# Multi-Head Attention详解:为什么一个头不够,多头怎么拆分和拼接
上一篇文章我们把 Attention 的计算过程完整走了一遍,从 QKᵀ 到 Softmax 再到加权求和。 这篇文章我们来聊聊:为什么 Transformer 不只用一个 Attention,而是要用"多个头"?
# 一个头有什么问题?
先看这句话:
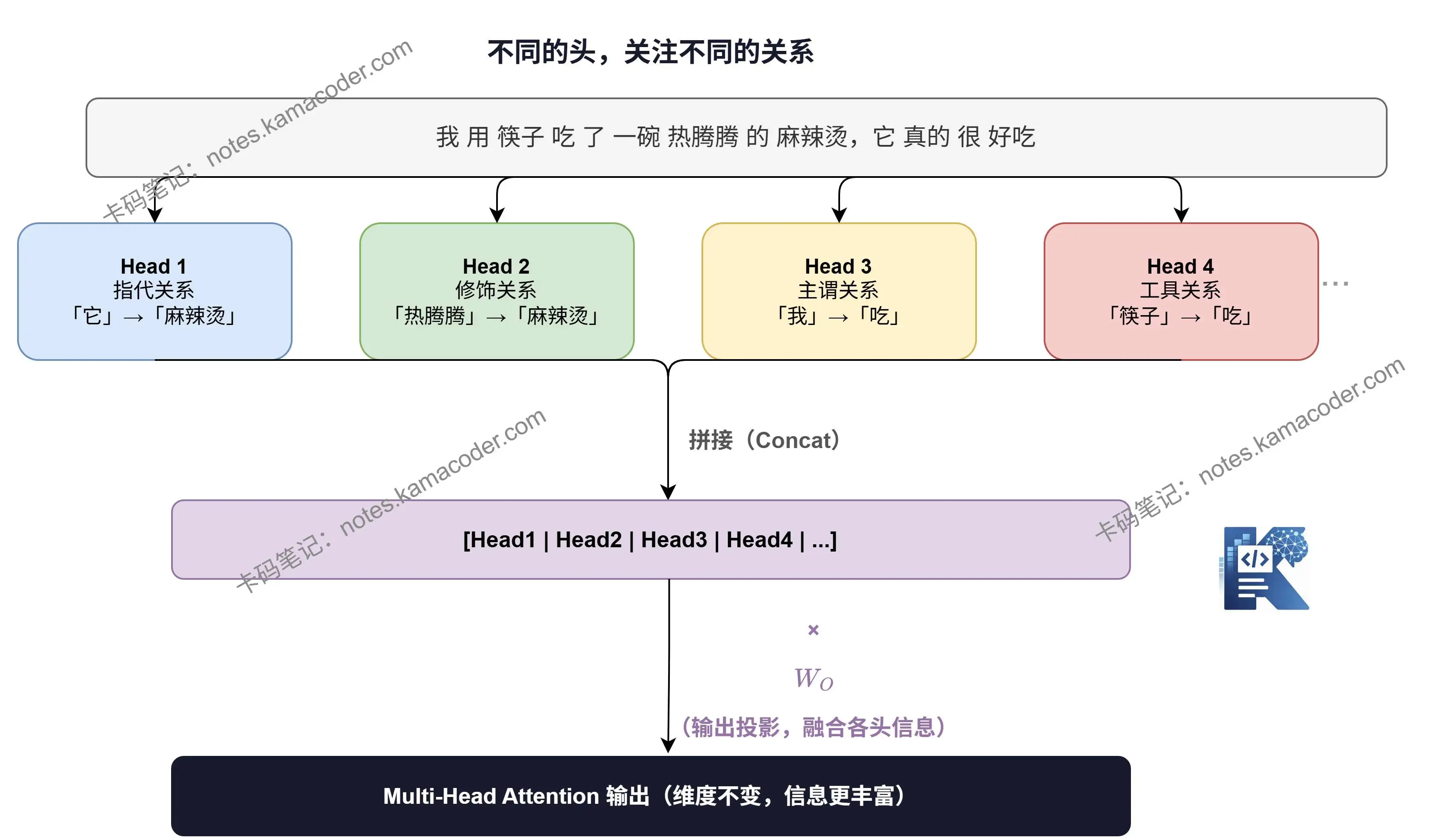
我用筷子吃了一碗热腾腾的麻辣烫,它真的很好吃
这里的"它"指的是什么?麻辣烫。
但如果我问你,模型在理解这句话时,需要同时搞清楚哪些关系?
- "它" → "麻辣烫"(指代关系)
- "热腾腾""麻辣烫"(修饰关系)
- "筷子" → "吃"(工具与动作的关系)
- "我" → "吃"(主语与动作的关系)
这些关系是同时存在的,但性质完全不同。
而单头 Attention 每次只能输出一个注意力权重矩阵,相当于从一个角度去看整句话的关系。很难指望它同时把"指代""修饰""语法"这些完全不同的信息都捕捉到。
一个头,就像只用一种颜色的笔去批注一篇文章——你只能标出一种重点。
# 多头的核心思路:让不同的头关注不同的关系
Multi-Head Attention 的思路很直接:
与其让一个 Attention 面面俱到,不如让多个 Attention 各司其职。
每个"头"(Head)都有自己独立的 W_Q、W_K、W_V 权重矩阵,经过训练后,不同的头自然会学到不同类型的关注模式:
- 有的头专门捕捉短距离的语法依赖(比如"主谓宾")
- 有的头专门处理指代关系("它"指向谁)
- 有的头关注位置信息(相邻词之间的关系)
这些头并行运算,最后把结果拼在一起,就能让模型同时"从多个角度"理解这句话。
# 维度是怎么拆分的?
这是很多初学者第一次看到多头时会懵的地方:多头 Attention 会不会让计算量变成原来的 h 倍?
答案是:不会。秘密在于"维度拆分"。
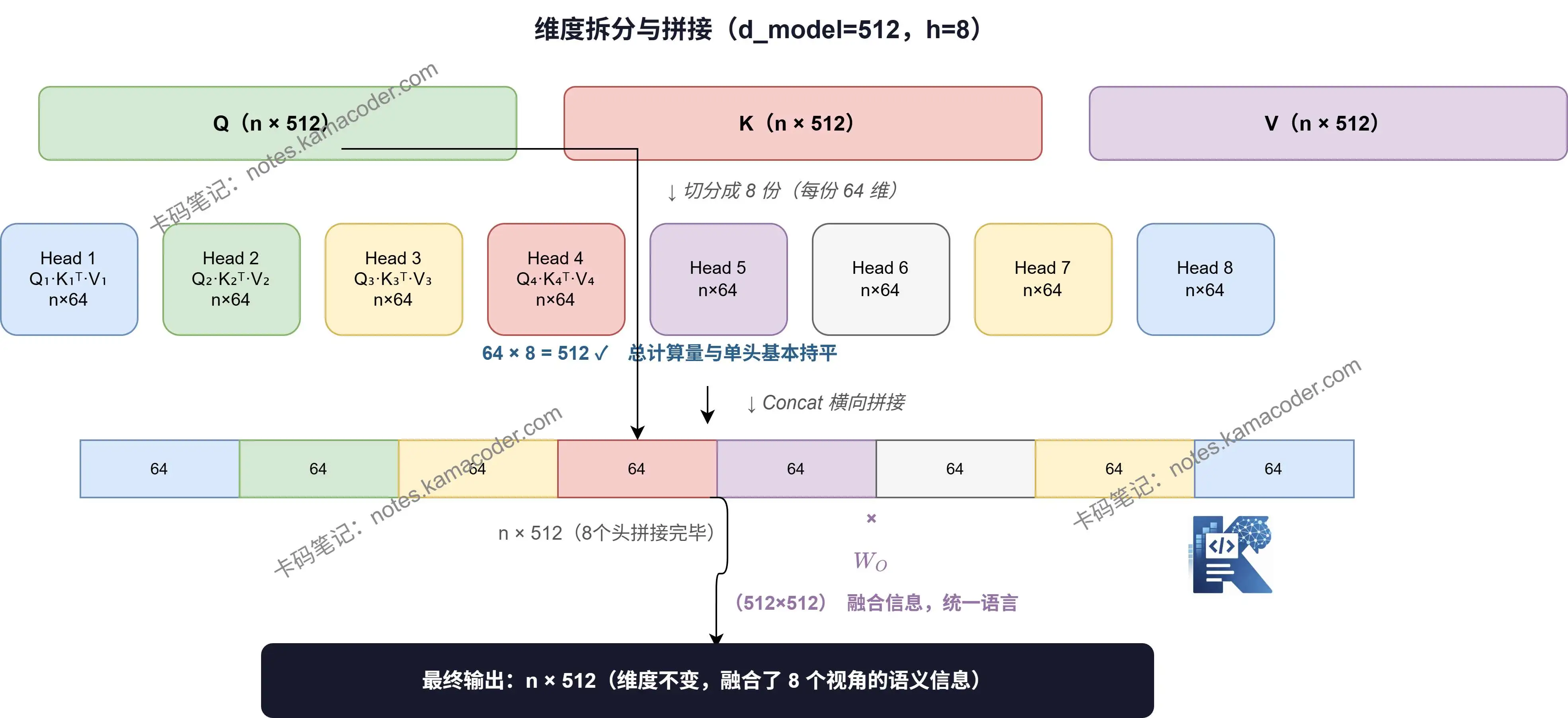
以 d_model = 512、h = 8 个头为例:
单头 Attention 中,Q、K、V 都是 512 维。 多头 Attention 里,每个头只用 512 ÷ 8 = 64 维。
也就是说,不是"用 8 个完整的 Attention 再加起来",而是把 512 维切成 8 份,每个头负责其中一份:
原始 Q(n × 512)→ 切分成 8 个 Q_i(n × 64)
原始 K(n × 512)→ 切分成 8 个 K_i(n × 64)
原始 V(n × 512)→ 切分成 8 个 V_i(n × 64)
2
3
每个头在自己的 64 维子空间里做完整的 Attention 计算,输出也是 n × 64。
总计算量和单头基本持平,但同时"看"了 8 个不同的子空间。
# 最后一步:拼接 + 线性变换
8 个头各自算完,得到 8 个 n × 64 的输出矩阵。 把它们横向拼接,就还原成 n × 512:
[head₁ | head₂ | ... | head₈] → n × 512
但拼接之后还没完——还要再乘一个 (512×512)的输出投影矩阵,做一次线性变换:
为什么还要乘 ?因为 8 个头各自在自己的子空间里理解信息,拼在一起之后,需要 把这些信息重新整合、混合,让不同头学到的东西互相"对话",输出一个统一的表示。
# 整体流程一眼看清
| 步骤 | 操作 | 输入 | 输出 |
|---|---|---|---|
| ① 线性投影 | 乘 | n × 512 | n × 512(每个) |
| ② 维度拆分 | 切成 h 份 | n × 512 | h 个 n × 64 |
| ③ 并行 Attention | 每个头独立计算 | n × 64 | h 个 n × 64 |
| ④ 拼接 | Concat | h 个 n × 64 | n × 512 |
| ⑤ 输出投影 | 乘 | n × 512 | n × 512 |
输入是 n × 512,输出还是 n × 512,维度没有变化,但每个 Token 的向量里已经融合了来自多个视角的上下文信息。
# 小结
多头 Attention 解决的核心问题,就是一个 Attention 头"视角太单一"。 通过维度拆分,让多个头并行、各自在低维子空间里学习不同的关注模式,最后拼接融合,在不增加计算量的前提下,大幅提升了模型捕捉复杂语言关系的能力。
下一篇文章我们来聊聊 **Positional Encoding **,看看为什么 Transformer中必须知道顺序 ,大家点个关注不迷路~
评论
验证登录状态...