# Redis的缓存雪崩、缓存穿透、缓存击穿是什么?怎么解决?
# 简要回答
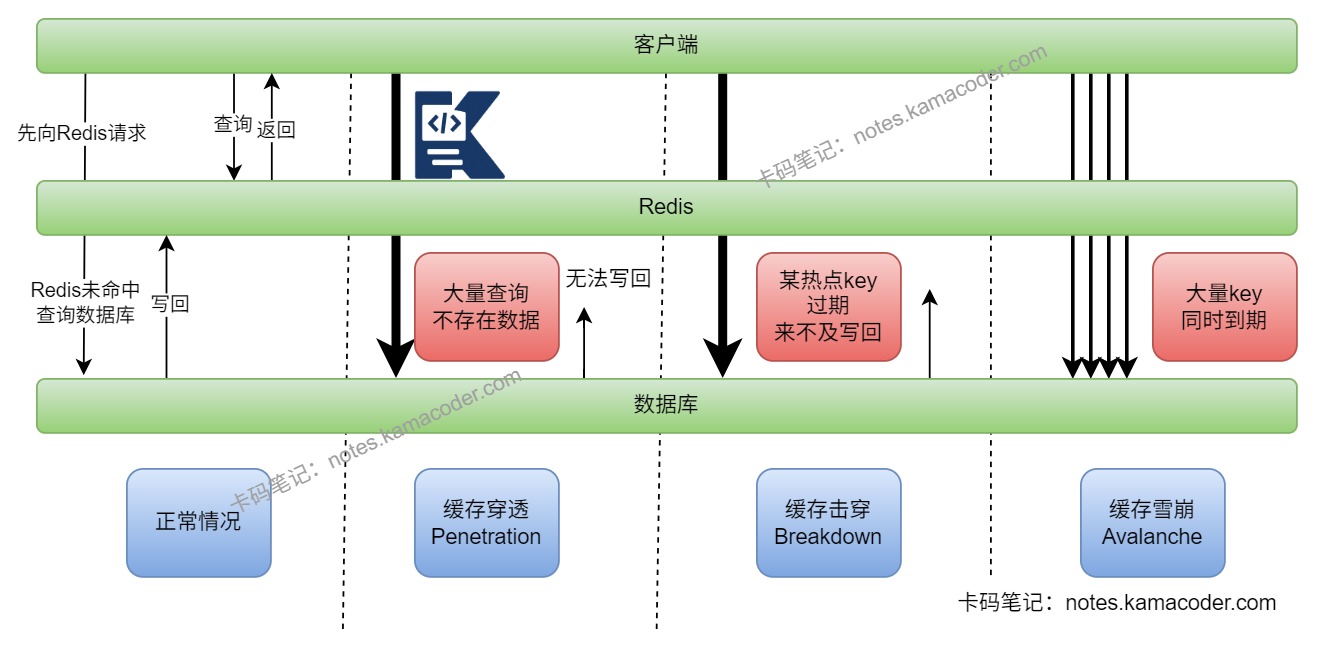
- Redis 的三个高频缓存问题分别是:缓存穿透(Penetration)、缓存击穿(Stampeding)和缓存雪崩(Avalanche)。缓存穿透是查一个本来就不存在的数据,请求绕过缓存不断打到数据库;缓存击穿是某个热点 key 过期瞬间,大量并发请求同时回源;缓存雪崩是大量 key 在同一时间失效,或者 Redis 整体不可用,导致请求成片压向数据库。
- 穿透的重点是拦住不存在的数据,常用参数校验、缓存空值、布隆过滤器解决;击穿的重点是保护热点 key 回源,可以使用互斥锁、逻辑过期、热点预热;雪崩的重点是系统级兜底,可以使用随机 TTL、高可用、多级缓存、限流熔断控制。
# 详细回答
缓存穿透:请求的数据在 Redis 里没有,在数据库里也没有。数据库查不到结果,也就无法回写缓存,导致每次请求都会落到数据库。缓存空值的实现最简单,但会占用一部分缓存空间,而且可能有短时间数据不一致;布隆过滤器适合海量 key 场景,但存在误判率,需要提前规划容量。
- 参数校验:先把明显非法的请求挡在业务入口,比如负数 ID、格式错误的主键,避免无意义查询进入缓存层。
- 缓存空值 / 默认空值:数据库查不到时,把空结果也缓存起来,并设置一个较短的 TTL。这样下一次相同请求会直接在缓存层返回。
- 布隆过滤器:把数据库中“可能存在”的 key 预先放入布隆过滤器。请求来时先判断,如果一定不存在,就直接返回,避免访问 Redis 和数据库。
缓存击穿 / Cache Stampede:某个热点 key在高并发场景下刚好过期,大量请求在同一时刻发现缓存失效,于是一起回源数据库。
- 解决缓存击穿:互斥锁更偏“强保护数据库”,逻辑过期更偏“优先保可用性和响应时间”,要根据业务一致性要求来选。
- 互斥锁 / 分布式锁:当缓存失效时,只允许一个线程去查数据库并重建缓存,其他线程等待、重试或快速失败。
- 热点 key 永不过期:对极热点数据不直接依赖 TTL,到期前由后台线程异步刷新,避免高峰时刻一起回源。
- 逻辑过期:缓存数据里额外带一个逻辑过期时间。业务线程读到已过期数据时,先返回旧值,再由后台线程异步重建缓存。这样能把可用性放在前面。
- 热点预热:在活动开始前、流量高峰前先把热点数据提前加载进缓存。
缓存雪崩:一批 key 在同一时间集中失效,或者 Redis 节点故障、集群不可用,导致大量请求同时打到数据库或下游服务。
- 过期时间打散:给不同 key 的 TTL 增加随机值,避免大量 key 同时在整点失效。
- Redis 高可用:使用主从、哨兵、集群等方案,降低 Redis 单点故障导致整体缓存层不可用的风险。
- 多级缓存:在本地缓存 + Redis + 数据库之间做分层,Redis 出问题时还能靠本地缓存兜一部分热点流量。
- 限流、降级、熔断:当缓存层异常时,主动限制回源流量,保护数据库和下游服务不被直接打垮。
- 数据预热和错峰刷新:对于大批量缓存,可以在后台分批刷新,而不是集中在一个时间点统一失效。
- 实际开发中:对普通业务 key:可以采用缓存空值 + 合理 TTL。对海量不存在 key 的风险场景:考虑布隆过滤器。对热点 key:考虑互斥锁、逻辑过期、异步重建。对系统层面稳定性:一定要叠加随机 TTL、Redis 高可用、限流降级。
# 知识图解
- 三类缓存问题对比
| 问题 | 核心特征 | 典型场景 | 主要风险 | 常见方案 |
|---|---|---|---|---|
| 缓存穿透 | 查询的数据根本不存在 | 恶意请求、错误参数、爬虫 | 数据库被无效请求打满 | 参数校验、缓存空值、布隆过滤器 |
| 缓存击穿 | 单个热点 key 失效瞬间并发回源 | 热门商品、热点店铺、活动库存 | 数据库被热点流量冲垮 | 互斥锁、逻辑过期、热点预热 |
| 缓存雪崩 | 大量 key 同时失效或 Redis 故障 | 批量导入缓存、整点统一过期、节点宕机 | 请求成片压垮数据库和下游 | 随机 TTL、高可用、多级缓存、限流熔断 |
- 三类问题示意
# 代码示例
public Shop queryById(Long id) {
String key = "cache:shop:" + id;
String json = redisTemplate.opsForValue().get(key);
// 命中正常缓存
if (json != null && !json.isEmpty()) {
return JSON.parseObject(json, Shop.class);
}
// 命中空值缓存,直接返回,防止缓存穿透
if ("".equals(json)) {
return null;
}
String lockKey = "lock:shop:" + id;
try {
// 只允许一个线程回源数据库,防止缓存击穿
boolean locked = tryLock(lockKey);
if (!locked) {
Thread.sleep(50);
return queryById(id);
}
// Double Check,避免重复查库
json = redisTemplate.opsForValue().get(key);
if (json != null && !json.isEmpty()) {
return JSON.parseObject(json, Shop.class);
}
if ("".equals(json)) {
return null;
}
Shop shop = shopMapper.selectById(id);
if (shop == null) {
redisTemplate.opsForValue().set(key, "", 2, TimeUnit.MINUTES);
return null;
}
// 正常数据写入缓存,TTL 里可以加随机值,避免缓存雪崩
long ttl = 30 + ThreadLocalRandom.current().nextInt(10);
redisTemplate.opsForValue().set(key, JSON.toJSONString(shop), ttl, TimeUnit.MINUTES);
return shop;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return null;
} finally {
unlock(lockKey);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 知识扩展
- 面试官可能追问:
- Q1:缓存空值和布隆过滤器应该怎么选?
- 如果业务实现要简单、数据量不大,缓存空值就够用;如果 key 规模大、穿透风险高,布隆过滤器更合适。很多时候两者也可以组合使用。
- Q2:为什么热点 key 不建议简单设置固定 TTL?
- 因为热点 key 一旦在高峰期过期,就容易引发大量请求同时回源数据库,形成缓存击穿。热点数据更适合逻辑过期、后台刷新或者提前预热。
- Q3:随机 TTL 为什么能缓解雪崩?
- 因为它把原本集中在同一时间点失效的 key 打散到不同时间段,避免缓存集中过期。
- Q4:互斥锁是不是一定最好?
- 不一定。互斥锁能保护数据库,但会增加等待时间,也可能带来锁竞争。对于一致性要求没那么高的热点读场景,逻辑过期 + 异步重建有时体验更好。
评论
验证登录状态...