# 什么时候微调、什么时候RAG?选型决策框架

前两篇我们把微调讲透了。
SFT、RLHF、DPO 微调方法全景认知 讲的是微调有哪几类、各解决什么问题。
LoRA/QLoRA 低秩微调 讲的是真要动手训,具体怎么训才省。
但你有没有发现,这两篇都默认了一个前提:你已经决定要微调了。
可现实里,项目一开始你面对的根本不是"怎么微调"。
而是这个问题:
这个需求,到底该上 RAG,还是该微调?
这是大模型应用开发里最高频的架构选型题,也是面试官最爱问的一道。
“你这个项目为什么用 RAG,不用微调?”
“反过来,为什么微调,不用 RAG?”
“什么时候两个都要用?”
答不上来,前面 SFT、LoRA 背得再熟也白搭——因为你连第一步选型都没想清楚。
这篇我们就把这个框架建起来。
# 一、先破一个最常见的误解:微调 ≠ 给模型加知识
绝大多数人第一次纠结"微调还是 RAG",都是从一个错误前提出发的:
“模型不知道我们公司的业务,那我微调一下,让它把这些知识记住,不就行了?”
这个理解是错的,而且错得很彻底。
微调改的从来不是"模型知道什么",而是"模型怎么做"。
我们之前在 SFT 那一篇 反复强调过一句话:微调更常见的价值不是补知识,而是控行为。
你想让模型输出固定的 JSON 格式、想让它用客服那种语气说话、想让它在医疗/法律场景里有更专业的判断风格——这些是"行为",微调能搞定。
但你想让它知道"公司这周刚改的退款政策"、"这个客户签了哪几条合同"——这些是"知识",而且是会变的、私有的、要追溯来源的知识。
这种东西硬塞进参数里,是灾难:
- 知识一变就得重训,政策周一改了,你周二就得重新训一遍模型?
- 答错了无法追溯,模型张口就来,你不知道它依据的是哪份文档
- 还容易引发灾难性遗忘,为了记住新知识,反而把原来会的搞忘了
补这种知识,是 RAG 的活儿。我们在 为什么有了大模型还需要 RAG 里讲过它解决的正是这四个问题:幻觉、私有知识、时效性、可追溯。
所以微调和 RAG 的本质区别,一张图就能说清:
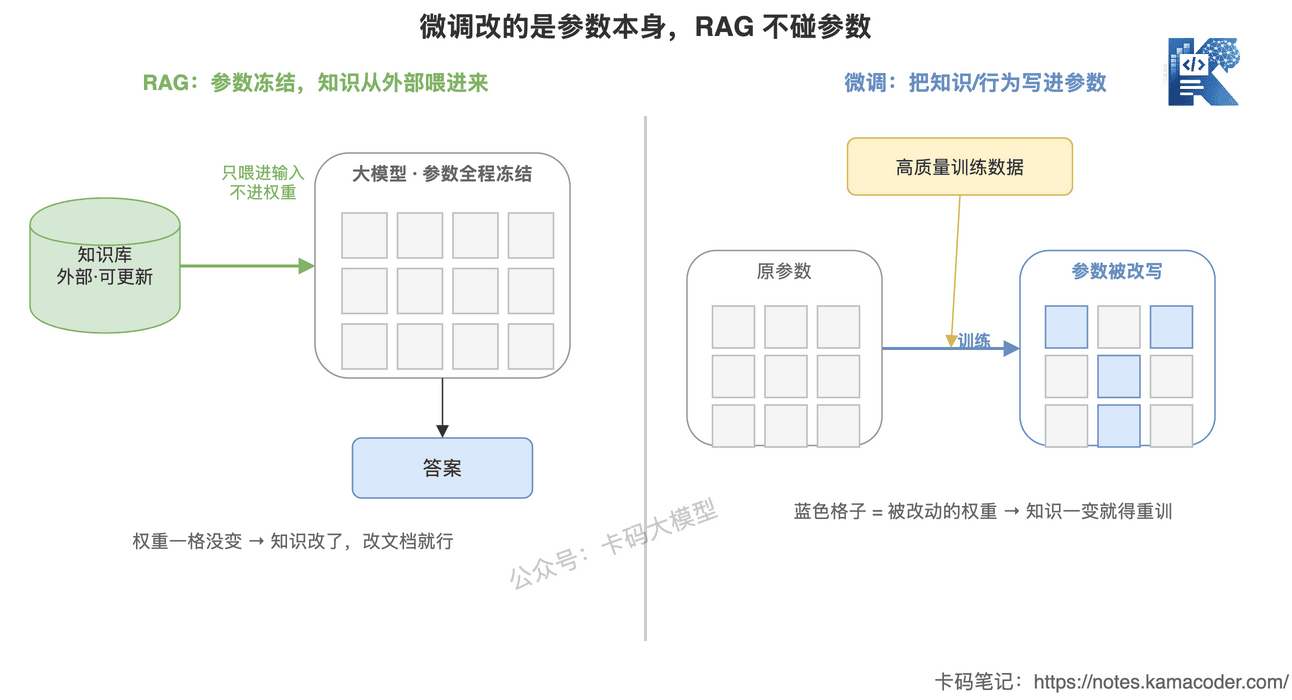
这张图回答的是:微调和 RAG 到底动了模型的什么。
看那一格格的方块,它代表模型的参数(权重)。
左边 RAG,那些格子从头到尾全是灰的、一格没变——模型参数全程冻结。它只是在运行时去知识库里检索,把查到的内容喂进输入,知识根本不进权重。所以知识改了,改文档就行,模型不用重训。
右边微调,格子有几个变成了蓝色——参数被实打实地改写了,行为焊进了权重。好处是稳定、不占上下文;代价是知识一变就得重训。
记住这条主线,下面所有判断都从它推出来:
缺知识,找 RAG;缺行为,才考虑微调。
# 二、一句话判断:你缺的是"知识"还是"行为"
很多复杂的选型题,其实一句话就能切开:
先问自己——现在效果不好,是因为模型"不知道",还是因为模型"做不好"?
模型"不知道",是知识问题:
- 它答不出公司内部文档里的内容
- 它说的产品信息是半年前的旧版本
- 它编造了一个根本不存在的条款
这些,RAG。
模型"做不好",是行为问题:
- 输出格式忽对忽错,没法被代码稳定解析
- 语气不对,太官方或者太随意
- 在你的专业领域里,判断风格不够地道
这些,微调(很多时候甚至 Prompt 就够,后面会讲)。
举个最容易混的例子。
你想做一个法律合同审查助手,效果不好。到底该 RAG 还是微调?
得拆开看:
- 如果是"它不知道最新的法律条文、不知道这家公司的历史合同" → 这是知识问题 → RAG
- 如果是"它知道条文,但审查报告写得乱七八糟、不像专业律师那个风格" → 这是行为问题 → 微调
同一个项目,不同的痛点,答案完全相反。
所以选型的第一步,永远是先定位问题,而不是先选方案。
# 三、四个维度,把选型量化下来
“知识 vs 行为”能解决大部分判断。
但面试官往往要你说得更细——具体从哪几个维度权衡?
给录友四个维度,对着打分就行:
| 维度 | 倾向 RAG | 倾向 微调 |
|---|---|---|
| 数据量 | 知识量大、文档海量,塞不进上下文 | 有几百到几千条高质量、带标注的示范数据 |
| 任务类型 | 缺的是事实知识,模型“不知道” | 缺的是行为能力(风格 / 格式 / 语气 / 专业度) |
| 更新频率 | 知识经常变,改一次就要马上生效 | 行为稳定,不会三天两头改 |
| 成本 | 起步快,改文档即可、无需训练 | 数据 + 训练 + 评估,一次性投入更高 |
四个维度分别往哪边倒,挨个说。
# 1. 数据量:你手里是"海量文档"还是"高质量示范"
- 知识量大、文档海量、根本塞不进上下文 → RAG。几千份文档你不可能训进参数,也不可能全塞进 Prompt,只能检索。
- 有几百到几千条高质量、带标注的示范数据 → 微调。微调吃的不是文档,是"输入→理想输出"的成对示范。
注意这里的关键词:微调要的是示范,不是资料。
你有 10 万字产品手册,那是资料,喂给 RAG。
你有 800 条"用户这么问、客服该这么答"的对话,那是示范,可以拿来微调。
# 2. 任务类型:补事实,还是改能力
这就是上一节"知识 vs 行为"的展开。
- 任务是补充事实知识(问答、查资料、找依据)→ RAG
- 任务是改变行为能力(固定格式、特定语气、专业判断、复杂指令遵循)→ 微调
一个判断小技巧:如果答案"对不对"取决于有没有查到正确资料,那是 RAG 的活;如果答案"好不好"取决于表达方式和专业度,那才轮到微调。
# 3. 更新频率:知识多久变一次
这个维度最容易被忽略,但它常常是压垮"微调灌知识"方案的最后一根稻草。
- 知识经常变、改一次就得马上生效 → RAG。改知识库里的文档,下一次检索立刻生效,秒级更新。
- 行为稳定、不会三天两头改 → 微调才划算。你不会每周改一次"客服该用什么语气"。
想象一下:用微调把价格表训进模型,结果运营每天调价。你每天重训一遍模型?光想想就知道这条路走不通。
凡是高频更新的东西,天然属于 RAG,不属于参数。
# 4. 成本:一次性投入 vs 长期维护
- RAG 起步快:搭好检索链路,之后改知识就是改文档,几乎零额外训练成本。
- 微调前期重:要准备标注数据、要训练、要评估,还要考虑模型迭代后的重训维护。
别只算训练那一下的钱。微调真正的成本在长期维护:基座模型升级了要不要跟着重训?数据漂移了要不要补训?这些都是持续投入。
四个维度看下来,你会发现一个规律:
它们其实指向同一个判断——你缺的到底是"知识"还是"行为"。 数据量、更新频率、成本,都是在帮你确认这件事,而不是四个独立的投票项。
# 四、选型决策流程:先 Prompt,再 RAG,最后才微调
定位完问题,还有一个顺序问题。
很多录友一遇到效果不好,第一反应就是"上微调"。
这是新手最典型的毛病:一上来就掏最重的武器。
正确的顺序是按成本从低到高试:
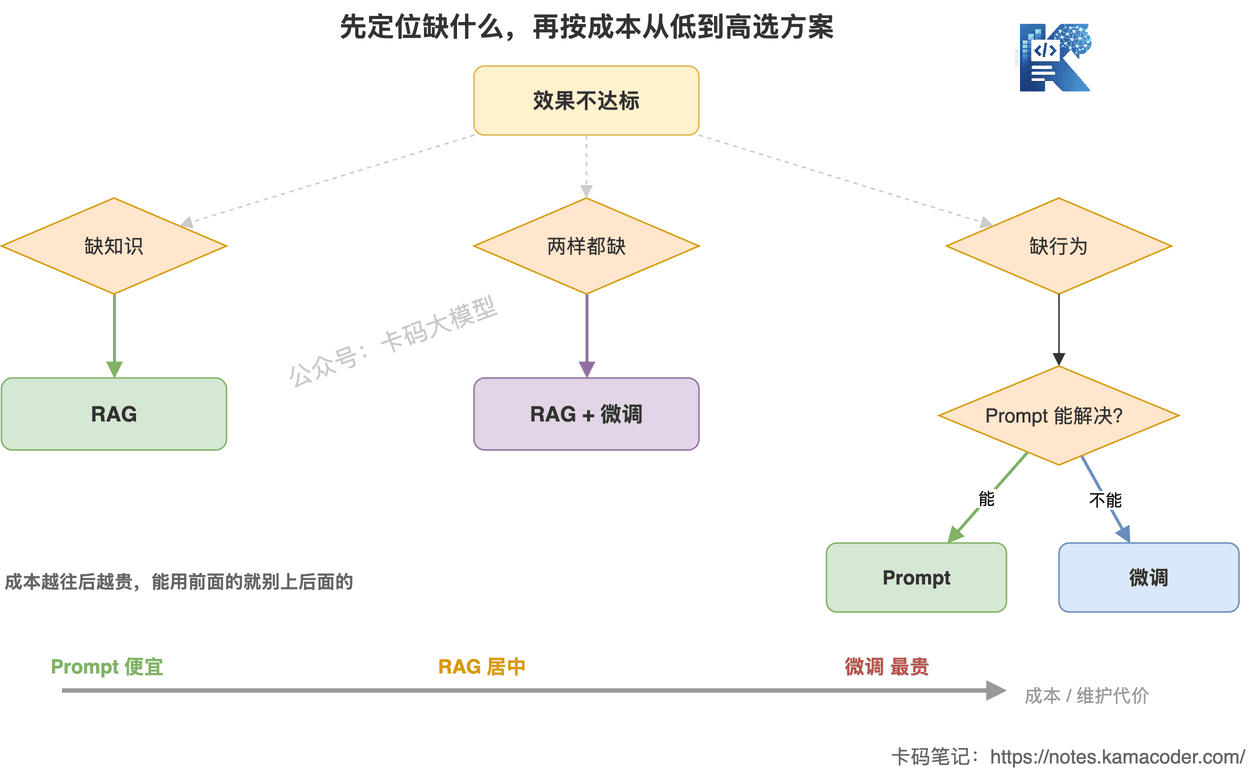
这张图回答的是:拿到一个不达标的需求,该按什么顺序决策。
第一步,缺什么,先定位。 是缺知识、缺行为,还是两样都缺。
- 缺知识 → RAG。可更新、可追溯,不用动模型。
- 两样都缺 → RAG + 微调一起上(下一节细讲)。
- 缺行为 → 先别急着微调,再问一句:Prompt / few-shot 能不能调好?
- 能 → 就用 Prompt。改个提示词、给两个示例就能解决的事,犯不上训模型。很多"格式不稳"的问题,其实 结构化输出 + JSON Schema 就治好了。
- 不能,且手里有示范数据 → 这才轮到微调。
记住这条成本线:
Prompt < RAG < 微调。
能用 Prompt 解决的,不上 RAG;能用 RAG 解决的,不上微调。
为什么强调这个顺序?因为微调是这三者里最贵、最难维护、最容易翻车的一个。它该是你试过前两步都不行之后的选择,而不是第一选择。
面试时你要是能主动说出"我会先评估 Prompt 和 RAG 能不能解决,确实不行才考虑微调",面试官立刻知道你是干过活的,不是只会背名词。
# 五、真相:现实里常常是 RAG + 微调一起上
讲到这你可能以为这是道单选题。
不是。
真实的复杂系统,往往两个都要。
因为前面反复说的那条主线:RAG 管知识,微调管行为。一个系统完全可能既要新知识,又要稳行为。
这时候就别二选一了,让它们各管各的:
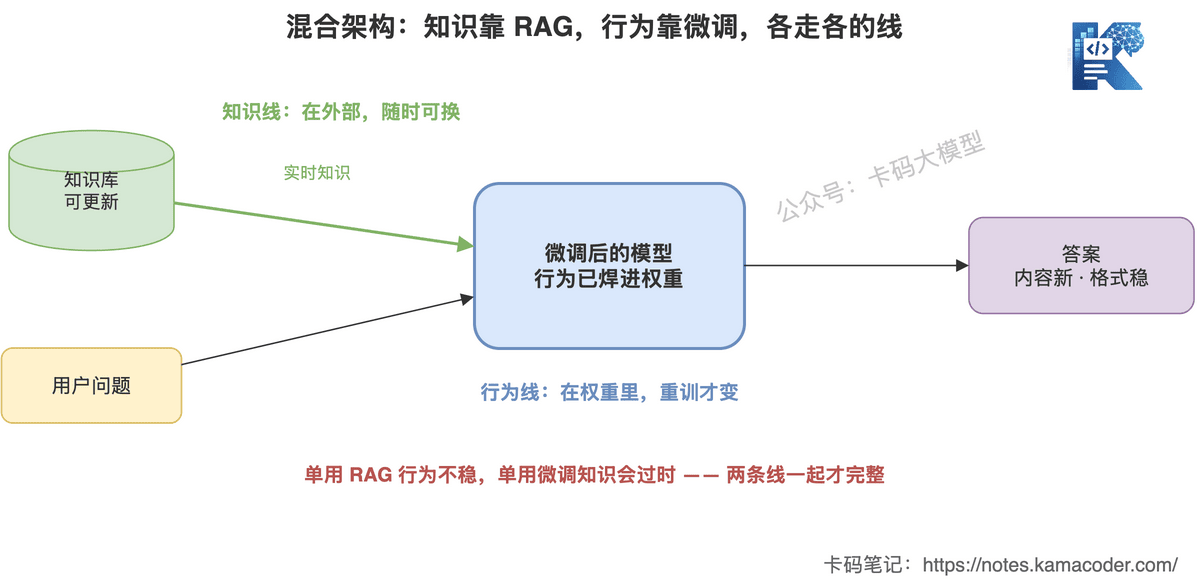
这张图回答的是:两者怎么配合在一条链路里。
用户问题进来,RAG 负责知识线:去知识库检索最新、最准的资料,拼进 context。这条线保证内容是新的、可追溯的。
微调负责行为线:处理这些 context 的,是一个已经被微调对齐过的模型,它懂这个领域该用什么格式、什么语气、什么专业判断。这条线保证输出是稳的、地道的。
最后出来的答案,内容是新的(RAG 给的),格式是稳的(微调给的)。
举个具体场景。
一个金融领域的智能投顾助手:
- 行情、政策、产品信息每天在变 → 这部分靠 RAG,实时检索
- 但回答必须符合合规话术、专业风格、固定的风险提示格式 → 这部分靠 微调,焊进模型行为
你单用 RAG,知识够新但话术不专业、格式不合规;你单用微调,话术专业但知识永远停在训练那天。
两条线各管各的,才是成熟系统的样子。
# 六、几个典型场景,对号入座
光讲框架太虚,给录友几个高频场景直接套:
- 企业内部文档问答(几千份手册、规范、合同):知识为主、海量、常更新 → 纯 RAG
- 客服话术固定、输出格式严格(知识不多但行为要稳):先试 Prompt,搞不定再 微调
- 垂直领域专业助手 + 实时数据(法律/医疗/金融):既要专业行为又要新知识 → RAG + 微调
- 代码/文案风格统一(要模型学会某种固定风格,知识需求低):微调(或 LoRA 多适配器,参考 LoRA 篇 讲的一基座多适配器)
- 只是偶尔答不准、格式偶尔崩(问题不严重):大概率 Prompt 优化 就够,别动不动就训模型
你会发现,真正"非微调不可"的场景,比想象中少得多。 大量需求 Prompt + RAG 就解决了。
这也是为什么我一直跟录友说:别一遇到问题就想着微调,那往往是想偏了。
# 七、面试怎么答
如果面试官问:
“你这个项目,为什么用 RAG 不用微调?”或者“什么时候该微调,什么时候该 RAG?”
可以这样答:
“我判断的核心是先定位问题:模型效果不好,是因为它'不知道',还是因为它'做不好'。
如果是缺知识——比如要回答公司内部文档、实时数据、要能追溯来源——我用 RAG。因为这类知识量大、会变、还要可追溯,硬训进参数代价太高,改一次就得重训,还可能引发灾难性遗忘。RAG 改文档就能秒级更新。
如果是缺行为——比如要固定输出格式、特定语气、专业判断风格——我会先看 Prompt 和 few-shot 能不能解决,因为它最便宜。Prompt 搞不定、又有高质量示范数据,才上微调,把行为对齐进模型。
具体我会从四个维度权衡:数据量是海量文档还是少量高质量示范,任务是补事实还是改行为,知识更新频率高不高,以及一次性和长期维护的成本。
成本上我的优先级是 Prompt < RAG < 微调,能用前面的解决就不上后面的。
很多复杂项目其实是 RAG + 微调一起用:RAG 管实时知识,微调管稳定行为,两条线各管各的。比如我这个项目就是……”
然后接你自己的项目细节。
这个回答能体现四件事:
第一,你懂微调和 RAG 的本质区别(改参数 vs 不改参数,行为 vs 知识)。
第二,你有量化的判断维度,不是拍脑袋。
第三,你懂成本意识(先 Prompt 再 RAG 最后微调)。
第四,你知道现实是混合架构,不是单选题。
比一句"我们用了 RAG"或者"我们做了微调"强太多。
# 八、最后
选型这道题,难的从来不是知道 RAG 和微调各是什么。
难的是遇到具体需求时,你能不能一眼看穿——它缺的到底是知识,还是行为。
这一句想清楚了,剩下的都是顺水推舟:
缺知识,RAG。
缺行为,先 Prompt,不行再微调。
两样都缺,一起上。
别再一遇到问题就喊微调了。最贵的方案,应该是你最后的选择,不是第一反应。
评论
验证登录状态...