# 百度面经
# ThreadLocal 的实现原理?
ThreadLocal是 Java 提供的线程本地变量工具,核心作用是让每个线程都持有一份自己的变量副本,避免多个线程直接竞争同一份共享变量。ThreadLocal本身不直接保存数据,真正的数据保存在当前线程对象的ThreadLocalMap中。结构可以理解为:Thread -> ThreadLocalMap -> Entry(ThreadLocal, value)。- 调用
set()时,会先拿到当前线程,再拿到线程内部的ThreadLocalMap,然后以当前ThreadLocal对象作为 key,把业务值作为 value 放进去。调用get()时,也是先找到当前线程的 map,再通过当前ThreadLocal找到对应 value。 - 在线程池场景中,工作线程会被复用,所以使用完
ThreadLocal后最好在finally中调用remove(),避免内存泄漏和上下文串用。
# ThreadLocalMap 中的 key 和 value 是什么类型的引用?
ThreadLocalMap里的每个元素是一个Entry,它继承了WeakReference<ThreadLocal<?>>,所以 key 是 ThreadLocal 对象的弱引用。- value 是真正存储的线程本地变量,类型是
Object,并且是 Entry 对 value 的强引用。 - 可以简单理解为:key 只是当前
ThreadLocal的弱引用入口,value 才是业务真正放进去的数据。
# 为什么 key 能被 GC 自动回收,但 value 不能被 GC 自动回收?
- key 是弱引用,当外部没有强引用再指向这个
ThreadLocal对象时,下一次 GC 就可以把 key 回收掉,ThreadLocalMap里的 key 会变成null。 - value 不一样,它仍然被
ThreadLocalMap.Entry强引用着。只要线程还存活,Thread -> ThreadLocalMap -> Entry -> value这条引用链还在,value 就仍然是可达对象,GC 不会主动回收。 ThreadLocalMap会在部分get()、set()、remove()操作中顺带清理 key 为null的陈旧 Entry,但这个清理不是实时保证的。所以在线程池这种长生命周期线程里,必须主动调用remove()。
# value 主要是什么?
- value 就是调用
ThreadLocal.set(value)放进去的业务对象,也就是当前线程独享的变量副本。 - 常见 value 有用户上下文、租户 ID、权限信息、
traceId、请求上下文、事务上下文、数据库连接资源、线程私有工具对象等。 - 实际开发中不建议把大对象长期放进
ThreadLocal,尤其在线程池里,如果忘记清理,会让内存压力和排查难度都变大。
# 垃圾回收器有哪些?
- 新生代常见收集器有 Serial、ParNew、Parallel Scavenge。Serial 是单线程收集器,ParNew 是 Serial 的多线程版本,Parallel Scavenge 更关注吞吐量。
- 老年代常见收集器有 Serial Old、Parallel Old、CMS。Serial Old 是单线程标记整理,Parallel Old 关注吞吐量,CMS 追求低停顿,但会有内存碎片和浮动垃圾问题。
- 整堆收集器常见的是 G1,它把堆划分成多个 Region,优先回收价值高的区域,兼顾吞吐和停顿控制。更新一些的低延迟收集器还有 ZGC、Shenandoah,更适合超大堆和低停顿场景。
- 面试里可以按场景总结:后台计算更偏向吞吐量,可以考虑 Parallel;在线服务更关注响应时间,常见选择是 G1;CMS 现在更多作为历史方案理解。
# 可达性分析法的 GC Roots 有哪些?
- 可达性分析会从一组 GC Roots 出发向下搜索,如果一个对象到 GC Roots 没有任何引用链相连,就认为这个对象不可达,可以被回收。
- 常见 GC Roots 包括:
- 虚拟机栈中局部变量表引用的对象
- 本地方法栈中 JNI 引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 被
synchronized锁持有的对象 - 活跃线程、系统类加载器等 JVM 运行时自身持有的对象
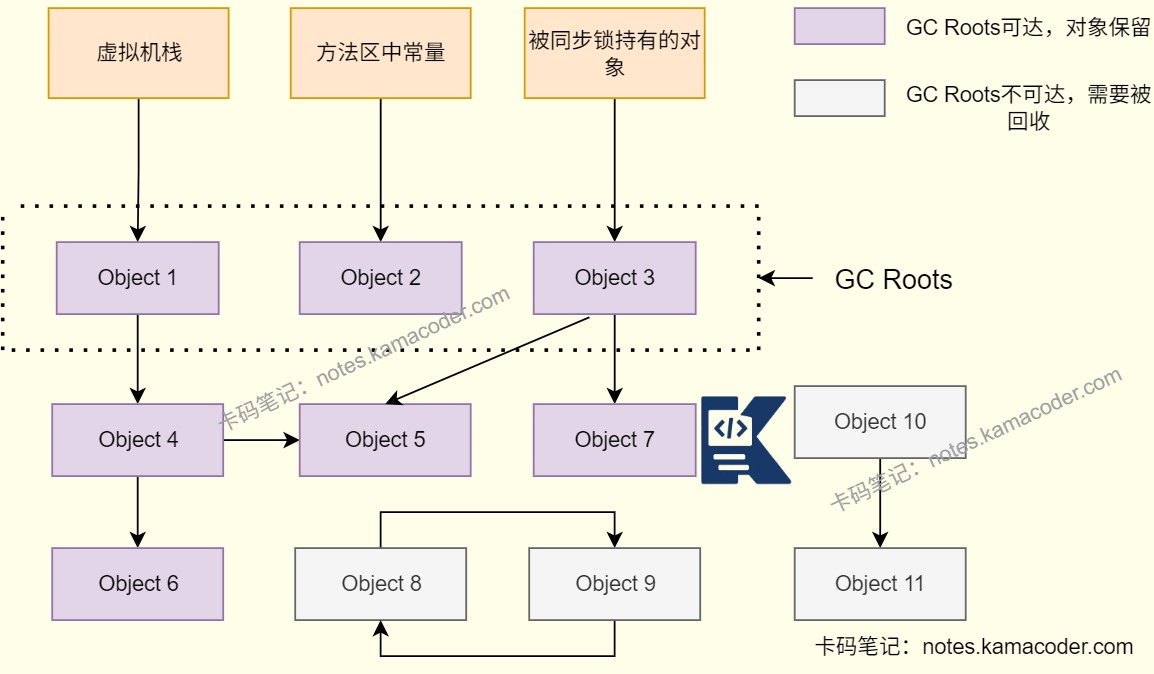
# 为什么选这些对象作为 GC Root?
- 这些对象本质上代表了程序当前还能直接访问到的入口,比如正在执行的方法栈、全局静态变量、JNI 句柄、锁对象和 JVM 运行时结构。
- 只要从这些入口还能访问到某个对象,就说明这个对象后续仍可能被程序使用,不能被垃圾回收器误删。
- GC Root 不是说对象永远不会被回收,而是说它在当前这次可达性分析中作为根节点存在。等方法执行结束、线程结束、静态引用置空或 JNI 引用释放后,它就可能不再是 GC Root。
# 平时使用 MySQL 是怎么用的?
- 项目里一般把 MySQL 作为核心关系型存储,用来保存用户、订单、文件、权限、配置这类需要持久化和事务一致性的数据。
- 开发时会通过 MyBatis、JPA 或 JDBC 访问 MySQL,围绕表结构设计、主键设计、索引设计、SQL 编写、事务控制和连接池配置来使用。
- 日常优化上会关注 SQL 是否走索引、是否有慢查询、是否需要分页优化、是否出现锁等待或死锁。常用
explain看执行计划,结合慢 SQL 日志和监控定位问题。
# MySQL 的存储引擎?
- 存储引擎负责表数据的存储、索引组织、事务、锁和崩溃恢复等底层能力。MySQL 支持多种存储引擎,可以通过
show engines查看。 - 常见的有 InnoDB、MyISAM、Memory、Archive、CSV 等。InnoDB 是现在最常用的默认引擎,支持事务、行锁、MVCC、外键和崩溃恢复。
- MyISAM 不支持事务,主要是表锁,读性能较好但并发写能力和一致性能力弱。Memory 把数据放在内存里,适合临时数据。Archive 更偏向归档存储,适合大量写入、很少更新的历史数据。
# 为什么用 InnoDB 做默认存储引擎?
- InnoDB 支持 ACID 事务,通过
redo log保证持久性,通过undo log支持回滚和 MVCC,更适合业务系统对一致性的要求。 - InnoDB 支持行级锁和 MVCC,读写并发能力比表锁模型更好。普通快照读不会阻塞写,写操作也能尽量缩小锁范围。
- InnoDB 使用 B+ 树索引,主键索引是聚簇索引,查询、范围扫描和排序都比较稳定。再加上崩溃恢复、外键等能力,所以通用业务场景默认选择 InnoDB 更稳。
# 事务隔离级别有哪些?
- MySQL 常见四种隔离级别是:读未提交、读已提交、可重复读、串行化。InnoDB 默认使用的是可重复读。
- 读未提交可以读到其他事务未提交的数据,会出现脏读、不可重复读和幻读。
- 读已提交只能读到其他事务已经提交的数据,解决了脏读,但仍可能出现不可重复读和幻读。
- 可重复读保证同一个事务内多次读取同一数据结果一致,解决脏读和不可重复读。InnoDB 在可重复读下通过 MVCC 和 Next-Key Lock 尽量解决幻读问题。
- 串行化隔离级别最高,会让事务串行执行,可以解决脏读、不可重复读和幻读,但并发性能最差。
# update b = b + 1 where b = 5 在可重复读隔离级别下,5 个线程并发执行,最后 b 的值是多少?
- 如果假设只有一行数据,初始
b = 5,实际 SQL 是update t set b = b + 1 where b = 5,5 个事务并发执行后,最后通常是 6。 - 原因是
update属于当前读,不是普通select那种快照读。第一个事务拿到行锁后把b从 5 改成 6,其他事务会等待这个行锁释放。 - 等第一个事务提交后,后面的事务会读取最新版本并重新判断
where b = 5,这时条件已经不满足了,所以后续事务影响行数是 0,不会继续把 6 改成 7。 - 如果条件不是
where b = 5,而是按主键更新同一行,比如where id = ?,那 5 个事务依次加锁并执行累加,最终就可能从 5 变成 10。关键区别在于更新后是否还满足where条件。
# OSI 网络模型?
- OSI 七层模型从上到下分别是:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
- 应用层直接面向应用程序,常见协议有 HTTP、HTTPS、DNS、FTP。表示层负责数据格式转换、加密解密、压缩解压。会话层负责会话建立、管理和释放。
- 传输层负责端到端通信,典型协议是 TCP 和 UDP。网络层负责 IP 寻址和路由转发,典型协议是 IP、ICMP。数据链路层负责把网络层数据封装成帧,处理 MAC 地址、差错检测和链路访问控制。物理层负责比特流在网线、光纤、无线信号上的传输。
- 实际工程里更常用的是 TCP/IP 四层模型:应用层、传输层、网络层、网络接口层。
# 数据链路层有哪些协议?
- 数据链路层的核心职责是成帧、MAC 地址寻址、差错检测、链路访问控制,保证相邻节点之间可以传输数据帧。
- 常见协议或标准有 以太网 Ethernet / IEEE 802.3、Wi-Fi / IEEE 802.11、PPP、HDLC、Frame Relay、VLAN / IEEE 802.1Q、STP / IEEE 802.1D。
- 面试里也经常会把 ARP 放到链路层相关内容里讨论,因为它负责把 IP 地址解析成 MAC 地址,帮助网络层数据包在局域网内找到下一跳的链路层地址。
评论
验证登录状态...