# Claude Managed Agents详解:把Agent的「大脑」和「双手」拆开,从原型到上线只要几天
录友们好,继续聊 Claude。
上一篇我们讲了 Claude Skills 实战,那是「怎么给 Agent 加专项能力」。这一篇往下沉一层,聊一个更底层、但工程上更要命的问题:Agent 到底怎么跑起来、怎么稳稳地上生产?
Anthropic 刚发了一篇博客《building with Claude Managed Agents》,把他们这套新的 Agent 基础设施摊开讲了。
一句话概括 Managed Agents 是什么:一套帮你构建、部署生产级 Agent 的可组合 API,让团队从原型到上线,从「几个月」缩短到「几天」。
这篇我带你把它背后的架构思路捋清楚——尤其是那个最关键的设计:把 Agent 的「大脑」和「双手」拆开。
# 先看一条演进线:Agent 的「跑法」是怎么一步步变的
要理解 Managed Agents 解决了什么,得先看清楚我们是从哪一步走过来的。
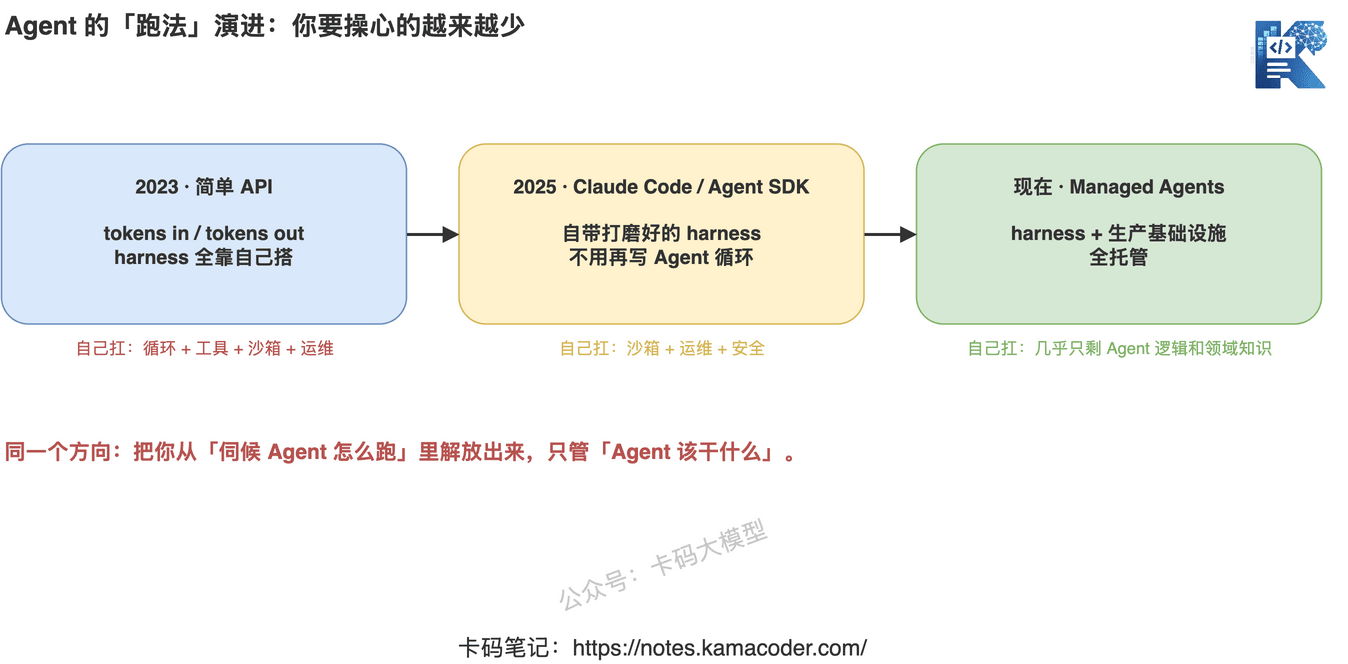
2023 年,简单 API 时代。 最早的 Claude API 故意做得很朴素:tokens in, tokens out(喂进去 token,吐出来 token)。模型只负责思考,至于怎么让它调工具、跑循环、连文件系统——那套「外壳」(harness)全得开发者自己搭。
2025 年,Claude Code 和 Agent SDK。 Claude Code 自带了一套打磨过的内部 harness,后来通过 Claude Agent SDK 开放出来,开发者不用自己写 Agent 循环了。这一步我们在 Claude Code 作者说「不写 Prompt,写 Loop」 里聊过——Agent 的核心就是那个「想—做—看结果—再想」的闭环。
现在,Managed Agents。 不只是给你 harness,而是把 harness + 整套生产基础设施一起托管起来。你专注写 Agent 的逻辑和领域知识,运行、伸缩、安全这些脏活累活,交给平台。
# 核心架构:把「大脑」和「双手」拆开
这是整篇博客最值钱的一个设计,我反复琢磨了几遍。
先说老架构的问题。过去 Agent 的 harness(负责推理、调度的「大脑」)和它操作的 sandbox 文件系统(执行代码的「双手」)经常挤在同一个容器里。听起来没毛病,但一上规模,三个问题全冒出来:
- 启动慢:每跑一个 Agent 都要冷启动一个容器,时间全耗在这上面;
- 凭证暴露:你的 API key、数据库密码,和 Agent 现场生成的代码待在同一个容器里——等于把钥匙和陌生人锁一个屋;
- 挂了就全丢:容器一崩,跑到一半的进度全没了,没法恢复。
Managed Agents 的解法很干脆:把大脑和双手拆开,放到不同的地方,中间用一个 session 连接。
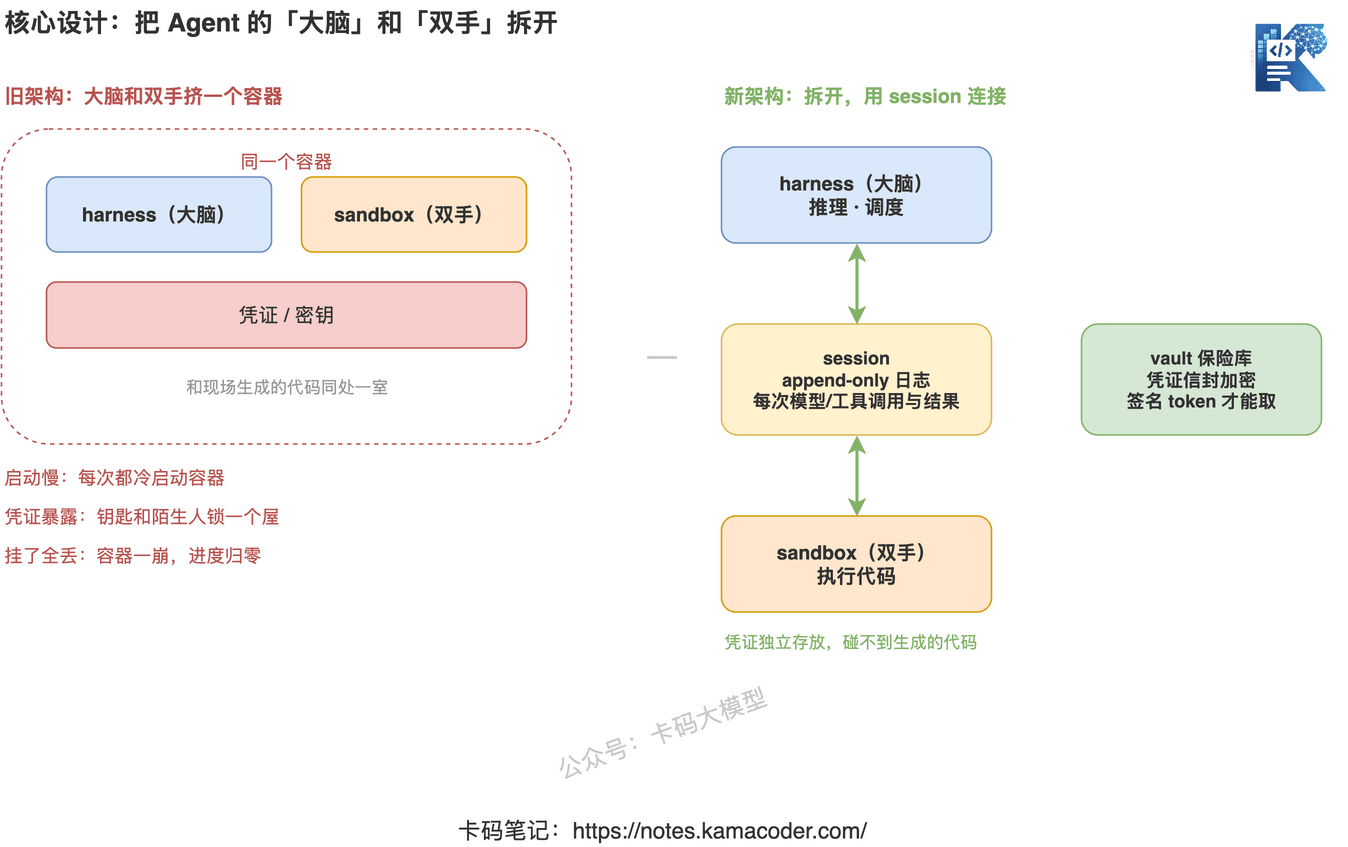
这个 session 是关键——它是一条 append-only 的日志,记录每一次模型调用、每一次工具调用、每一个返回结果。大脑在一边推理,双手在另一边执行,两边通过这条只追加、不修改的事件流对话。这条 append-only 日志,跟我们在 Claude Skills 实战 里讲的「让 Claude 读自己的历史」是同一个思路,只不过这里把它抬到了整个运行架构的层面。
拆开之后,整套东西由三种资源组成,理解了这三个,你就理解了 Managed Agents:
- Agents(智能体):配置。用哪个模型、什么提示词、能调哪些工具、有什么护栏。
- Environments(环境):执行上下文。sandbox 容器、预装好的依赖包。
- Sessions(会话):一次具体的运行。完整的事件历史存在服务端,可观察、可恢复。
「配置 / 环境 / 运行」三层分开,这就是把大脑和双手解耦之后,自然长出来的结构。
# 拆开之后,到底赚到了什么
解耦不是为了好看,是为了解决前面那三宗罪,外加几个生产环境上的真实收益。
第一,凭证安全。 凭证不再跟生成的代码同处一室,而是单独放进一个 vault(保险库)。存进去之前先做信封加密(envelope encryption),取出来还得带一个签了名的请求 token。Agent 现场写的代码再怎么折腾,也碰不到你的密钥。
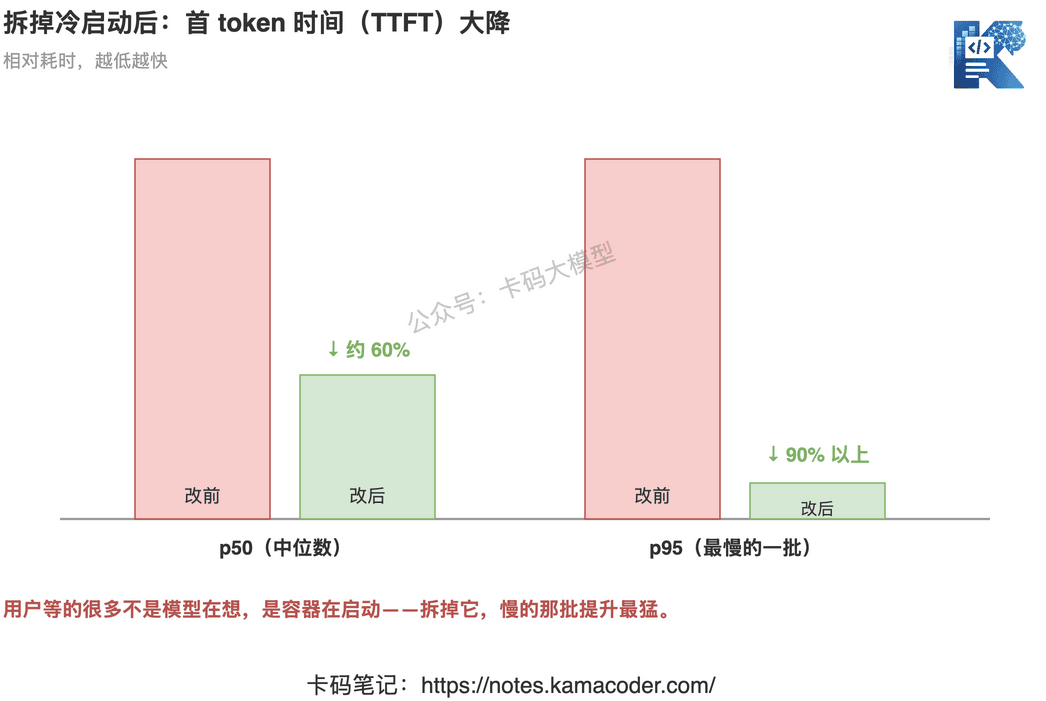
第二,延迟大降。 拆掉了「每次都冷启动容器」这块开销,首 token 时间(time-to-first-token)中位数(p50)降了大约 60%,最慢的那批(p95)降了 90% 以上。 这个数字很能说明问题——以前用户等的,很多根本不是模型在想,是容器在启动。
第三,会话可持久、可恢复。 session 是一条持续的事件流,你能实时看到 Agent 干活时的每一步,也能在之后任意时刻把某个 session 接着跑下去。容器崩了不再等于从头再来。
第四,部署灵活。 既可以用 Anthropic 托管的云容器,图省心;也可以把 sandbox 放进你自己的 VPC 里自托管,满足合规和数据不出域的要求。
# 一个容易被忽略、但很关键的 lesson
博客里有一段我特别想拎出来讲:模型在进化,harness 必须跟着一起进化。
原文举了个具体例子:在 Claude Sonnet 4.5 上,Agent 快用到上下文末尾时会**「赶工」——感觉自己快没空间了,就急着草草收尾。他们的修法是给 harness 加了上下文重置(context reset)**。结果呢?到了下一代模型,这个毛病没了,那段优化也就不需要了。
这件事戳中了一个现实:如果你自己维护 harness,你就得永远追着模型的脾气改。 这一代模型有这个怪癖你补一段,下一代变了你再删一段。而 Managed Agents 的意义就在这——这些跟着模型版本来回横跳的优化,平台替你扛了。
# 那么,谁该用 Managed Agents
博客给了一个很清醒的判断:对绝大多数团队来说,维护一套 harness 是「不产生差异化」的纯开销。
你的产品凭什么赢?是你的领域知识、你对上下文的组织能力,不是你那套 Agent 循环写得比别人精巧。基础设施这层,能交出去就交出去,把精力放在真正拉开差距的地方。关于「什么时候真需要一个 Agent、什么时候不需要」,可以回看 Agent vs Workflow,先想清楚再决定上不上这套东西。
几个客户数据也挺有说服力:
- Notion:用自定义 Agent 把「十二个小时的活,干成了二十分钟」;
- Sentry:调试 + 自动生成 PR 的 Agent,单个工程师几周就搞定,过去得几个月;
- Rakuten、Asana、Atlassian:跨部门把 Agent 铺开,大约一周就能上。
它还带了一堆生产级特性:Memory 和 Dreaming(定时回顾 session、从中提炼模式、整理记忆)、Outcomes(Agent 按评分标准给自己的活打分)、多 Agent 编排、权限策略、webhook,以及用 MCP tunnel 连你私网里的服务器。关于 MCP 这个协议本身,可以看 MCP 协议详解。
# 写在最后
从 tokens in/out,到自带 harness,再到今天把整个 harness 和基础设施托管起来——Anthropic 这条线其实一直在干同一件事:把开发者从「伺候 Agent 怎么跑」里解放出来,让你只管「Agent 该干什么」。
而这一切的技术支点,就是那个朴素又关键的决定:把大脑和双手拆开。录友们自己做 Agent 项目时,哪怕暂时用不上 Managed Agents,这个「推理和执行解耦、用一条 append-only 日志连接」的思路,也值得抄进自己的架构里。
# 参考链接
- Anthropic 官方博客(building with Claude Managed Agents):https://claude.com/blog/building-with-claude-managed-agents
评论
验证登录状态...