# 字节跳动一面 Java 面经
以下是知识星球 (opens new window)录友分享字节一面面经,大家感受一下,难度,整体来说还是比较基础的。
# MySQL主从同步的原理是啥?
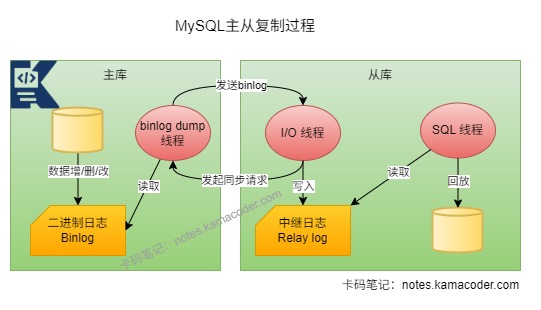
MySQL的主从同步依赖于Binlog实现,可以分为写入、同步、回放三步操作。
主库对数据进行增删改操作后,会按顺序记录MySQL上所有变化并以二进制形式Binlog保存在磁盘上,主库的Binlog Dump线程会推送Binlog内容给从库,从库通过IO线程拉取主库的Binlog并写入中继日志(Relay Log),再由SQL线程重放中继日志中的操作,实现主从数据一致;
SQL线程采用的是异步复制的模式,主库无需等待从库确认即可执行后续操作。
# binlog里都存了些啥?
Binlog是MySQL服务层的二进制日志,全局生效、所有引擎共用。
记录MySQL中操作的执行顺序、事务提交标记和所有数据变更类的操作事件,包括DDL语句(CREATE/ALTER/DROP)和DML语句(INSERT/UPDATE/DELETE),但是不存储只读查询操作。
# Binlog和数据库是啥关系?
Biglog是MySQL数据库的数据变更专属日志,数据库对数据进行操作后会由binlog记录,不存储实际数据。数据库的数据可以通过Binlog回溯恢复。
# MySQL是怎么保证ACID的?
MySQL依靠Undo日志,也就是回滚日志实现原子性(Atomicity)。在事务执行的每一步会记录反向日志,事务失败或回滚时可以通过Undo日志撤销已执行的修改,回滚到事务开始前的状态;
MySQL依靠Redo日志(重做日志)和内存刷盘机制实现持久性(Durability),当事务提交时,数据变化会先顺序写入Redo日志中,日志落盘则判定提交成功。如果此时数据库宕机,重启后也会通过Redo日志重做所有已提交的事务,实现数据的永久保存。
MySQL依靠锁机制和MVCC双重保证隔离性(Isolation),锁机制可以解决写写冲突、MVCC通过版本链解决读写冲突;同时提供读未提交、读已提交、可重复读和串行化四种隔离级别,默认是可重复读,能够避免脏读、不可重复读、降低幻读的出现。
事务的一致性(Consistency)是通过原子性、隔离性与持久性共同保障的,确认事务执行前后数据库的数据符合业务规则。
# 监控MySQL性能,一般看哪些指标?
- 我一般使用show global status查看数据库的实时状态或者查看数据库的慢查询日志监控MYSQL的性能。
- 了解执行指标时我会关注QPS(每秒查询数),表示数据库每秒处理的查询数量,如果QPS高可能意味着数据库的负载较大,可能存在性能瓶颈。代码中需要减少不必要的查询,可以使用索引提高查询效率;还可以关注TPS(每秒事务数),如果数值变化大可能是事务中存在锁等待时间或慢查询。
- 如果想关注连接与线程状态,可以看当前活跃的连接数(Threads_connected),该数值持续接近最大连接数时可能出现连接泄漏问题;还有正在执行查询的线程数,如果超过了CPU核心数2倍可能存在并发问题;
- 还有磁盘IO与日志的指标,比如redo log的刷盘频率和binlog的写入速度,磁盘的吞吐量等。如果磁盘IO有瓶颈,会导致日志刷盘阻塞而阻塞事务提交。
# 怎么保证MySQL和Redis的数据一致性?
- 首先需要根据业务场景选择适合的一致性方案,对于大多数场景来说,只需保证最终一致性,允许在缓存删除失败或并发读的情况下导致的短暂不一致发生。读操作先查缓存,命中则返回,未命中则查DB后写入缓存并返回;写操作则先更新DB再删除缓存。
- 在交易等核心场景下,需要保证强一致性时,可以使用分布式锁+双写同步实现,在写操作时先获取分布式锁,更新DB和缓存的数据之后再释放锁,可以避免并发读写导致的不一致,同一时间只有一个请求操作数据。
- 在高并发场景下,使用DB更新和MQ异步更新缓存保证最终一致性,写操作更新DB后发送MQ消息,消费端异步删除/更新缓存,同时添加定时任务对比数据库与缓存数据,作为兜底机制。
# 聊聊你对进程、线程、协程的理解?
进程是操作系统进行资源分配的基本单位,线程是轻量级的进程,是进行任务调度和执行的基本单位,而协程是用户态的轻量级线程,由编程语言运行时调度,必须依附于线程存在。
进程内可以有多个线程,进程的结束会终止所有线程,线程崩溃可能导致进程崩溃,但是进程崩溃不会影响其他进程。没有线程的进程可以看做单线程。一个线程可以创建上万甚至几十万个协程。
在开销方面,进程有独立的代码和数据空间,切换会有较大开销;同一类线程共享代码和数据空间,有独立的运行栈和程序计数器,切换开销小;协程的切换开销更小,因为它是用户态的线程,切换时不需要切换到内核态。
# 你熟悉哪些设计模式?具体用在项目哪里了?
我了解设计模式有创建型、结构性和行为型三类。
创建型设计模式有单例模式,用于保证类仅有一个实例并提供全局访问入口,工厂模式用于封装对象创建逻辑,将对象的创建与使用解耦;
结构性设计模式有适配器模式,可以兼容不匹配的接口,装饰器模式可以动态增强对象的功能,类似的还有代理模式可以控制对象访问并附加增强逻辑;
行为型设计模式有用于封装不同算法并实现快速切换的策略模式,还有观察者模式,可以实现对象之间一对多的依赖通知。
我在项目中也使用过几种常见的设计模式,实现了解耦、复用、扩展等功能。
项目的全局配置管理和Redis连接池、线程池等我会使用单例模式实现,保证类的实例全局唯一;
在通知的场景中我利用观察者模式实现状态变更时自动通知订阅者,解耦业务触发方和处理方,订阅者增加时也不用更改业务代码;
我还利用装饰者模式实现了对接口的同一增强处理,项目中的日志模块、参数校验和异常处理等都使用了装饰者模式进行增强,在不修改原有逻辑的基础上动态地为接口添加功能,扩展性很好。
# 算法题:寻找第 K 大
给定一个整数数组 nums 和一个整数 k,请你返回数组中第 k 大的元素。
这里的“第 k 大”指的是按从大到小排序后的第 k 个元素
不是第 k 个不同的元素
需要在不一定完全排序整个数组的前提下,找到答案
输入:nums = [3,2,1,5,6,4], k = 2
输出:5
解释:从大到小排序后为 [6,5,4,3,2,1],第 2 大的元素是 5。
回答:
这道题是找数组中第 k 大的元素,注意不是第 k 个不同的元素,数组中可能有重复值。
最直接的做法是先排序,从大到小排序后取第 k 个,时间复杂度是 O(n log n)。
但其实这题不需要完全排序,可以用快速选择(Quick Select)优化到 O(n)。
它的核心思想是基于快排的 partition,每次选一个 pivot,把数组分成三部分:大于、等于、小于。
然后判断第 k 大落在哪一部分,只递归那一边。
举个例子,比如 pivot (分割线) 是 4,可以分成 [5,6],[4],[3,2,1],如果 k 在左边,就只递归左边。
这样平均时间复杂度是 O(n),最坏情况是 O(n²),一般通过随机选择 pivot 来避免。
面试官追问了一下:为什么是 O(n)?
因为每一轮 partition 都会淘汰掉一部分数据,不需要像快排一样递归两边,所以整体是线性的。
又问了 可以用堆吗?
可以,用一个大小为 k 的最小堆,时间复杂度是 O(n log k),适合数据流场景。
评论
验证登录状态...