# 索引有哪些种类?
# 简要回答
- 从 数据结构 的角度分类:
- B+树索引: 最常见,所有数据存储在叶子结点,适合范围查询和排序。
- 哈希索引(Hash): 等值查询快,但不支持范围查询。
- 全文索引(Full-Text): InnoDB 和 MyISAM引擎都支持全文索引,常用于文本内容搜索。
- 从 物理存储 的角度分类:
- 聚簇索引 (Clustered Index): 数据和索引存储在一起,决定物理顺序。
- 非聚簇索引(Non-clustered Index): 索引独立于数据存储,通过指针指向数据。
- 从 逻辑特性 的角度分类:
- 主键索引(Primary Key Index): 唯一的非空标识,不允许有空值。
- 普通索引(Normal Index): MySQL的基本索引类型,无唯一性限制,无空值限制。
- 联合索引(Composite Index): 在多个字段上创建,使用时遵循最左前缀原则。
- 唯一索引(Unique Index): 保证值唯一,允许空值。
- 空间索引(Spatial Index): MySQL5.7开始支持空间索引,用于地理空间数据。
# 详细回答
- 从 数据结构 的角度分类:
- B+树索引:
- B+树是数据库中广泛使用的索引类型。B+ 树是一种平衡树结构,其特点在于所有数据记录都存储在叶子结点,并且叶子结点之间通过链表连接。这种结构使得 B+ 树在执行 范围查询 和 按索引列排序 时效率极高。
- B+ 树的非叶子结点仅存储索引键值,不存储实际数据,这使得一个结点可以存储更多键值,从而降低树的高度,减少磁盘 I/O 次数,显著提升查询性能。
- 哈希索引(Hash):
- 哈希索引基于哈希表实现。它通过哈希函数将索引列的值计算成哈希值,然后将哈希值映射到存储数据记录指针的位置。哈希索引在处理等值查询时表现出色,理论上可以达到 O(1) 的时间复杂度。然而,由于哈希函数打乱了数据的原有顺序,所以哈希索引不支持范围查询和排序操作。
- 在 MySQL 中,Memory 存储引擎 支持显式创建哈希索引,而 InnoDB 存储引擎有自适应哈希索引,但用户不能直接控制其创建和删除。
- 全文索引(Full-Text):
- 全文索引是专门为文本内容搜索设计的索引类型。它主要用于在
CHAR、VARCHAR或TEXT等类型的列中进行关键词搜索。 - 全文索引底层通常使用倒排索引等数据结构来存储词语及其在文档中的位置信息,以实现高效的文本匹配。在MySQL中,InnoDB 和 MyISAM引擎都支持全文索引。
- 全文索引是专门为文本内容搜索设计的索引类型。它主要用于在
- B+树索引:
- 从 物理存储 的角度分类:
- 聚簇索引 (Clustered Index):
- 聚簇索引的数据和索引存储在一起,索引决定了表中数据行的物理存储顺序,这意味着数据行会直接存储在聚簇索引的叶子结点中。通过聚簇索引查找数据时,由于数据和索引紧密存储在一起,因而查找效率非常高。但需要注意的是,聚簇索引的插入和更新操作可能会导致数据行的物理位置移动,开销相对较大。
- 一个表只能拥有一个聚簇索引,在 InnoDB 存储引擎中,主键索引默认就是聚簇索引。
① 如果表定义了 PRIMARY KEY,那么 InnoDB 会使用 PRIMARY KEY 作为聚簇索引,所有的其他索引都是非聚集索引;
② 如果表没有定义 PRIMARY KEY,但定义了唯一的 NOT NULL 索引 (UNIQUE NOT NULL INDEX) ,这时 InnoDB 会选择第一个定义的 UNIQUE NOT NULL 索引作为聚簇索引,所有的其他索引(包括其他 UNIQUE 索引或普通索引)都是非聚集索引;
③ 如果表既没有定义 PRIMARY KEY,也没有定义 UNIQUE NOT NULL INDEX, InnoDB 会隐式地创建一个隐藏的聚簇索引。这个隐藏的聚簇索引是一个 6 字节的 ROWID,在这种情况下,你手动创建的任何索引都会是非聚集索引。
- 非聚簇索引(Non-clustered Index):
- 非聚簇索引独立于数据行的物理存储。非聚簇索引的叶子结点存储的是指向数据行的指针。在 InnoDB 中,这个指针通常是聚簇索引的键值。
- 一个表可以创建多个非聚簇索引。非聚簇索引的查找过程是先在索引中找到对应的指针,然后根据指针去查找实际的数据行。因此,相比于聚簇索引,非聚簇索引的查找可能需要额外的 I/O 操作,但其插入和更新操作通常比聚簇索引更快,因为它不影响数据行的物理存储顺序。
- 聚簇索引 (Clustered Index):
- 从 逻辑特性 的角度分类:
- 主键索引(Primary Key Index): 主键索引是一种特殊的唯一索引,用于唯一标识表中的每一行数据。一个表只能有一个主键索引,并且主键索引的值必须唯一且非空。在 InnoDB 中,主键索引是聚簇索引。
- 普通索引(Normal Index): 普通索引是最基本的索引类型,它没有唯一性限制,也没有空值限制。普通索引的主要目的是提高查询效率,允许索引列的值重复和为空。
- 联合索引(Composite Index): 联合索引是在表的多个列上创建的索引。例如,可以在 (column1, column2, column3) 上创建一个联合索引。在使用联合索引进行查询时,需要遵循最左前缀原则,即查询条件必须从索引的最左边的列开始。
- 唯一索引(Unique Index): 唯一索引保证索引列的值是唯一的,但与主键索引不同的是,唯一索引允许索引列的值为空(如果列定义允许为空)。一个表可以有多个唯一索引。
- 空间索引(Spatial Index): MySQL5.7开始支持空间索引,空间索引用于对地理空间数据进行索引,例如存储地理坐标信息的列。它适用于 GEOMETRY 等类型的列,主要用于加速地理位置相关的查询操作。
# 知识拓展
- MySQL 常见存储引擎支持的索引类型,如下表所示:

- MySQL InnoDB存储引擎 的B+树索引(非主键,非聚簇索引),如下图所示:
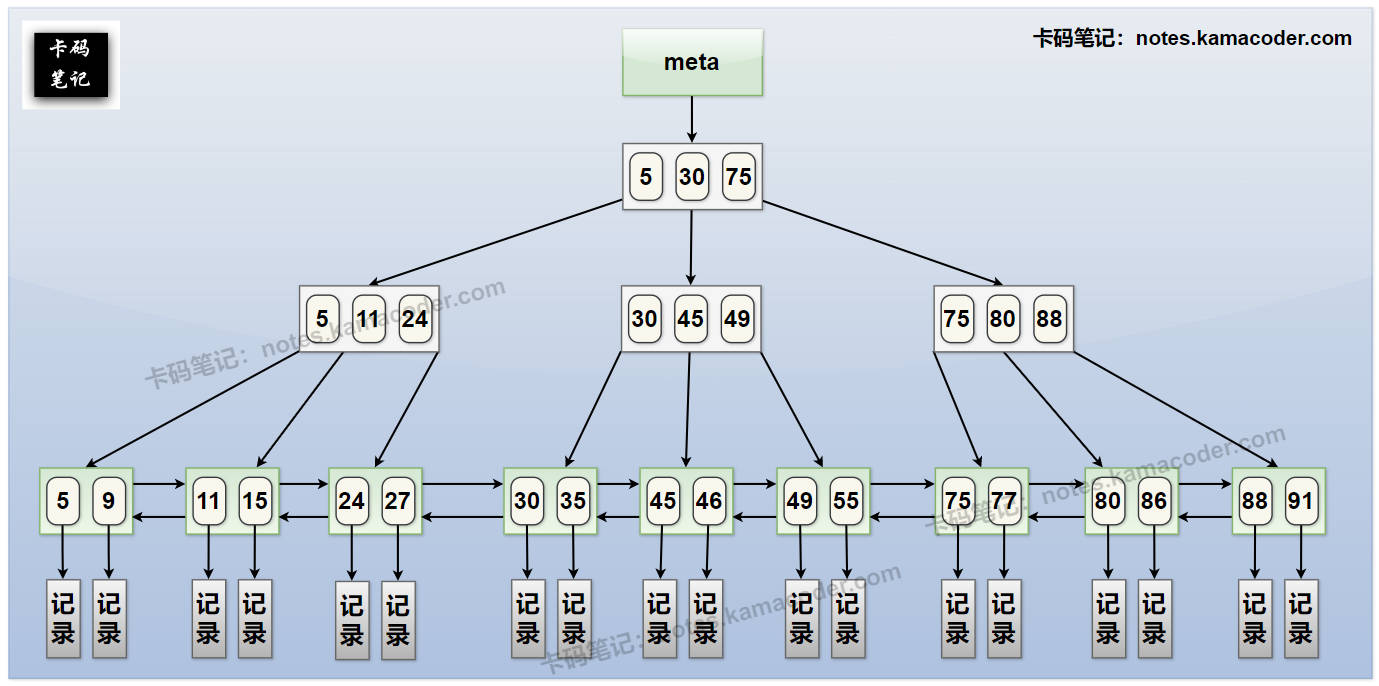
- 面试官可能的追问1: “你能简要解释一下为什么 B+ 树索引适合用于数据库索引,特别是相比于二叉树或 B 树?”
- 简答: B+ 树相比于二叉树或 B 树,其优势在于:所有数据都存储在叶子结点,并且叶子结点之间通过链表连接,这使得范围查询非常高效;非叶子结点只存储键值,可以存储更多的键值,从而降低树的高度,减少磁盘 I/O 次数,提高查询效率。
- 面试官可能的追问2: “聚簇索引和非聚簇索引在查找数据时有什么核心区别?”
- 简答: 聚簇索引的叶子结点直接存储数据行,通过聚簇索引查找数据时,找到索引结点就找到了数据。而非聚簇索引的叶子结点存储的是指向数据行的指针(通常是聚簇索引的键值),需要先在索引中找到指针,再根据指针去查找数据行。
- 面试官可能的追问3: “什么是联合索引的最左前缀原则?”
- 简答: 联合索引的最左前缀原则是指,如果在一个联合索引 (a, b, c) 上进行查询,只有当查询条件使用了索引的最左边的列(如 a,或 a 和 b,或 a、b 和 c)时,才能利用到这个联合索引来提高查询效率。
评论
验证登录状态...