# 面试官怎么问微调?应用开发者该怎么答

微调这一章,前面三篇该讲的都讲透了。
SFT、RLHF、DPO 微调方法全景认知 讲清了微调有哪几类、各自解决什么问题。
LoRA/QLoRA 低秩微调 讲清了真要动手训,rank、alpha、量化这些到底怎么回事。
什么时候微调、什么时候 RAG 讲清了选型——缺知识找 RAG,缺行为才考虑微调。
知识铺完了,剩最后一个问题:
这些东西,到了面试现场,到底怎么用?
这一篇我专门讲这个。不再讲新概念,就讲一件事:作为应用开发者,你面对微调题的真正困境,以及怎么破。
# 一、应用开发者面对微调题的真正困境
很多录友一聊到微调面试,都有一种拧巴的感觉。
答浅了,怕面试官觉得你没真做过——“哦,就调了个 API 啊。”
答深了,又怕一脚踩进算法岗的深水区——面试官顺着你的话往下挖:“那 PPO 的目标函数你推一下?”“LoRA 的低秩矩阵初始化为什么一个高斯一个置零?”然后你就卡死在那儿。
这就是应用开发者的核心困境:你不知道自己该答到哪一层。
我先把结论给你:
面试官问应用岗微调,考的从来不是你会不会训模型,是你有没有工程判断力。
什么叫工程判断力?就是这几件事——
- 这个需求该不该微调,为什么;
- 微调的数据从哪来、靠不靠谱;
- 怎么证明微调真有收益,而不是“感觉变好了”;
- 成本划不划算,基模一升级会不会白训。
这些问题,没有一个需要你手撕训练代码。但每一个都能把“只会跑脚本”的人和“真懂工程”的人区分开。
想通这一层,后面所有的回答策略都顺了。
# 二、面试官的追问是有梯度的
面试官问微调,几乎都是同一个套路:从你简历上一句话开始,一层一层往下挖。
挖到哪一层算合格、再往下是谁的活儿,你心里得有数。
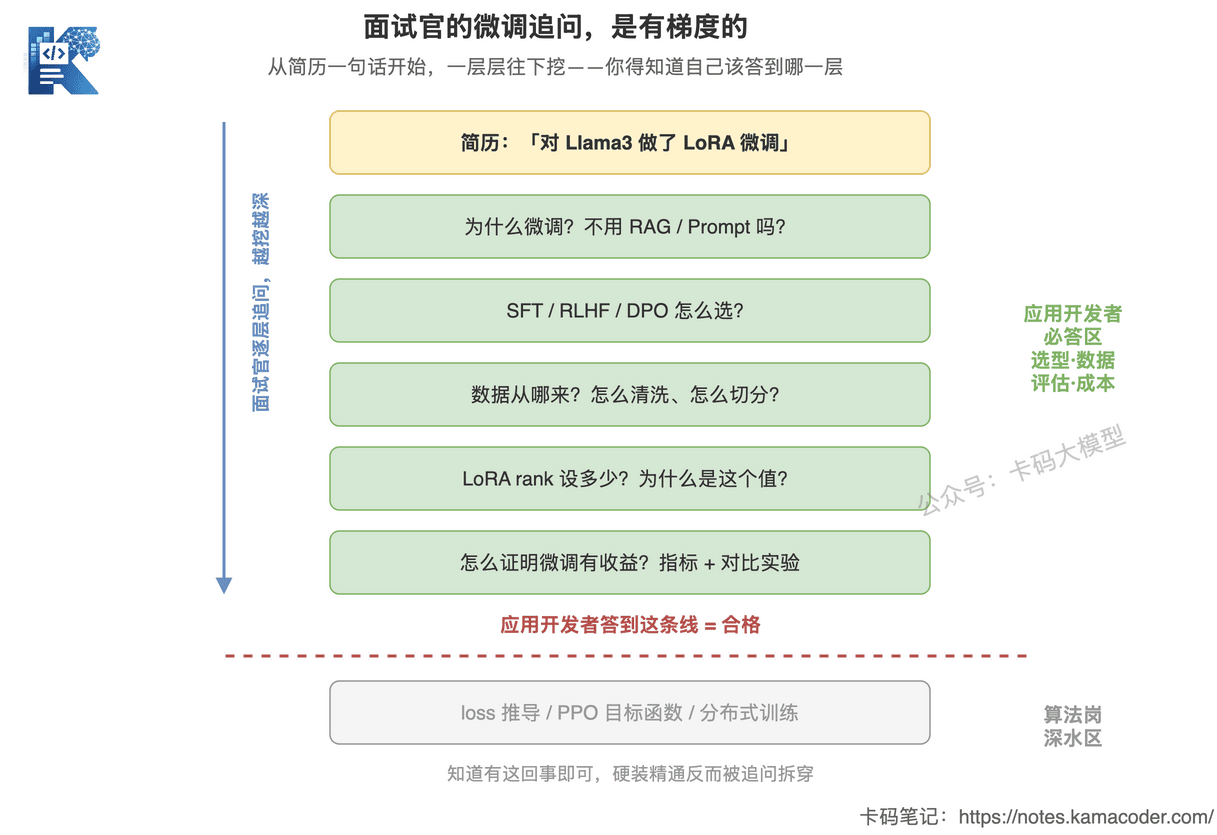
这张图回答的是:面试官对微调的追问是怎么一层层加深的,以及应用开发者该守住哪条线。
从最上面那句简历开始,问题越往下越深:先问你为什么微调、怎么选方法,再问数据和指标——这些都在应用开发者的必答区里,你答不上来,就是真没做过。
但过了那条红线再往下——loss 怎么推导、PPO 目标函数、分布式训练怎么搭——这就进了算法岗的深水区。应用岗答到“我知道有这回事、大概是干嘛的”就够了,没必要硬装精通。装精通的下场,是被一个追问当场拆穿。
所以面试的关键不是答得多深,是答到该答的那条线,并且让面试官知道你清楚这条线在哪。 一个会主动说“训练实现的细节是算法同学负责的,我主要负责选型、数据和评估”的人,反而显得专业。
下面我们就从必答区开始,把红线以上的高频问题逐个拆。
# 三、回答总原则:守住四条线
红线以上的所有问题,其实都挂在四条线上:选型、数据、评估、成本。
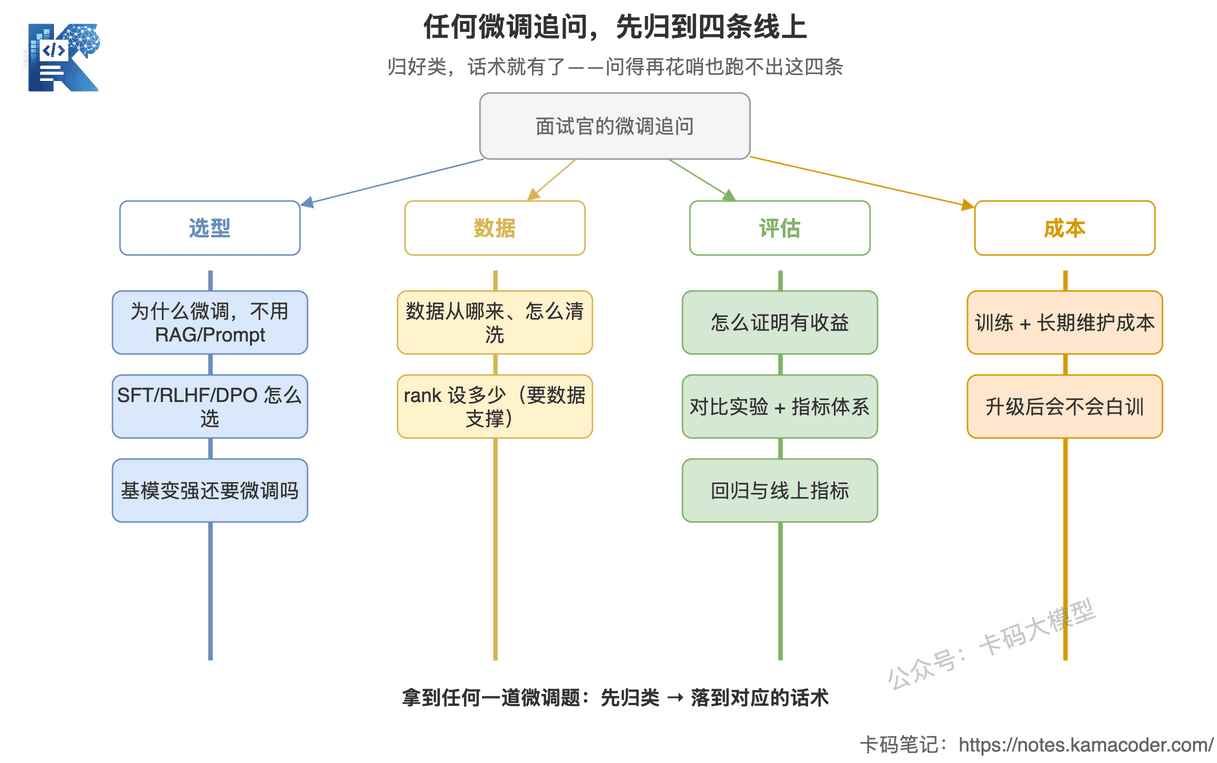
这张图回答的是:面试官五花八门的微调追问,怎么归到四条主线上。
你看,「为什么微调」「SFT/RLHF/DPO 怎么选」归到选型,「数据从哪来」归到数据,「怎么证明有收益」归到评估,「基模变强还要不要微调」归到成本。问法千变万化,落点跑不出这四条。拿到任何一道微调题,先在心里归个类,话术就有了落脚点。
把这四条线记牢,任何微调题你都能找到落脚点:
- 选型:为什么微调、为什么不用 RAG/Prompt、用哪种微调方法;
- 数据:训练数据从哪来、怎么清洗、怎么切分;
- 评估:怎么证明有收益,离线指标、在线指标、对比实验、回归;
- 成本:训练成本、维护成本、基模升级后会不会白训。
面试官的问题再花哨,你都先在心里归一下类:这是在问选型,还是数据,还是评估,还是成本。归好类,话术就有了。
# 四、高频问题逐个拆
下面六个问题,覆盖了应用岗微调面试的绝大多数情况。每个我都给你踩雷答法和参考话术的对比。
# Q1:你这个项目为什么微调?不能用 RAG 或 Prompt 吗?(选型)
这是最高频的一道,也是筛人最狠的一道。
踩雷答法:“因为模型不知道我们的业务知识,所以微调让它学进去。”
——这一句就暴露了。把微调当知识库用,是最典型的外行误解。面试官听到这儿基本就给你贴标签了。
参考话术:
“我判断的核心是先定位问题:模型效果不好,到底是因为它‘不知道’,还是因为它‘做不好’。
如果是缺知识——要回答内部文档、实时数据、还要能追溯来源——我用 RAG,不会微调。因为这类知识量大、会变、还要可追溯,硬训进参数代价太高,改一次就得重训,还可能引发灾难性遗忘。
我们这个场景缺的是行为——要固定的输出格式 / 特定话术 / 专业判断风格。这种我会先看 Prompt 和 few-shot 能不能解决,因为它最便宜。Prompt 搞不定、手里又有高质量示范数据,才上微调。我的成本优先级是 Prompt < RAG < 微调。”
这道题的完整框架——四个判断维度、混合架构——我在 什么时候微调、什么时候 RAG 那篇讲得很细,这里不展开。记住一句话就够用:缺知识找 RAG,缺行为才微调,能用 Prompt 绝不训模型。
# Q2:SFT、RLHF、DPO 有什么区别?分别适合什么场景?(选型)
这道是送分题,但也最容易答成背书。
踩雷答法:把三个英文全称和定义背一遍,背完就停。面试官最烦这个。
参考话术(一句话一个,点到场景为止):
“SFT 是监督微调,给模型看‘输入对应什么输出’的高质量示范,适合固定格式、固定话术、工具调用范式这类能写出标准答案的任务。
RLHF 和 DPO 都是偏好对齐,解决的是‘没有唯一正确答案、但业务明显更喜欢某一种’的问题。RLHF 要先训一个 Reward Model 再用 PPO 优化,比较重;DPO 直接用 chosen/rejected 偏好对训练,省掉了 Reward Model 和 PPO,工程上更轻。所以有了高质量偏好数据,我会优先 DPO 而不是一上来做完整 RLHF。”
这三者的来龙去脉在 SFT、RLHF、DPO 全景认知 里。答这道题的诀窍:每个方法只说‘解决什么问题 + 适合什么场景’,别背定义,更别去推 PPO 的公式——那是红线以下的事。
# Q3:你用 LoRA 训的?那 rank 设的多少,为什么是这个值?(选型 + 数据)
这道题是面试官专门用来戳“只会跑脚本”的人的。
踩雷答法:“rank 设的 8。”——然后没了。问“为什么是 8”就答不上来。这等于直接承认你是抄的配置。
参考话术:
“我一般从 8 或 16 起步。rank 控制的是低秩矩阵的秩,本质是给微调多大的‘改动容量’:rank 越大能学的东西越多,但参数和显存也越多,还更容易过拟合。
任务越简单、数据越少,我用小 rank(8)就够;任务复杂、数据量大,才往上加到 16、32。具体哪个好我不是拍脑袋定的——是固定其他条件、跑几组对比实验,看验证集指标选出来的。alpha 我一般设成 rank 的两倍左右,控制 LoRA 这部分的更新强度。”
注意这个回答的分寸:讲清了 rank 是什么、怎么权衡、怎么定,但没有去推低秩分解的数学。 这就是应用岗的安全深度。原理细节在 LoRA/QLoRA 那篇,面试前过一遍就能从容应对这一串连环问。
# Q4:你怎么证明微调真的有收益?(评估)
这道题是应用岗最该答深、也最能拉开差距的一道。 因为它考的恰恰是工程能力,不是算法能力。
踩雷答法:“微调完感觉效果好多了,输出明显更规范了。”——“感觉”两个字一出口,面试官就知道你没有评估体系。
参考话术:
“我不会用‘感觉’来判断,一定要用指标和对比实验说话。
首先是对比实验:固定测试集,拿微调前的基线模型和微调后的模型跑同一批 case,对比指标。没有基线对比的‘提升’都是耍流氓。
指标我会分几类看:
- 任务指标:比如 JSON 合法率、分类准确率、信息抽取的 F1、工具调用成功率,这是任务本身做没做对;
- 质量指标:幻觉率、格式错误率、错误拒答率,看回答质量;
- 成本指标:如果微调目标是用小模型替代大模型降本,那就看单次调用成本、延迟降了多少;
- 风险指标:高风险业务还要看越权率、错误放行率有没有下降。
然后是回归测试:我会留一个固定回归集,尤其保留历史失败 case,防止‘这个场景好了、另一个场景坏了’。最后还要看线上指标,因为离线测试集好不代表真实流量上好。”
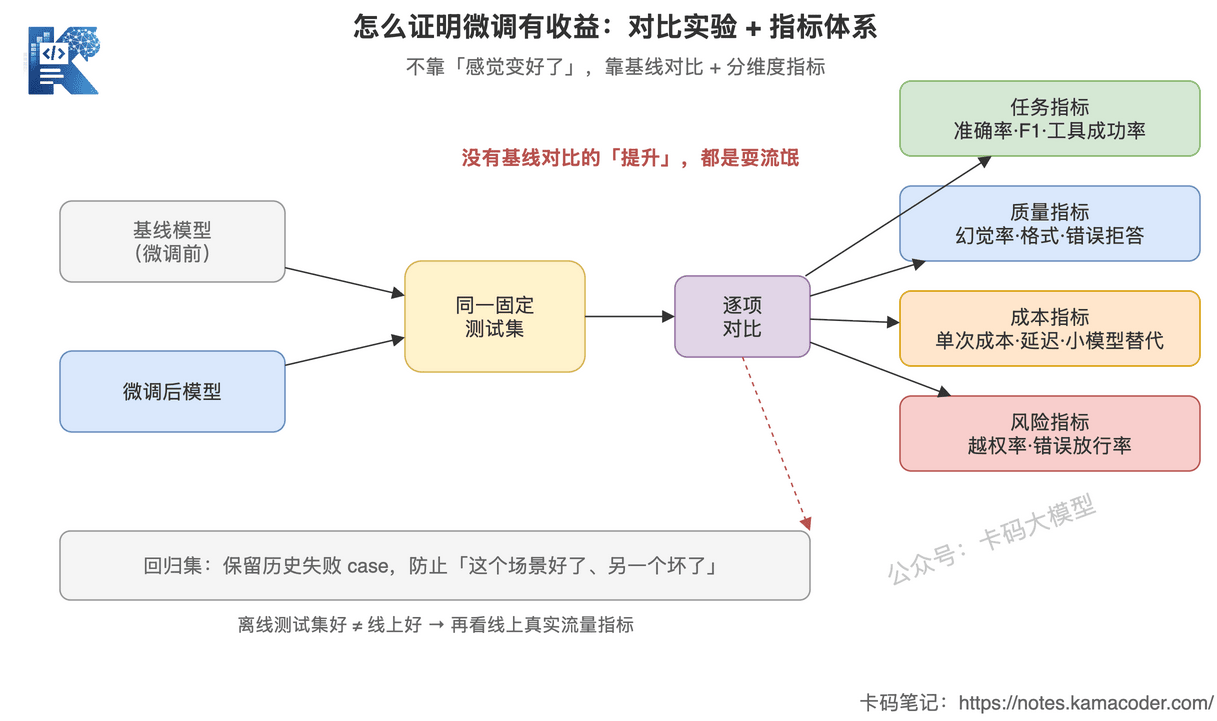
这张图回答的是:怎么用工程方法证明微调有收益,而不是靠「感觉」。
核心是对比:基线模型和微调后模型跑同一固定测试集,逐项对比——没有基线对比的「提升」都是耍流氓。对比不是看一个总分,而是 fan-out 到任务、质量、成本、风险四个维度分开看。底下那条虚线回到回归集:保留历史失败 case,防止顾此失彼,离线好了还要再看线上真实流量。
这套指标体系在 SFT、RLHF、DPO 那篇的第八节 有完整展开。这道题你答得越具体、越像真做过,加分越多——它几乎是应用岗微调题里性价比最高的一道。
# Q5:微调的数据是怎么来的?怎么保证质量?(数据)
很多人能讲方法、能讲指标,一到数据就露馅——因为没真做过的人根本没碰过数据这摊事。
踩雷答法:“我们把客服的历史聊天记录直接拿来训了。”——直接拿原始记录训,是新手最大的坑。
参考话术:
“微调要的是‘示范’不是‘资料’——是‘输入该对应什么理想输出’的成对数据,不是一堆文档。
原始数据我不会直接用。客服聊天记录里全是坑:老规则、错流程、坏话术、隐私信息,还有同一个问题好几种互相矛盾的答案。这些不清洗就训,模型会一起学进去。
我的流程是:先清洗去重、去掉过期规则和隐私信息、统一示范格式,再人工抽检标注质量,最后切训练集和测试集,测试集绝不能和训练集重叠。对我来说数据质量比数据量重要得多——脏数据不是资产,是污染源。”
能讲到数据清洗、去重、切分、失败样本回流这一层,面试官立刻知道你是真下场干过的。
# Q6:基模越来越强了,垂类微调还有必要吗?(成本 + 选型)
这道是最近特别流行的“开放题”,专门考你的判断力,没有标准答案。
踩雷答法:一边倒。要么“基模够强了,微调没必要了”,要么“当然有必要,微调永远有用”。两种都太绝对,显得没想过。
参考话术:
“我觉得要分开看:低质量微调会被抹平,高质量的行为/偏好/成本控制不会。
容易被抹平的是那些补通用能力的微调——拿几千条普通 QA 补知识、没有评测集只靠主观感觉、把动态业务规则硬训进去。这些基模一升级收益就没了,因为你补的正是基模迭代最快的部分。
不会被抹平的是:固定业务流程、品牌话术口径、安全拒答边界、用小模型降本、特定工具调用格式。这些不是‘基模更聪明’就能天然符合我业务的。
所以我的判断是——微调的价值正在从‘补能力’转向‘控行为、控偏好、控成本、控风险’。”
这道题的完整分析,我在面经里专门写过一篇 大模型微调面试详解,从“破局点”的角度展开了基模变强后该怎么答,想深聊这道题的录友可以去看。
# 五、那如果我真没做过微调呢?
很多录友卡在这儿:项目里压根没微调过,面试被问到怎么办?
最差的应对是硬编——编一个微调项目,编 rank、编指标。面试官随便一个追问就能戳穿,一旦发现你编,整场面试的可信度全没了。
正确的姿势有两个:
第一,诚实,但把诚实说得有水平。
别说“我没做过微调”就完了,要说:“这个项目我们评估过微调,但最后判断用 RAG + Prompt 更合适,所以没上微调。” 然后把 Q1 的选型逻辑讲出来。
你看,‘评估过但选择不做’本身就是工程判断力的体现,比硬编一个微调项目强得多。 面试官要的就是这个判断力。
第二,把相关的真实经验顶上去。
你可能没微调过,但大概率做过 RAG、调过 Prompt、搭过评估。这些能力是相通的——数据治理、指标体系、对比实验,RAG 项目里一样要做。把这些讲扎实,照样能证明你有工程能力。
记住:面试官不是非要你做过微调,是要你证明你有做微调所需要的那套判断力和工程素养。 这套东西,你在别的项目里练出来也算。
# 六、简历上的微调怎么写
最后说简历,因为面试的所有追问,都是从简历那一两行字开始的。
最致命的写法就一句话:
对 Llama3-8B 模型进行了 LoRA 微调
这一句几乎是在向面试官递刀子——它什么信息都没给,面试官只能顺着往下挖,而你大概率接不住。
按四要素简历的思路,微调项目至少要写清楚四件事:
- 微调了什么:什么任务、什么模型、为什么选微调而不是 RAG;
- 数据怎么构造:多少条、从哪来、怎么清洗标注;
- 超参怎么定:rank/alpha 设了多少、基于什么实验定的;
- 效果怎么样:和基线对比,哪个指标提升了多少。
一句话的“做了微调”和四要素的写法,面试体验天差地别——前者被追问到死,后者你早就把答案写在简历里了。
微调项目简历的反面/正面对比、指标到底怎么量化,我在简历专栏 微调项目简历怎么写 里有逐条拆解,正在改简历的录友直接去抄框架。
# 七、最后
应用开发者的微调面试,说到底比的不是你训得有多溜。
比的是你想得有多清楚:
这个需求该不该微调,数据靠不靠谱,收益怎么证明,成本划不划算。
这四个问题答利索了,就算你一行训练代码没写过,面试官也知道你是真懂大模型应用的人。
反过来,rank、alpha、PPO 背得再熟,一问“你怎么证明微调有收益”就卡壳,那就还是只会跑脚本。
守住选型、数据、评估、成本这四条线,红线以上答扎实,红线以下不硬装——这就是应用开发者面对微调题最稳的姿势。
评论
验证登录状态...