# LoRA/QLoRA:为什么低秩微调这么流行

上一篇我们讲了 SFT、RLHF、DPO 微调方法全景认知。
那一篇解决的是“微调要做什么”的问题。
这一篇解决“微调具体怎么训”的问题。
因为不管你是做 SFT,还是做 DPO,真到了动手那一步,几乎都绕不开一个词:
LoRA。
现在你去看任何一个开源微调项目、任何一个垂类模型训练教程,十有八九用的都是 LoRA 或 QLoRA。
为什么?
因为它便宜。
便宜到什么程度?
原来要 8 张 A100 才能训的模型,用 QLoRA 一张消费级显卡就能跑起来。
这就是它流行的根本原因。
但便宜不等于你就懂了。
面试官最爱在这里挖坑:
“你用 LoRA 训的?那 rank 设的多少?为什么是这个值?”
“lora_alpha 是干嘛的?”
“你 LoRA 加在哪些层上?”
“QLoRA 和 LoRA 差在哪?量化的是哪部分?”
这几个问题,能把“只会跑脚本”的人和“真懂原理”的人一秒区分开。
这篇我们不推公式。
就把 LoRA 和 QLoRA 讲到你能自己回答上面这些问题。
# 一、先搞清楚:全参微调到底贵在哪
要理解 LoRA 为什么省,得先知道全参微调为什么贵。
很多人以为微调贵是因为“模型参数多”。
这只说对了一半。
真正吃显存的,不只是模型权重本身。
我们以一个 7B 模型为例,用最常见的 Adam 优化器,按 FP16 精度算一笔账:
- 模型权重:7B 参数,约 14GB
- 梯度:每个参数都要存一份梯度,又是约 14GB
- 优化器状态:Adam 要为每个参数存动量和方差两份,约 28GB(甚至更多,常用 FP32 存)
光这三块加起来就奔着 70GB 去了。
还没算前向传播的激活值。
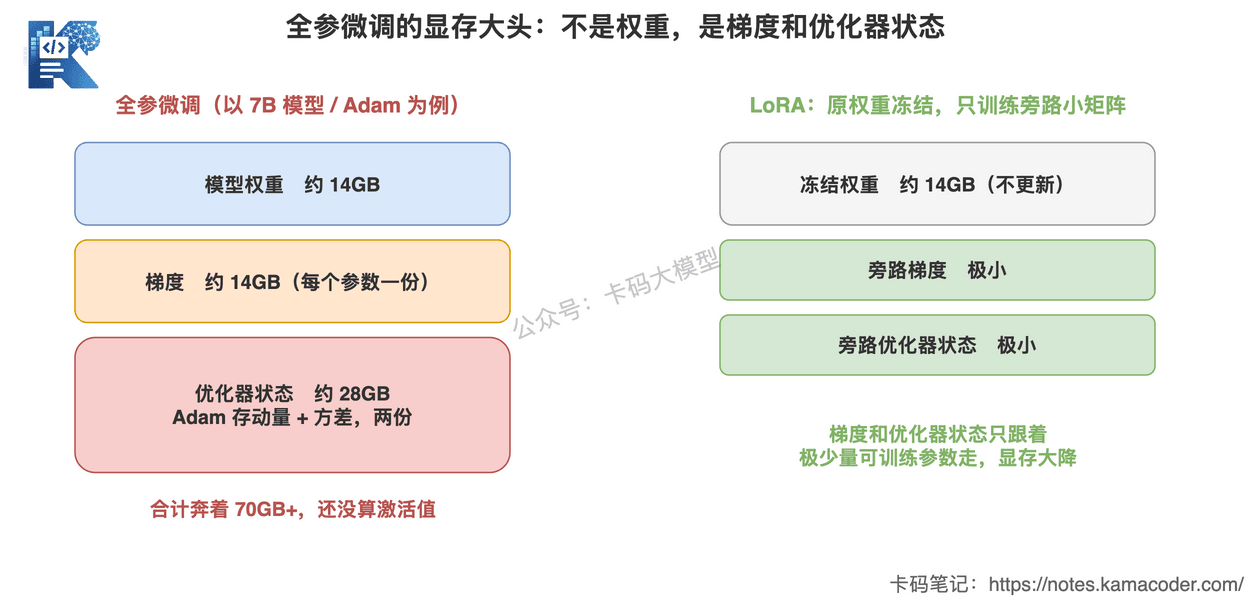
这张图回答的是:全参微调的显存大头不是模型权重,而是梯度和优化器状态。
你看,权重只占一份,但梯度是一份,Adam 优化器状态是两份。 真正训练时,可训练参数的“伴生开销”比权重本身还大。
所以核心矛盾很清楚:
只要你要更新全部参数,梯度和优化器状态就甩不掉,显存就降不下来。
那有没有办法,只更新一小部分参数,让梯度和优化器状态只跟着这一小部分走?
这就是 LoRA 的出发点。
# 二、LoRA 的核心思想:冻结原权重,只学一个“增量”
LoRA 全称 Low-Rank Adaptation,低秩适配。
它的想法特别朴素,可以拆成两句话:
第一,原来的模型权重全部冻结,一个都不动。
第二,在旁边新加两个小矩阵,只训练它们,用它们表示“权重需要变化的部分”。
我们用数学符号说一遍,但别怕,就一个式子。
原来一层的权重是 W,微调本质上是想得到一个新权重:
W_new = W + ΔW
全参微调直接去改 W,所以 ΔW 和 W 一样大。
LoRA 不改 W,而是说:这个变化量 ΔW,我用两个小矩阵的乘积来近似。
ΔW = B × A
其中:
- A 的形状是 r × d
- B 的形状是 d × r
- 中间这个 r,就是大名鼎鼎的 rank(秩),而且 r 远小于 d
训练的时候,W 冻结不动,只更新 A 和 B。
推理的时候,把 W + B×A 合并起来用,效果上等价于一个被微调过的权重。
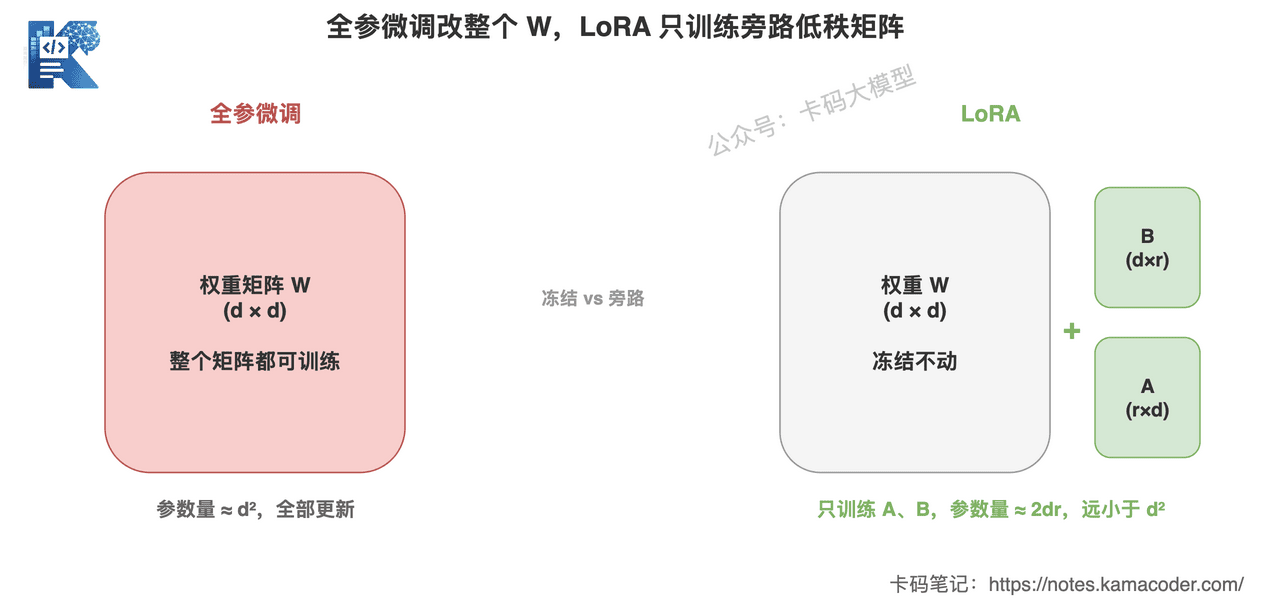
这张图回答的是:全参微调和 LoRA 到底改的是哪部分。
左边全参微调,整个 W 矩阵都是可训练的(红色)。右边 LoRA,原始 W 被冻结(灰色),只有旁路那两个又瘦又小的 A、B 矩阵在训练(绿色)。
参数量的差距有多大?
假设 d = 4096,全参微调这一层要更新 4096 × 4096 ≈ 1678 万个参数。
LoRA 如果取 r = 8,只需要更新 4096×8 + 8×4096 ≈ 6.5 万个参数。
少了 250 多倍。
可训练参数少了 250 倍,意味着梯度和优化器状态也跟着少 250 倍。
显存自然就下来了。
# 三、为什么“低秩”就够用了
这里很多录友会有一个本能的怀疑:
“你用一个这么小的矩阵去近似一个大矩阵,信息不会丢吗?效果能行吗?”
这是个好问题。
答案藏在一个观察里:
大模型在适配下游任务时,权重真正需要改变的方向,其实没那么多。
换句话说,微调带来的权重变化量 ΔW,虽然形状很大,但它“本质上”是个低秩矩阵——它真正有效的信息维度很低。
打个比方。
预训练好的模型已经会了 99% 的通用能力。
你做微调,不是把它重新教一遍,而是在原有能力上做一点“微调整”。
这点调整,用不着动用一个满秩的大矩阵。
一个低秩矩阵就能把这个“调整方向”表达得差不多。
![]()
这张图回答的是:为什么两个瘦长的小矩阵相乘,能顶替一个大矩阵的更新。
一个 d×d 的大矩阵,被拆成 d×r 和 r×d 两个小矩阵。中间的 r 就像一个瓶颈,强制让信息从一个很窄的通道流过。这个瓶颈逼着模型只学最关键的变化方向,而不是漫无目的地乱改。
所以低秩不是“偷工减料”。
它是一个假设:微调要学的东西,本来就是低维的。
实践证明,这个假设在绝大多数下游任务上都成立。
# 四、rank 和 alpha:面试最爱挖的两个参数
理解了原理,再看参数就简单了。
LoRA 最核心的两个超参数,就是 r(rank)和 lora_alpha。
# rank 怎么理解、怎么设
rank 就是上面那个瓶颈的宽度。
rank 越大,旁路矩阵能表达的变化越丰富,但可训练参数也越多。
- rank 太小(比如 1、2):表达能力可能不够,复杂任务学不到位
- rank 太大(比如 256):参数变多,省显存的优势变小,还可能过拟合小数据集
那到底设多少?
给录友一个实践区间:
大多数场景,rank 取 8、16、32 就够了。
- 任务简单、数据少:8 起步
- 任务复杂、数据多、和预训练分布差异大:可以加到 16、32、64
- 上到 128 以上,往往说明这个任务可能本就不适合 LoRA,该考虑全参微调了
面试官问“rank 设多少”,他想听的不是一个数字。
他想听你知不知道这个数字背后的权衡:
“rank 控制的是低秩矩阵的表达能力。我会从 8 或 16 起步,根据任务复杂度和验证集表现往上调。如果调到很大才有效果,说明 LoRA 的低秩假设在这个任务上不太成立,我会重新评估是不是该上全参微调。”
这样答,就到位了。
# alpha 又是干嘛的
lora_alpha 是一个缩放因子。
LoRA 旁路的输出,实际上会乘上 alpha / r 这个系数,再加回主干。
W_new = W + (alpha / r) × B × A
你可以把它理解成这条旁路的“音量旋钮”。
它控制 LoRA 学到的东西,以多大的强度叠加到原模型上。
实践里有个常见经验:
alpha 通常设成 rank 的 2 倍左右。 比如 rank=8 配 alpha=16,rank=16 配 alpha=32。
为什么要除以 r?
因为这样当你调大 rank 时,旁路输出的整体幅度不会跟着剧烈变化,调参更稳定,不至于换个 rank 就得重调学习率。
面试时能说清“alpha/r 是缩放,目的是让 rank 变化时训练更稳定”,就比只会填默认值的人强一截。
# 还有一个常被忽略的:加在哪些层
LoRA 不是无脑加在所有层上。
它有一个 target_modules 参数,决定旁路矩阵挂在哪些权重上。
- 最早的 LoRA 论文主要加在注意力的
q_proj、v_proj上 - 现在更常见的做法是加全一点:
q/k/v/o加上 FFN 的几个投影层 - 加的层越多,可训练参数越多,效果可能更好,但开销也更大
这也是一个权衡点。
面试里如果你能主动提一句“我把 LoRA 加在了注意力和 FFN 的投影层上”,会显得你真的调过,而不是套了个默认配置。
# 五、QLoRA:把“便宜”再往死里压一压
LoRA 已经把可训练参数砍到很小了。
但还有一座大山没搬走:
那个被冻结的原始模型,本身还是要完整加载进显存的。
7B 模型光权重就 14GB,70B 模型权重就 140GB。
虽然它冻结了、不参与梯度更新,但你总得把它放进显存里做前向传播吧?
QLoRA 解决的就是这个问题。
QLoRA = Quantization + LoRA,量化 + 低秩适配。
它的核心操作只有一句话:
把那个冻结的基座模型,用 4bit 量化压缩后再加载,而 LoRA 旁路矩阵仍然用较高精度训练。
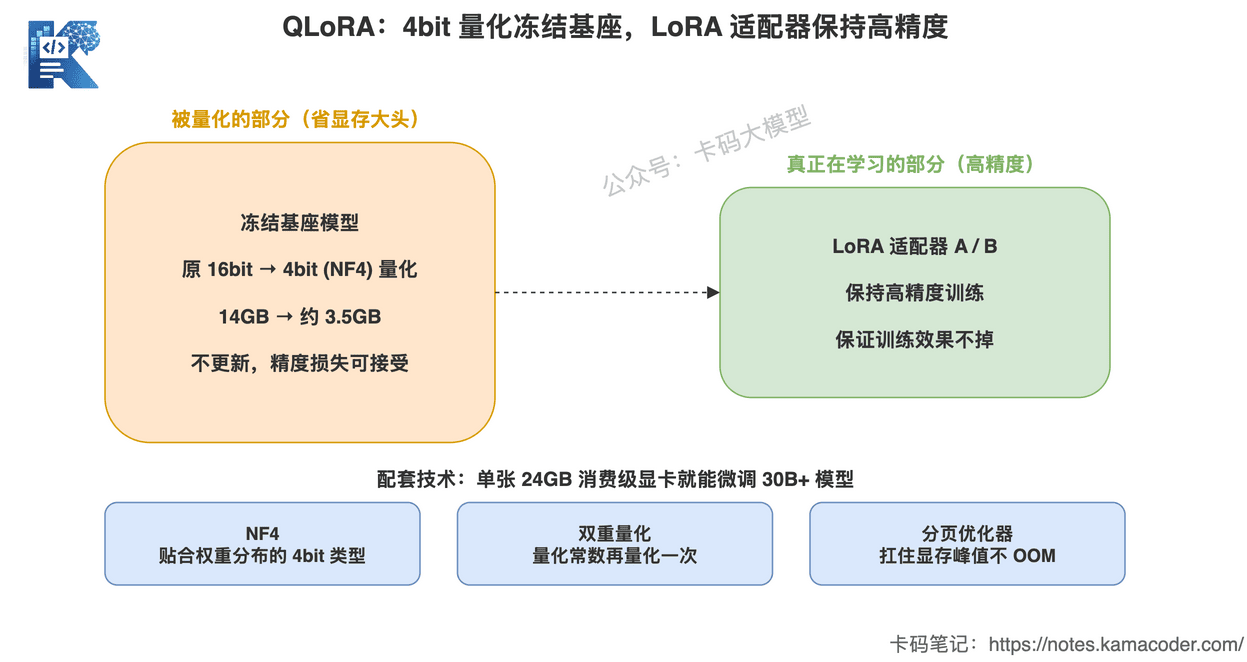
这张图回答的是:QLoRA 到底量化了哪一部分。
注意看,被压成 4bit 的是冻结的基座(反正它不更新,精度损失一点可以接受)。而真正在学习的 LoRA 适配器保持高精度,保证训练效果不掉。
这一压,效果立竿见影:
- 原始权重从 16bit 压到 4bit,显存直接降到约四分之一
- 14GB 的 7B 模型,量化后只占 3.5GB 左右
- 配合 LoRA 本身极小的可训练参数
最终结果就是:单张 24GB 的消费级显卡,能微调 30B 甚至更大的模型。
这就是为什么 QLoRA 一出来,垂类微调的门槛被砸穿了。
普通人、小团队,也能在自己的卡上训模型了。
# QLoRA 的几个关键技术点
面试如果深问 QLoRA,能甩出这几个词会很加分:
- NF4(4-bit NormalFloat):一种专门为正态分布权重设计的 4bit 量化数据类型,比普通的 int4 更贴合大模型权重的实际分布,精度损失更小
- 双重量化(Double Quantization):连量化时产生的那些量化常数本身也再量化一次,进一步省一点显存
- Paged Optimizer(分页优化器):借助显存分页机制,应对训练中偶发的显存峰值,避免 OOM 直接崩掉
你不用记住每个细节的实现。
但知道“QLoRA 不只是简单粗暴地砍精度,而是用 NF4 这种更聪明的量化方式尽量保住效果”,就够回答面试了。
# QLoRA 的代价
天下没有免费的午餐。
QLoRA 省显存,但也有代价:
- 训练速度通常比 LoRA 慢一些:因为前向传播时要不断把 4bit 权重反量化回计算精度
- 精度上理论上略有损失:虽然 NF4 已经做得很好,但 4bit 终究比 16bit 信息少
所以选型逻辑很清楚:
显存够用,优先 LoRA;显存实在不够、卡不够大,再上 QLoRA 用时间换空间。
# 六、LoRA 还有一个被低估的好处:部署灵活
很多人只看到 LoRA 省训练显存。
其实它在部署上还有一个杀手锏。
因为 LoRA 训出来的,只是那两个小矩阵——通常就几十 MB 到几百 MB。
基座模型一点没变。
这意味着什么?
一个基座模型,可以同时挂载多个不同的 LoRA 适配器,按业务需求随时切换。
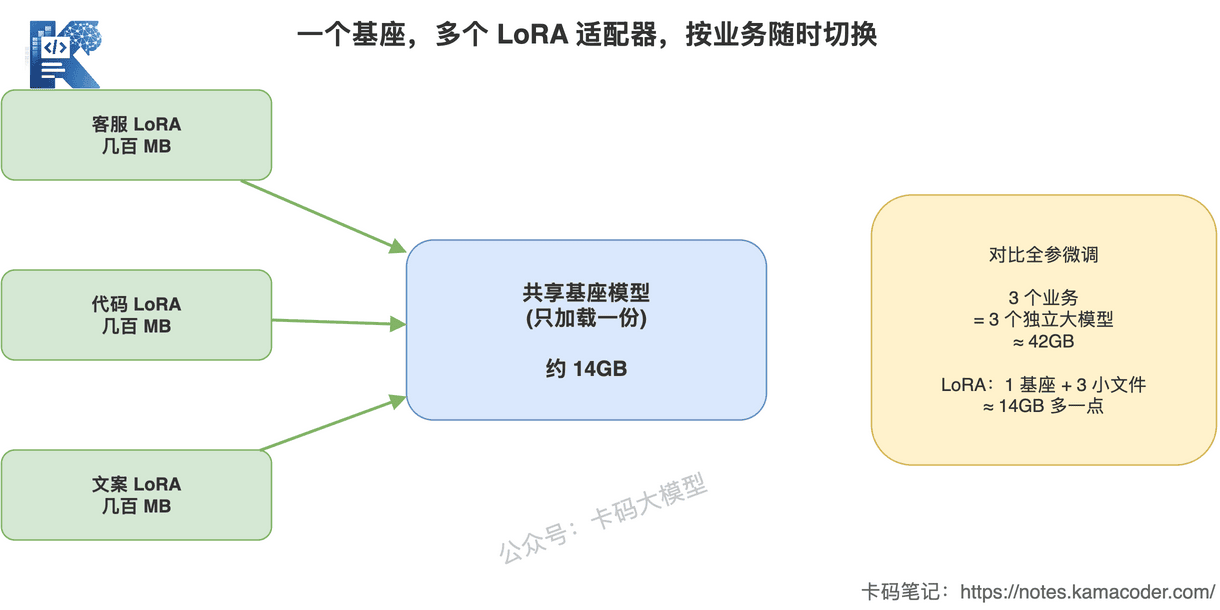
这张图回答的是:为什么 LoRA 在多业务场景下特别省。
中间是一个共享的基座模型,旁边挂着客服 LoRA、代码 LoRA、文案 LoRA 等好几个小适配器。请求来了,需要哪个能力就挂哪个,基座只加载一份。
对比一下全参微调:
- 全参微调每个业务都得存一整个独立的大模型
- LoRA 只需存一个基座 + 多个几百 MB 的小适配器
三个业务,全参微调要存 3 个 7B 模型(约 42GB),LoRA 只要 1 个基座加 3 个小文件(约 14GB 多一点)。
这种“一基座多适配器”的模式,在真实生产环境里非常实用。
也是面试时能体现你“懂工程落地”的好料。
# 七、LoRA 不是万能的:什么时候它不够
讲了这么多好处,也得说清楚边界,不然就成吹了。
LoRA 有它的适用范围。
下面这些情况,LoRA 可能不够,要考虑全参微调:
- 任务和预训练分布差异极大:比如把一个通用中文模型硬改成一个全新的小语种、或一种全新的领域语言,低秩假设可能不成立
- 要给模型注入大量全新知识:注意,这种情况其实更该先想 RAG,但如果确实要训进参数,低秩容量可能不够
- 追求极致效果、且资源充足:在数据和算力都管够时,全参微调的效果天花板通常还是比 LoRA 高一点
但话说回来,对绝大多数应用开发者来说:
90% 的微调需求,LoRA 或 QLoRA 都能很好地满足。
需要上全参微调的场景,反而是少数。
所以别一上来就觉得 LoRA 是“简化版、低配版”。
它在大多数实战场景里,就是那个性价比最高的正解。
# 八、面试里怎么讲
如果面试官问:
“你们微调用的什么方法?LoRA 吗?讲讲为什么用它,参数怎么设的。”
可以这样答:
“我们用的是 LoRA,资源紧张的时候用 QLoRA。
用 LoRA 的核心原因是省显存。全参微调要更新所有参数,梯度和优化器状态的开销比模型权重本身还大。LoRA 把原始权重冻结,只在旁路训练两个低秩矩阵,可训练参数能降到原来的几百分之一,梯度和优化器开销跟着一起降。
它的前提假设是,微调要学的权重变化量本质上是低秩的——模型已经会了通用能力,下游适配只需要在少数几个方向上做调整,所以一个低秩矩阵就够表达。
参数上,rank 我一般从 8 或 16 起步,根据任务复杂度和验证集效果往上调;如果要调到很大才有效,说明 LoRA 不太适合这个任务,会重新考虑全参微调。alpha 一般设成 rank 的两倍,它是个缩放因子,除以 r 是为了让 rank 变化时训练更稳定。LoRA 我会加在注意力的 q/k/v/o 和 FFN 的投影层上。
如果显存实在不够,就上 QLoRA,把冻结的基座用 NF4 做 4bit 量化,适配器保持高精度,代价是训练慢一点、精度略有损失。
另外 LoRA 在部署上也有优势,一个基座可以挂多个适配器按业务切换,不用为每个业务存一整个大模型。”
这个回答能体现四件事:
第一,你懂它为什么省(梯度和优化器状态)。
第二,你懂它为什么能省(低秩假设)。
第三,你懂参数背后的权衡(rank、alpha、target_modules)。
第四,你懂工程落地(QLoRA、多适配器部署)。
这比背一句“我们用 LoRA 微调了模型”强太多了。
# 九、最后提醒
录友要记住一条主线:
LoRA 解决的从来不是“效果”问题,而是“成本”问题。
它没有让模型变得更聪明。
它做的事情,是用一个“微调本质低秩”的假设,把训练成本和部署成本砍到原来的零头。
正因为便宜,它才把大模型微调从“大厂专属”变成了“人人可玩”。
但便宜不该成为你不懂原理的借口。
会跑 LoRA 脚本的人很多。
能说清 rank 是什么、为什么低秩够用、QLoRA 量化的是哪部分、什么时候 LoRA 不够的人,少得多。
面试时,区分你和别人的,从来不是你用没用过 LoRA,而是你懂不懂它为什么这么设计。
评论
验证登录状态...