# SFT、RLHF、DPO:微调方法全景认知

上一篇我们讲了 Agent 怎么评估。
评估这件事很重要,因为大模型应用不是“看起来能答”就算完成。
到了微调这一章,更是这样。
很多录友一听到微调,就会觉得这是算法岗的事情,应用开发不用管。
也有人反过来,简历里写“对模型做了微调”,但面试官追问一句:
“你们为什么要微调?SFT、RLHF、DPO 分别解决什么问题?为什么不用 RAG?”
然后就卡住了。
这就很可惜。
应用开发者不一定要亲手训一个百亿模型,但必须知道:
微调到底在改变模型什么,什么问题适合微调,什么问题根本不该微调。
这篇我们不推公式。
也不把论文名词堆满。
我们就把 SFT、RLHF、DPO 这三类方法讲清楚。
看完以后,录友至少要能回答四个问题:
- SFT 是在教模型什么?
- RLHF 和 DPO 为什么都叫偏好对齐?
- PPO、Reward Model 在 RLHF 里到底是什么位置?
- 真实项目里,Prompt、RAG、SFT、DPO、RL 到底怎么选?
# 一、先建立全局图:微调不是“给模型塞知识”
很多人对微调的第一反应是:
“模型不知道我们公司的业务,那就微调一下,让它记住。”
这个理解太粗了。
微调更常见的价值,不是补知识,而是控行为。
知识会变。
产品规则、价格、库存、组织架构、政策条款,这些都可能更新。
这类东西硬训进模型里,后面规则一变,模型参数里的旧知识还在,很难清干净。
之前讲 为什么有了大模型还需要 RAG 时说过,RAG 更适合处理外部知识、私有知识、动态知识。
微调更适合处理另外一类问题:
- 模型明明知道规则,但输出格式总是不稳
- 模型能回答,但话术不符合业务口径
- 模型会做任务,但步骤顺序经常乱
- 多个答案都没错,但业务更偏好其中一种
- 小模型能力不够,想学习大模型在固定任务上的回答范式
你看,这些问题都不是“知道不知道”。
而是“怎么做、怎么答、怎么选”。
所以先记住一句话:
RAG 解决外部知识进入上下文的问题,微调解决模型行为模式被参数吸收的问题。
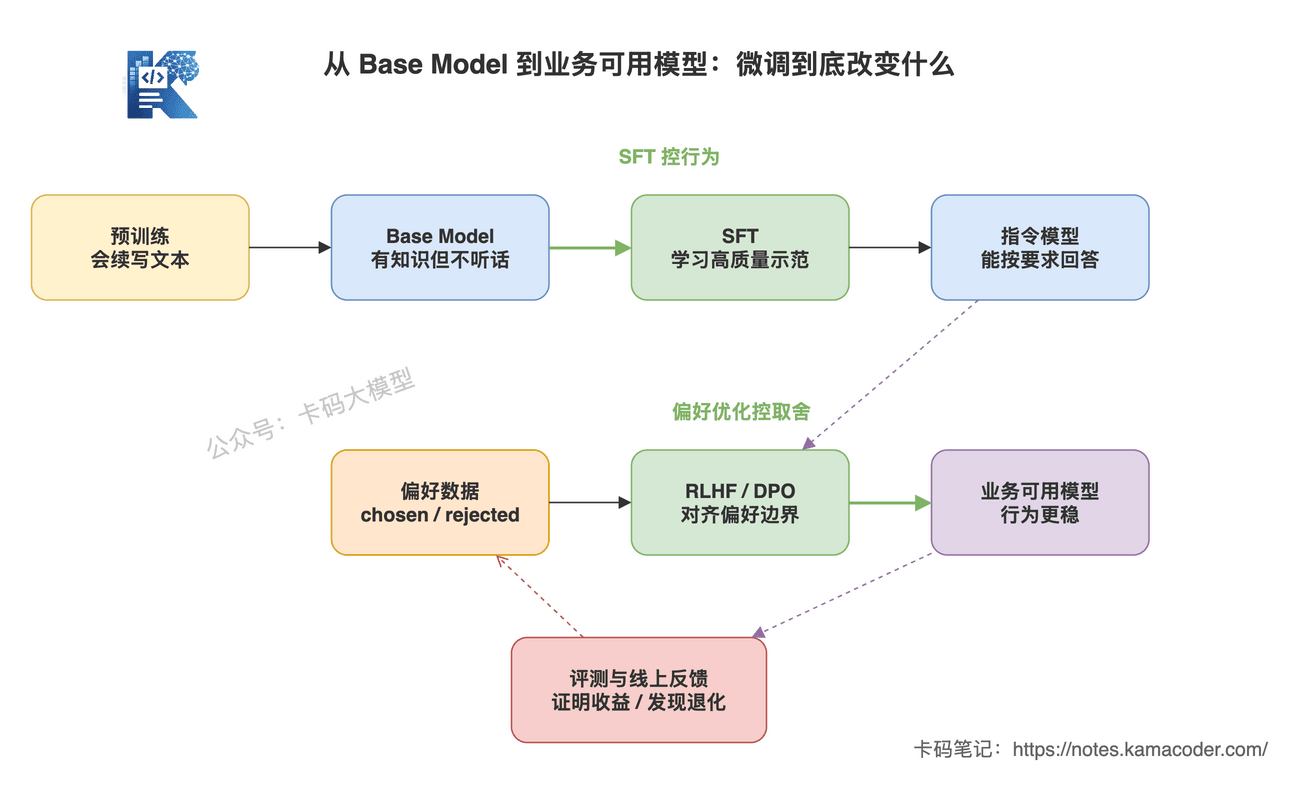
这张图回答的是:从 Base Model 到可用助手,SFT、RLHF、DPO 分别改变哪一层能力。
它不是把方法名字排一排,而是强调一条路径:
预训练让模型会续写,SFT 让模型学会按指令回答,RLHF/DPO 让模型更符合人类或业务偏好,最后还必须用评测和线上反馈证明收益。
# 二、SFT:给模型看高质量示范
SFT,全称是 Supervised Fine-Tuning,监督微调。
一句话解释:
SFT 就是给模型看“输入应该怎么对应输出”的高质量示范,让模型模仿这种回答方式。
比如客服退款场景。
用户说:
“我这个订单能退吗?”
一个差的回答是:
“能退。”
一个更好的示范是:
“请先提供订单号,我会查询订单状态、支付时间和商品类型,再根据平台退款规则判断是否满足退款条件。”
SFT 数据就是大量这种“问题 + 标准回答”。
模型看多了以后,会学到:
- 遇到退款问题,不要直接下结论
- 先收集订单号
- 再查订单状态
- 最后按规则判断
这就是 SFT 的本质:学示范。
# SFT 适合什么
SFT 适合相对稳定、示范明确、可批量构造数据的任务。
比如:
- 固定 JSON 输出
- 工单分类
- 信息抽取
- 固定客服话术
- 工具调用格式
- 简历点评风格
- 小模型学习大模型输出范式
这些任务的共同点是:你能写出“好答案长什么样”。
只要能稳定写出好示范,SFT 就有发挥空间。
# SFT 不适合什么
SFT 不适合把动态知识硬塞进模型。
比如:
- 商品价格
- 库存状态
- 最新政策
- 公司制度
- 合同条款
- 产品功能说明
这些信息变化频繁。
今天训练进去,明天就可能过期。
这类场景更应该用 RAG、数据库查询、工具调用。
SFT 教模型“怎么答”,RAG 给模型“答题资料”。
这个边界一定要分清。
# SFT 的风险
SFT 最大的坑是数据质量。
很多团队拿客服聊天记录直接训。
看起来数据很多,其实里面全是坑:
- 老规则
- 错流程
- 坏话术
- 隐私信息
- 人工客服随口说的话
- 同一个问题多种互相矛盾的答案
这些东西不清洗就训,模型会一起学进去。
脏数据不是资产,是污染源。
所以 SFT 项目里,最重要的不是“我训了多少条”。
而是:
- 数据从哪里来
- 怎么清洗
- 怎么去重
- 怎么标注质量
- 怎么切训练集和测试集
- 怎么做失败样本回流
面试里讲到这里,才像真的做过。
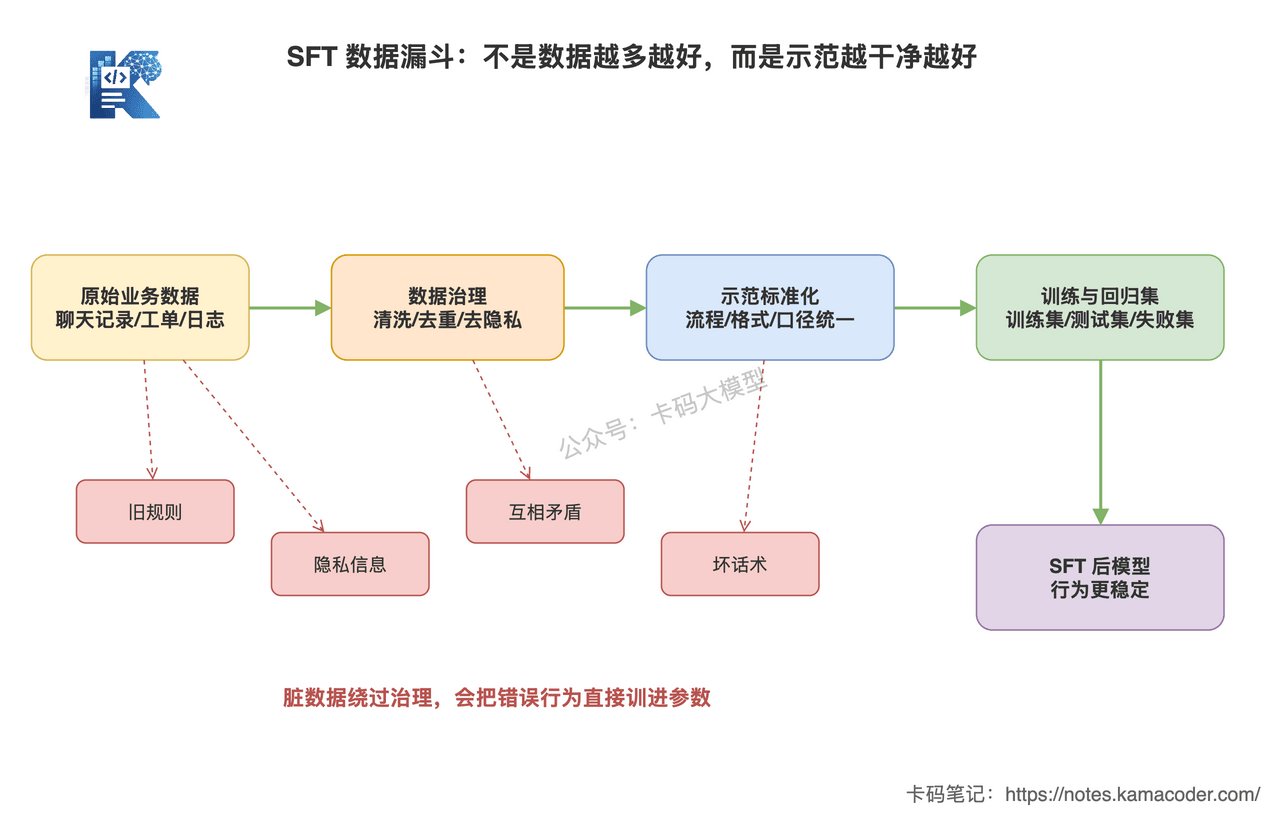
这张图回答的是:为什么 SFT 的关键不是“数据越多越好”,而是原始业务数据必须经过清洗、去旧、去隐私、统一示范格式,最后再进入训练和评测。
图里红色虚线表示脏数据如果绕过治理,会直接污染模型行为;绿色实线表示有效的 SFT 数据生产路径。
# 三、RLHF:让模型学会“人更喜欢哪个答案”
RLHF,全称 Reinforcement Learning from Human Feedback,基于人类反馈的强化学习。
一句话解释:
RLHF 不是给模型一个标准答案,而是告诉模型:多个候选答案里,人类更喜欢哪一个。
比如同一个投诉问题,模型给了两个回答。
A:
“不符合规则,不能退。”
B:
“我理解你现在比较着急。退款需要先确认订单状态和商品类型,如果不满足自动退款条件,我可以帮你看是否需要转人工处理。”
这两个回答不一定是“一个绝对错,一个绝对对”。
但业务可能明显更喜欢 B。
因为 B 更稳、更礼貌,也给了后续处理路径。
这就是偏好问题。
# RLHF 的典型流程
传统 RLHF 大概是这条链路:
- 先用 SFT 训练一个能按指令回答的模型
- 对同一个问题生成多个候选回答
- 人类标注哪个回答更好
- 用偏好数据训练 Reward Model
- 再用 PPO 这类强化学习算法优化模型
- 用评测集和线上指标检查有没有训歪
这里有两个容易混的词:Reward Model 和 PPO。
Reward Model 是“评分器”。
它学习人类偏好,给模型输出打分。
PPO 是“优化算法”。
它根据 Reward Model 的分数更新模型,同时限制模型不要偏离原模型太远。
为什么要限制?
因为模型很容易钻 reward 的空子。
如果 Reward Model 偏爱长答案,模型可能开始写一堆废话。
如果 Reward Model 偏爱礼貌语气,模型可能每句话都客气到离谱。
所以 PPO 里通常会控制模型不要一下子偏离太远。
面试里不用推公式,讲清楚这层关系就够了:
RLHF 用人类偏好训练奖励模型,再用强化学习算法让模型更偏向高奖励回答。
# RLHF 适合什么
RLHF 适合“没有唯一标准答案,但有明显偏好”的问题。
比如:
- 回答要更礼貌还是更直接
- 拒答边界要更保守还是更开放
- 客服先安抚还是先解释规则
- 医疗问答要不要主动提醒就医
- Agent 失败时是继续尝试还是停下来追问
这些不是简单的知识题。
它们更像价值判断、风格选择、风险偏好。
所以 RLHF 的关键词是:偏好对齐。
# RLHF 的成本
RLHF 很重。
重在三件事:
第一,人类偏好标注贵。
第二,Reward Model 自己也可能学偏。
第三,PPO 训练和调参复杂,容易不稳定。
所以真实项目里,除非你有足够大的数据量、团队能力和业务收益,不要一上来就喊 RLHF。
很多应用团队更现实的路线是:
先 Prompt 和 RAG。
再 SFT。
有稳定偏好数据后,再考虑 DPO。
只有任务足够大、反馈足够强、收益足够明确,才考虑完整 RLHF 或更广义的 RL。
# 四、DPO:跳过 Reward Model 的轻量偏好优化
DPO,全称 Direct Preference Optimization,直接偏好优化。
一句话解释:
DPO 直接用“好回答 vs 差回答”的偏好对训练模型,让模型更倾向于好回答,不再单独训练 Reward Model,也不走复杂 PPO 流程。
它仍然需要偏好数据。
比如:
同一个问题下:
- chosen:更符合业务偏好的回答
- rejected:不符合偏好的回答
DPO 直接吃这种数据。
训练目标就是让模型以后更倾向 chosen,而不是 rejected。
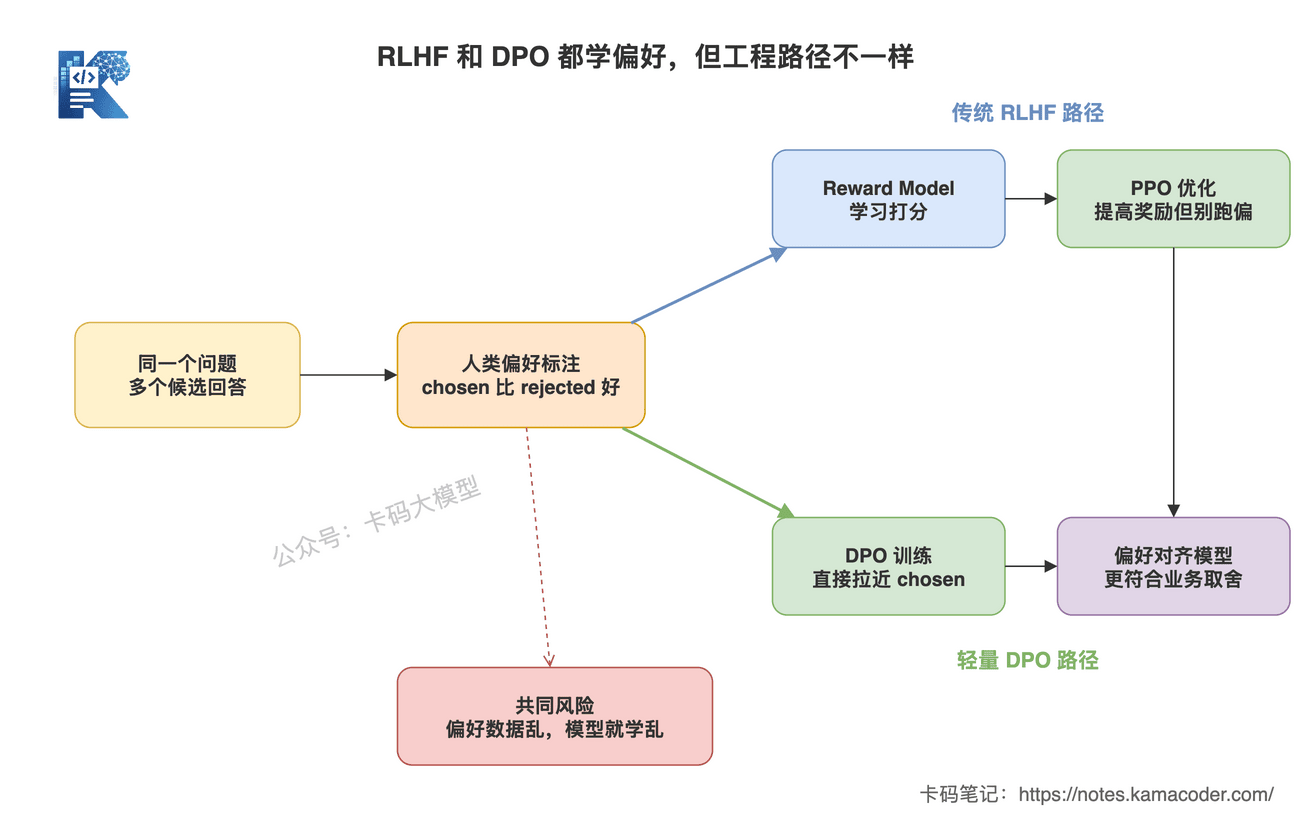
这张图回答的是:RLHF 和 DPO 都在做偏好优化,但工程路径不同。
RLHF 先把人类偏好学成 Reward Model,再通过 PPO 优化模型;DPO 直接从偏好对更新模型。两者都依赖偏好数据,区别在于中间有没有单独的奖励模型和强化学习阶段。
# DPO 为什么火
因为它工程上更轻。
传统 RLHF 要训练 Reward Model,还要跑 PPO。
DPO 省掉了中间很多复杂环节。
对应用团队来说,这很现实:
- 训练流程更短
- 调参压力更小
- 稳定性通常更好
- 更容易基于已有偏好数据落地
所以如果你已经有一批可靠的偏好对,比如客服好坏回答、合规/不合规回答、正确/错误工具调用轨迹,DPO 是一个更容易起步的选择。
# DPO 的边界
DPO 不是万能替代 RLHF。
它的前提是偏好数据质量足够高。
如果标注标准混乱,DPO 也会学乱。
今天标注员喜欢简洁,明天标注员喜欢详细。
今天认为应该拒答,明天又认为应该给建议。
这种数据进去以后,模型就会左右摇摆。
还有一种场景,DPO 不一定够。
比如 Agent 多步执行。
模型不是只输出一个回答,而是要在环境里连续行动:
理解任务 → 选择工具 → 填参数 → 读取结果 → 判断下一步 → 完成任务
如果你要优化的是整个任务完成率、工具调用成功率、错误恢复能力,只靠静态偏好对可能不够。
这时更需要真实环境反馈和轨迹级评估。
# 五、RL:只有 reward 清楚,才值得上强度
很多人把 RLHF 和 RL 混在一起。
其实 RLHF 是 RL 的一种路线。
RL 更宽。
一句话解释:
RL 是让模型在环境里做动作,环境给奖励,模型学会让长期奖励更高。
它不一定要人类偏好。
只要 reward 能定义,就可以有 RL。
比如代码任务:
- 编译通过,奖励高
- 单测通过,奖励高
- 代码报错,奖励低
比如数学任务:
- 最终答案正确,奖励高
- 推理过程违反约束,奖励低
比如 Agent 工具调用:
- 工具选对,奖励高
- 参数合法,奖励高
- 成功完成任务,奖励高
- 越权动作,严重惩罚
这些任务更适合 RL。
因为 reward 相对客观。
但如果 reward 很模糊,只是“我感觉这个回答更好”,直接上 RL 就很危险。
模型会为了拿高分钻规则漏洞。
这就是常说的 reward hacking。
所以 RL 的核心不是“高级”。
而是:
你有没有一个清晰、稳定、可验证的奖励信号。
没有这个,RL 只会把问题放大。
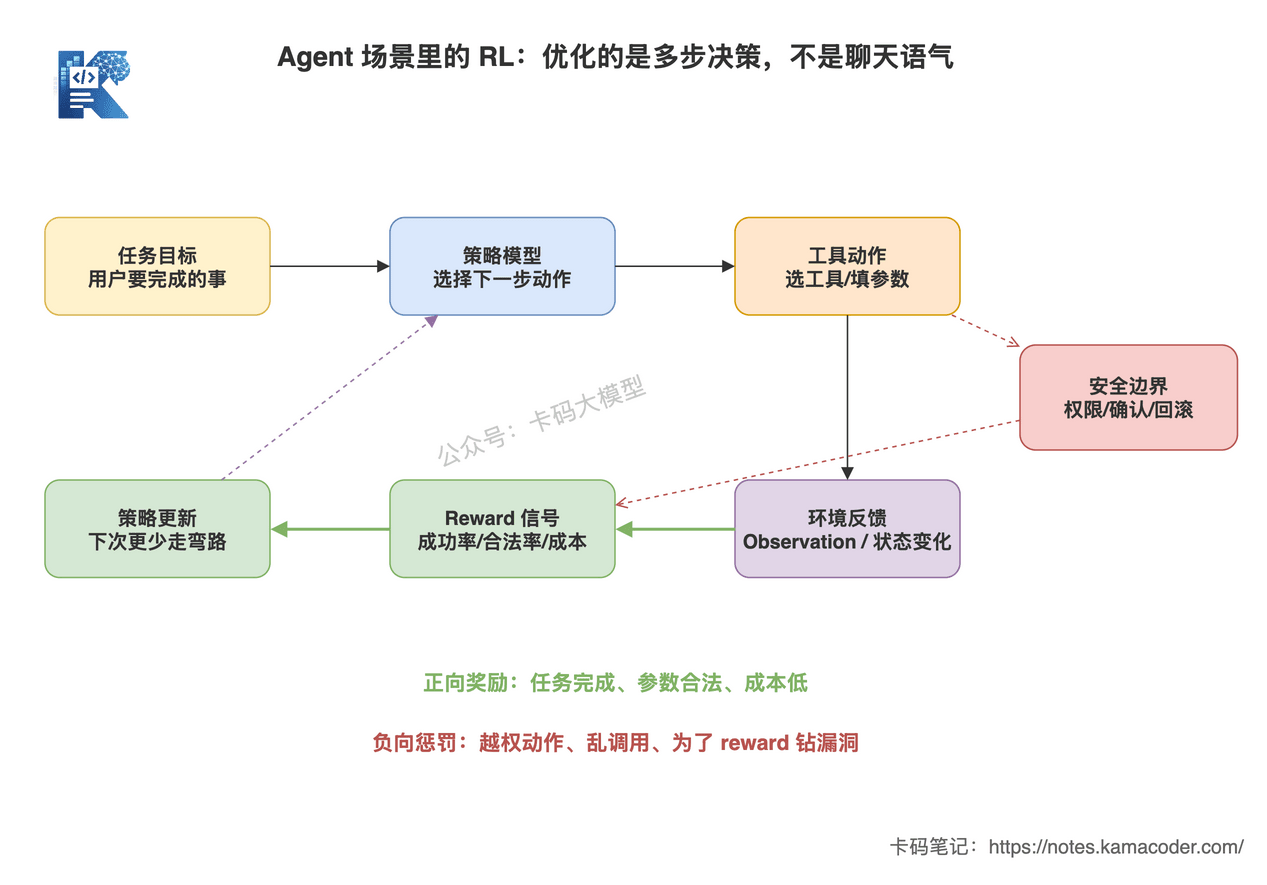
这张图回答的是:Agent 场景里 RL 为什么不是“让模型更会聊天”,而是把工具选择、参数合法性、任务完成率、越权风险这些环境反馈变成 reward,再反过来优化多步决策。
图里绿色箭头表示可验证的正向奖励,红色虚线表示越权、乱调用、reward hacking 这类必须被惩罚或拦截的路径。
# 六、Prompt、RAG、SFT、DPO、RL 到底怎么选
这是面试和真实项目里最常见的问题。
别一上来就说微调。
也别所有问题都说 RAG。
我建议按问题性质判断。
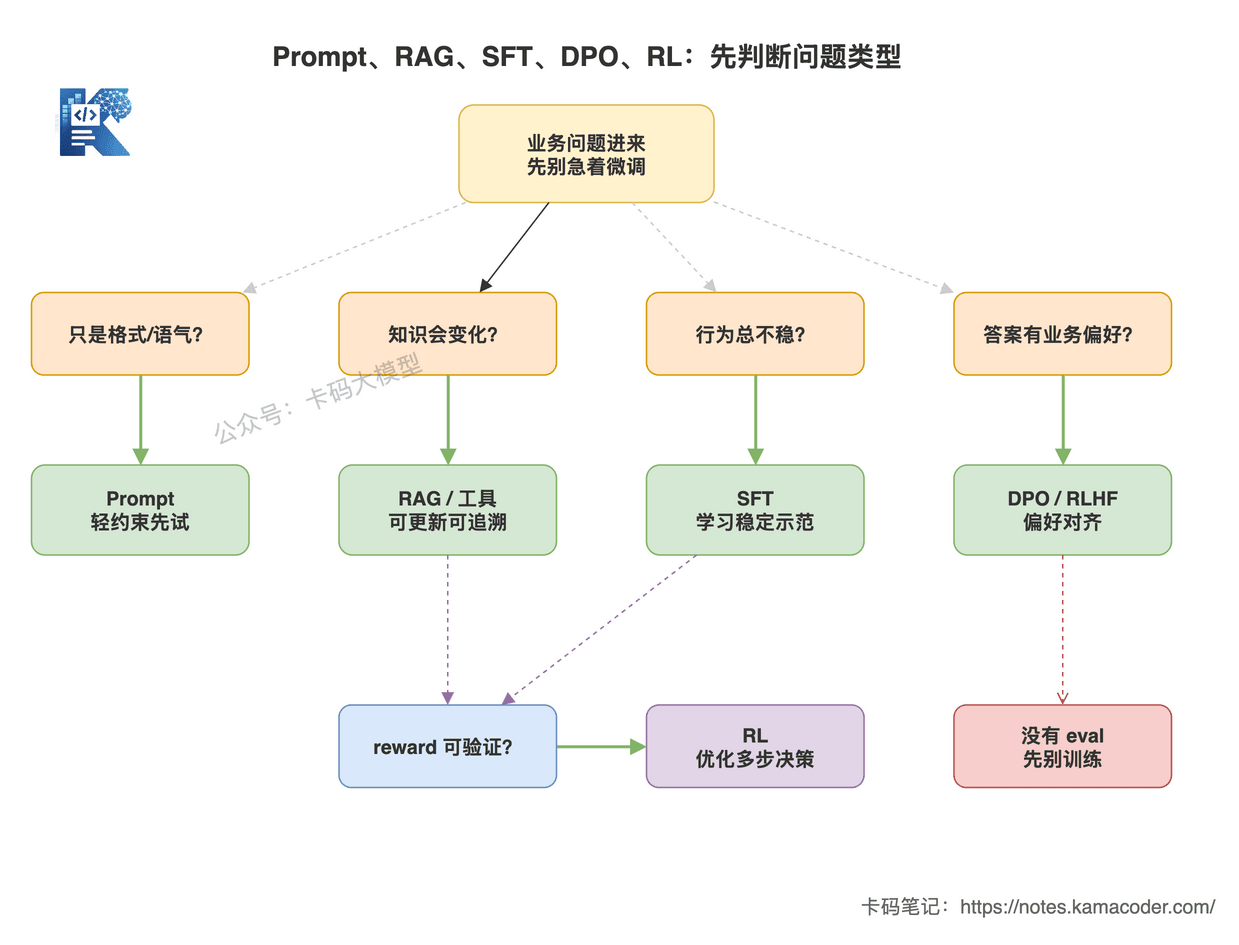
这张图回答的是:一个大模型应用问题进来后,应该先判断它到底是格式问题、知识问题、行为问题、偏好问题,还是可验证决策问题。
不同问题对应不同工具:Prompt 先做轻约束,RAG/工具处理动态知识,SFT 稳定行为,DPO/RLHF 对齐偏好,有明确 reward 再考虑 RL。
# 1. 只是表达和格式问题,先用 Prompt
比如:
- 先给结论再解释
- 输出 JSON
- 不知道就说不知道
- 回答控制在 200 字以内
- 只根据给定材料回答
这些优先 Prompt。
Prompt 能稳定解决,就不要训练。
训练会引入数据、成本、版本、评测、回滚问题。
# 2. 是动态知识问题,优先 RAG 或工具
比如:
- 查商品价格
- 查订单状态
- 查公司制度
- 查文档条款
- 查知识库答案
这些优先 RAG 或工具。
因为知识要可更新、可追溯、可替换。
微调不是知识库。
# 3. 是稳定行为问题,再考虑 SFT
比如:
- 输出格式总是不稳
- 任务步骤经常乱
- 工具调用参数总不规范
- 固定场景话术不统一
这时 SFT 有价值。
因为你要让模型把固定行为模式学进参数里。
# 4. 是偏好问题,考虑 DPO 或 RLHF
比如:
- 两个回答都能用,但业务更喜欢其中一种
- 拒答尺度要更保守
- 客服回答要先安抚再处理
- 安全场景要更符合合规口径
这不是简单示范问题。
这是偏好问题。
有稳定偏好对,可以先考虑 DPO。
如果业务规模很大、偏好反馈体系成熟,再考虑完整 RLHF。
# 5. 有可验证 reward,才考虑 RL
比如:
- 单测是否通过
- 检索是否命中
- 工具调用是否成功
- Agent 任务是否完成
- 风险动作是否被拦截
这些有明确反馈,才有 RL 的土壤。
否则别为了显得高级硬上。
# 七、基模越来越强,微调还有没有必要
这是现在面试很爱问的问题。
“通用基模越来越强了,垂类 SFT、RLHF、DPO 会不会被抹平?”
答案是:
低质量微调会被抹平,高质量行为控制不会。
什么微调容易被抹平?
- 用几千条普通 QA 补通用知识
- 没有评测集,只靠主观感觉
- 把动态业务规则训进模型
- 数据质量低,答案互相矛盾
- 基模一升级,收益就消失
这种微调确实越来越不值钱。
因为你补的是通用能力,而通用能力正是基模迭代最快的部分。
但还有一些价值不会自动被基模抹平:
- 业务固定流程
- 品牌话术口径
- 安全拒答边界
- 小模型降本
- 工具调用格式
- Agent 多步决策偏好
- 线上失败样本回流
这些不是“基模更聪明”就一定能天然符合你的业务。
所以更准确的说法是:
微调的价值正在从补能力,转向控行为、控偏好、控成本、控风险。
这个判断,比简单说“微调有用”或者“微调没用”更像工程答案。
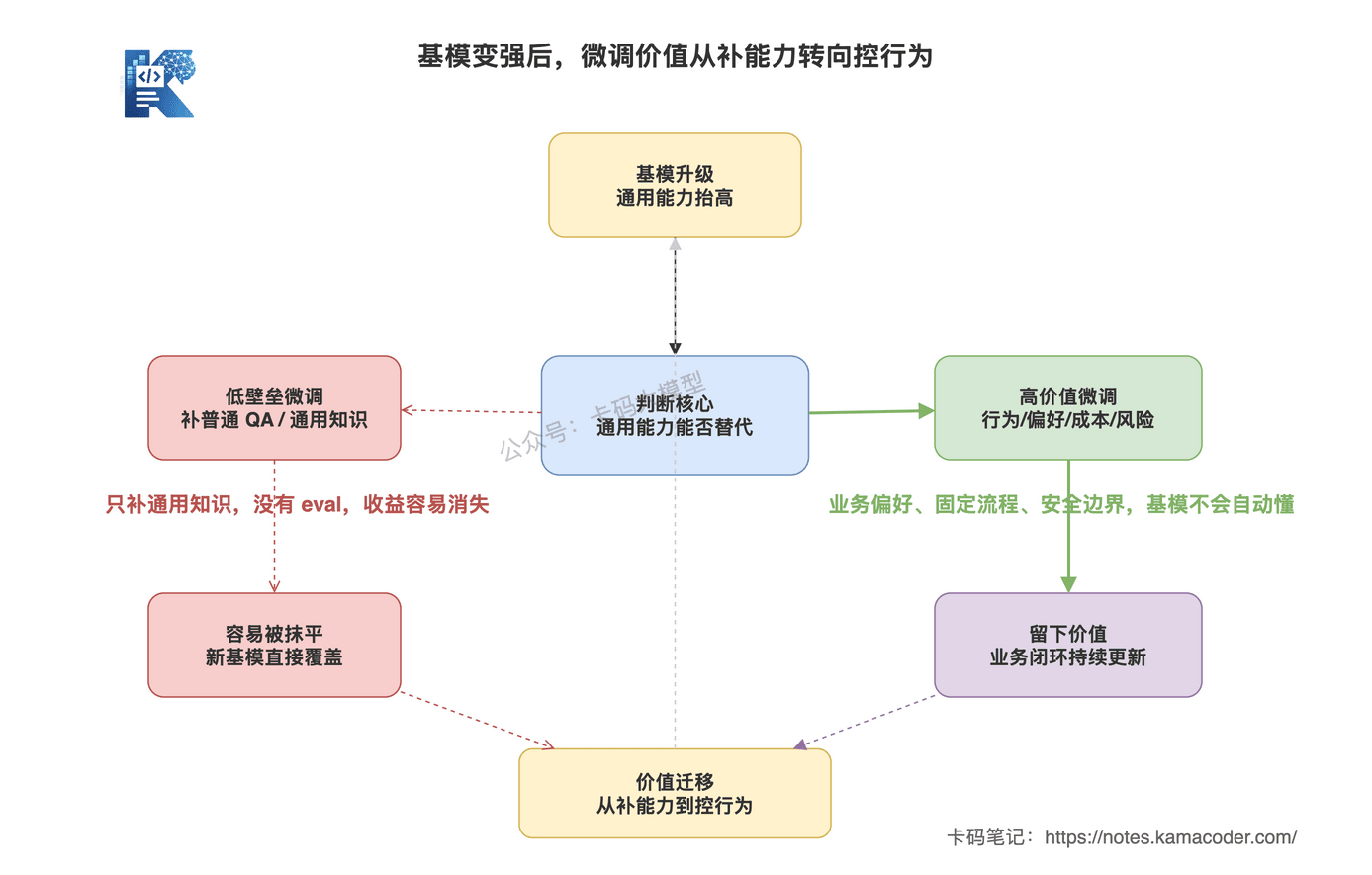
这张图回答的是:基模变强后,哪些微调价值会被抹平,哪些价值会留下来。
图里红色路径表示低壁垒的“补通用知识”微调被新基模覆盖,绿色路径表示业务行为、偏好、成本和风险控制这些更稳定的微调价值。
# 八、工程上怎么证明微调有收益
微调最怕一句话:
“感觉效果好了。”
这不是工程结论。
微调前后,至少要看四类指标。
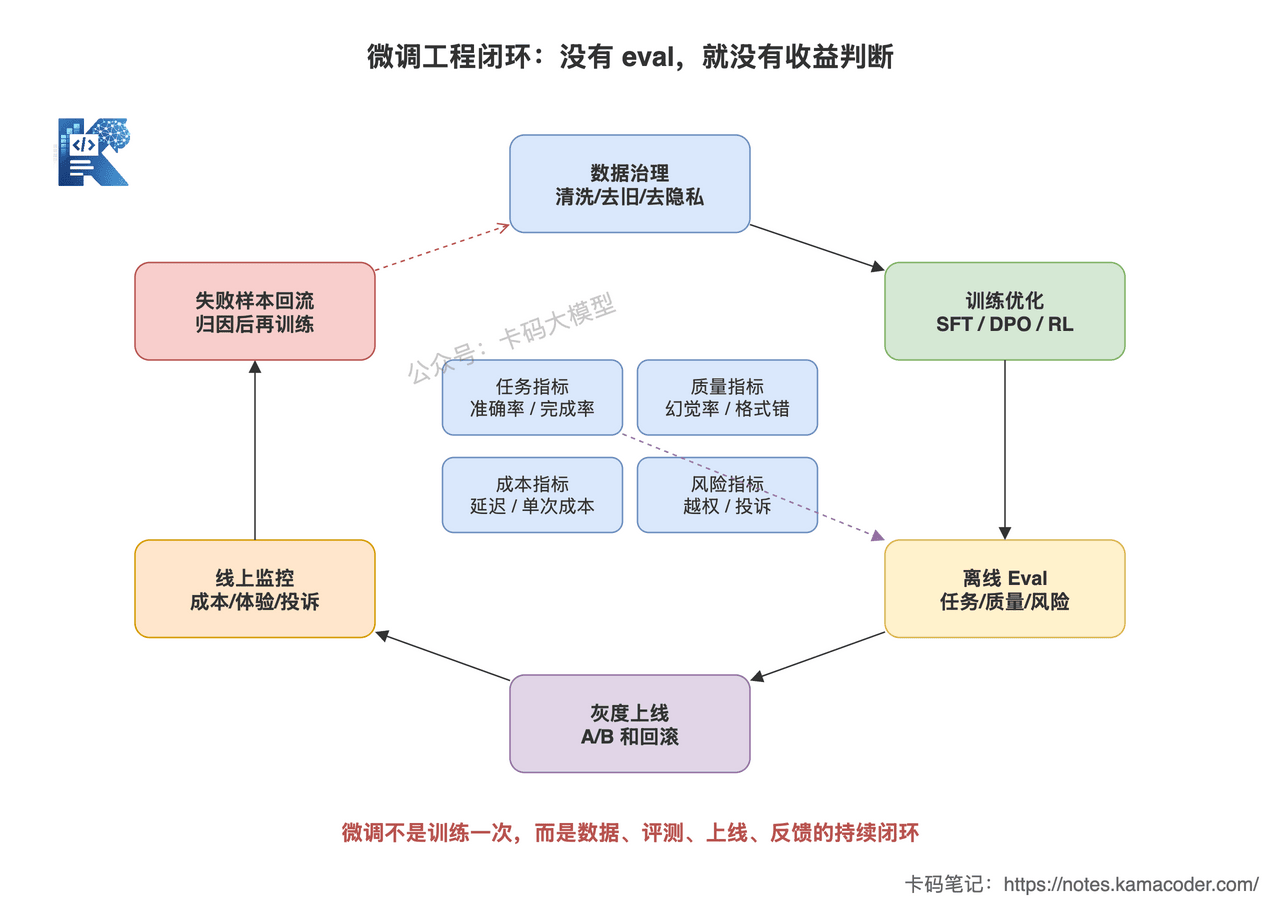
这张图回答的是:微调不是训练一次就结束,而是数据治理、训练、离线评测、灰度上线、线上监控、失败样本回流的闭环。
如果没有 eval 和反馈回流,就无法判断 SFT、DPO 或 RL 到底有没有真实收益。
# 1. 任务指标
看任务本身有没有提升。
比如:
- 分类准确率
- 信息抽取 F1
- JSON 合法率
- 工具调用成功率
- 任务完成率
- 用户问题解决率
这些是最基础的指标。
# 2. 质量指标
看回答质量有没有提升。
比如:
- 幻觉率
- 格式错误率
- 无证据回答率
- 错误拒答率
- 人工接管率
- 高风险问题处理正确率
尤其是 RAG 和 Agent 项目,不能只看用户满意度。
还要看证据链和执行轨迹。
# 3. 成本指标
微调很常见的目标是降本。
比如:
- 单次调用成本下降多少
- 延迟降低多少
- 小模型承接多少流量
- 大模型调用量减少多少
如果效果差不多,但成本降了一半,这也是非常实在的收益。
# 4. 风险指标
高风险业务要看风险有没有下降。
比如:
- 越权动作率
- 错误放行率
- 错误拒答率
- 投诉率
- 回滚次数
- 审批触发率
微调不能只追求“答得更像人”。
它还要让系统更稳。
# 5. 回归测试
每次换 Prompt、换 RAG、换工具、换模型、做微调,都要跑回归。
否则很容易出现:
这个场景好了,另一个场景坏了。
训练集效果提高了,线上真实问题变差了。
格式更稳了,但拒答边界被破坏了。
所以要有固定回归集。
尤其要保留历史失败 case。
失败样本不是垃圾,是下一轮优化最值钱的数据。
# 九、面试里怎么讲
如果面试官问:
“你怎么看 SFT、RLHF、DPO?它们分别适合什么场景?”
可以这样答:
“我会先把微调分成几类问题来看。
SFT 本质是监督微调,适合让模型学习高质量示范。它更适合固定输出格式、固定任务流程、工具调用范式、行业话术和小模型蒸馏,不适合把频繁变化的业务知识硬塞进模型。动态知识我会优先用 RAG 或工具查询。
RLHF 解决的是偏好对齐问题。它不是给模型唯一标准答案,而是通过人类偏好让模型知道多个候选答案里哪个更符合人类或业务偏好。传统流程通常会训练 Reward Model,再用 PPO 这类强化学习算法优化模型。
DPO 也是偏好优化,但工程路径更轻。它直接用 chosen/rejected 这种偏好对训练模型,省掉单独训练 Reward Model 和 PPO 的复杂流程。所以如果团队已经有高质量偏好数据,我会优先考虑 DPO,而不是一上来做完整 RLHF。
更广义的 RL 只有在 reward 清楚时才值得做,比如代码单测、数学答案、Agent 工具调用成功率、任务完成率这类可验证目标。reward 模糊时强行上 RL,很容易训歪。
所以我不会把微调理解成‘给模型补知识’。基模越来越强后,低质量垂类微调确实容易被抹平,但控行为、控偏好、控成本、控风险仍然有价值。最后是否值得做,要看评测集、线上指标、成本收益和风险指标,而不是靠主观感觉。”
这个回答能体现三件事。
第一,你知道概念。
第二,你知道边界。
第三,你知道工程落地要用指标说话。
这比背 SFT、RLHF、DPO 的定义有用得多。
# 十、最后提醒
录友一定要记住:
微调不是大模型应用的默认选项。
很多问题,Prompt、RAG、工具、规则、工作流就能解决。
但微调也不是没用。
当你要把稳定行为、业务偏好、风险边界、成本结构沉进模型里,微调就有价值。
关键不是会不会喊 SFT、RLHF、DPO。
关键是你能不能说清楚:
为什么要训,训什么,怎么评估,失败了怎么回滚。
这才是工程里的微调认知。
评论
验证登录状态...