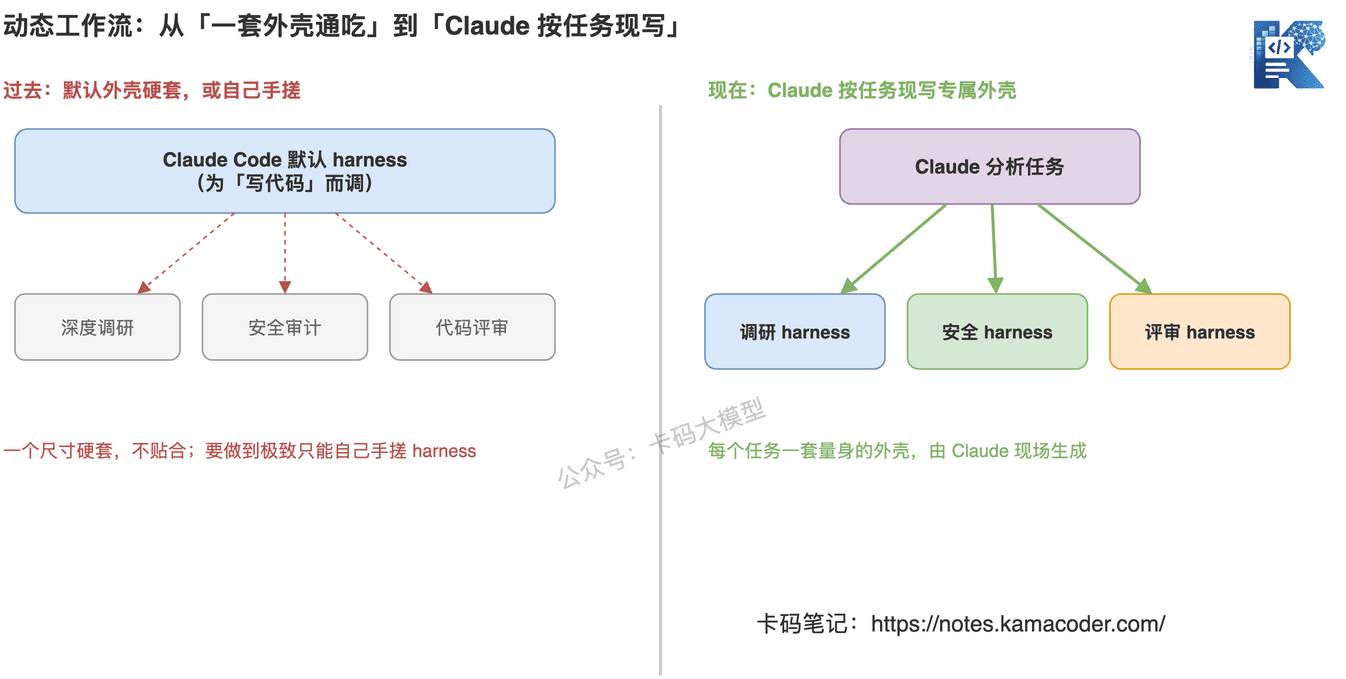
这张图回答的是:默认 harness 是一套尺寸想套住所有任务,要做到极致只能你手搓;动态工作流则是 Claude 分析完任务,给调研、安全、评审各现写一套量身的外壳。
# 关键一步:工作流是「真的代码」,不是提示词
很多录友一听「工作流」,第一反应是「不就是写一段精心调过的提示词嘛」。不是。
动态工作流是 Claude 现场生成、然后真的拿去执行的 JavaScript 文件。 它里头有几个基本积木:
agent(prompt, opts):开一个子 Agent,给它一个干净独立的上下文窗口,还能用 JSON Schema 约束它输出的结构;parallel(...):一道「栅栏」,几个任务全跑完才放行往下走;pipeline(items, ...):让一批东西流水线式地过几道工序,A 项可以先走,B 项慢一点也不挡道。
Claude 拿这几块积木,针对你的任务搭出一套编排:要不要开子 Agent、开几个、哪步用强模型哪步用便宜模型、要不要用 git worktree 把不同方案隔开、哪些并行哪些串行——这些都不是你预先规定死的,是 Claude 分析完任务自己定的。
# 为什么非得这么折腾?单个 context 扛不动
因为长任务里,一个 Claude 单挑全部时,老三样毛病会准时冒出来(这几个我们在 Agent 的失败模式 里专门拆过):
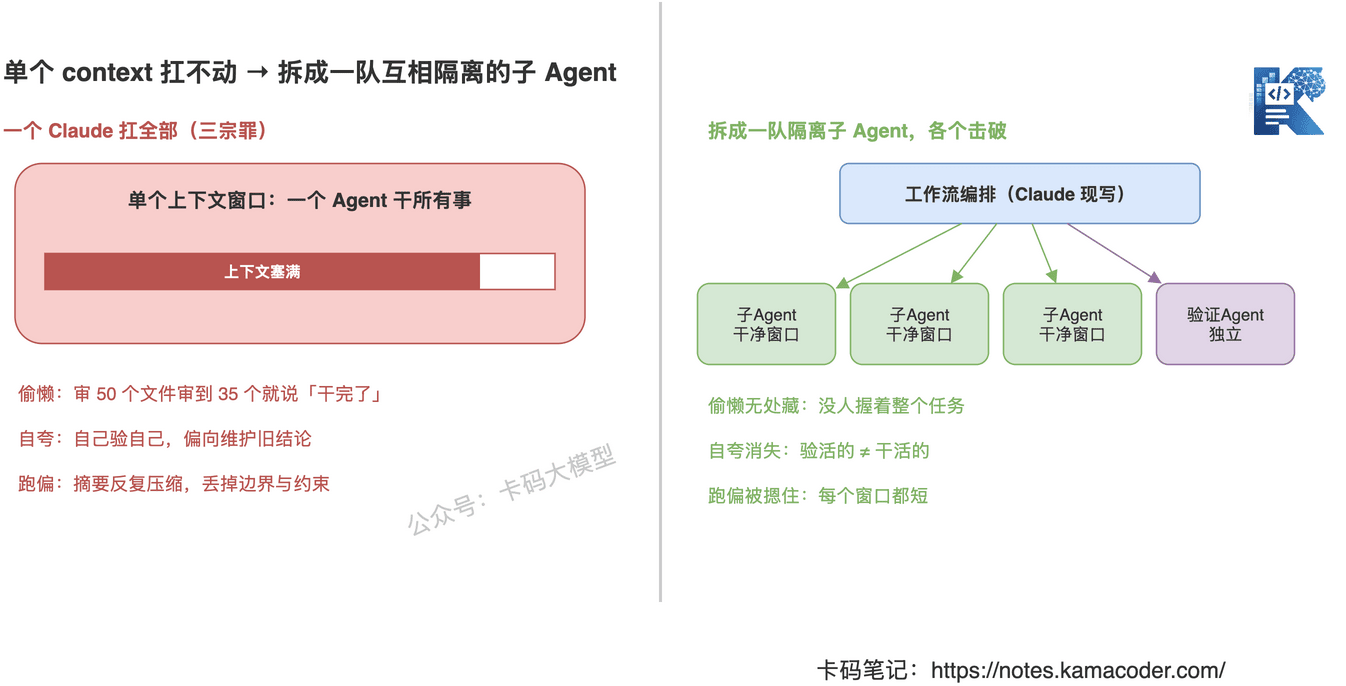
- 偷懒(agentic laziness):审 50 个文件审到 35 个就说「干完了」——不是模型坏了,是上下文塞满了,它把「差不多」当成了「做完」;
- 自夸(self-preferential bias):让 Claude 验自己的活,它会偏向维护自己之前的结论,跟「让学生给自己的卷子打分」一个道理;
- 跑偏(goal drift):对话拉长,反复压缩摘要,把边界要求、约束条件一点点丢掉,最后解的已经不是原来那个问题了。
动态工作流的解法是结构性的——与其让一个 Claude 扛全部,不如开一堆互相隔离、各自上下文干净、只盯一件事的子 Agent:
- 隔离 → 没有哪个 Agent 握着整个任务,偷懒无处藏;
- 独立的验证 Agent → 验活的和干活的不是同一个,自夸自然消失;
- 每个窗口都短 → 跑偏被摁住。
# 六种最常复用的编排模式
博客把实战里反复出现的编排归成了六类,照着对你自己手头的活:
| 模式 | 怎么跑 | 适合 |
|---|---|---|
| 分类即处理 | 先分流,再把每一类路由给专门的 Agent | 工单 triage、产出归档 |
| 扇出+汇总 | 拆成多份并行各跑一个 Agent,最后栅栏处汇总 | 审计、跨模块独立评审、深度调研 |
| 对抗验证 | 一个 Agent 提出,另一个专挑刺,两边不共享上下文 | 根因排查、结论复核 |
| 生成+筛选 | 先广撒网生成一堆候选,再按标准筛掉弱的 | 取名、方案探索、测试用例 |
| 锦标赛 | 多个 Agent/模型同题竞赛,裁判两两比较选优 | 模型路由、方案择优 |
| 跑到收工为止 | 反复「动手—检查—修复」,直到满足明确的停止条件 | 开放式排查、清扫式发现 |
其中对抗验证最该记住:验活的和干活的彻底分家、互不通气,一个结论只有在「反驳失败」之后才算数。这跟 Claude Skills 实战 里讲的「另起一个全新视角的子 Agent 来挑刺」是同一招,只不过这里把它做成了可复用的编排。
# 怎么开、怎么存、怎么分享
- 触发:直接说「给这个任务做一套工作流」,或者把 effort 调到
ultracode,让 Claude 自己判断什么时候该上工作流; - 盯进度:
/workflows打开一个运行面板,每个阶段、每个子 Agent、每次工具调用和 token 消耗都看得到,还能暂停、跳过卡住的、重试单个 Agent; - 可恢复:每次运行有 ID,断了能接着跑,跑过的阶段直接走缓存、只补没干完的——这点和 Managed Agents 的 session 可恢复是一个味道;
- 存下来复用:在面板里按
s存到~/.claude/workflows。一次漂亮的根因排查,就能沉淀成一套「根因排查工作流」;一次漂亮的迁移,就能沉淀成「迁移工作流」。
分享也简单:把这个 JS 文件丢进 Skill 文件夹发给队友。但记住它是模板不是死脚本——会根据具体任务自适应,而不是一行不差地重放。
# 但别滥用:它很烧 token
最后泼盆冷水。动态工作流比普通单 Agent 会话烧多得多的 token,因为它要协调一整队 Agent。
一个诚实的判断标准:这个任务,是不是真的需要比「一个上下文窗口」更多的算力?
- 值得上:50 个文件的安全审计、上千行的排序打分、高不确定要反复探索的调研、高风险要独立验证的改动、高复用值得沉淀成模板的流程;
- 别上:两行的 bug、改一个文件——那纯属杀鸡用牛刀,钱白烧。
它和 Agent vs Workflow 那篇的判断一脉相承:先想清楚任务到底需不需要这么重的编排,再决定上不上。它也是 Agent Teams 的「按需版」——角色固定就用 Teams,角色得临场拆解就用动态工作流。目前这功能还是 research preview,跑在 Claude Opus 4.8 上。
# 写在最后
从 不写 Prompt,写 Loop,到 Managed Agents 把 harness 托管,再到今天 Claude 自己现写 harness——这条线越来越清楚:编排这件事,正在从「人来设计架构」挪到「模型自己决定」。 你只负责说清楚什么算成功、信任边界在哪,剩下那套外壳,Claude 自己搭。
录友们哪怕暂时不开这个功能,「把一个大任务拆给一队互相隔离的 Claude、再汇总」这个思路,也值得记进脑子里。
# 参考链接
- Anthropic 官方博客(A harness for every task: dynamic workflows in Claude Code):https://claude.com/blog/a-harness-for-every-task-dynamic-workflows-in-claude-code
评论
验证登录状态...