# 小红书后端一面面经
# 一张表假设有多个字段 a、b、c,建立了 abc 联合索引,where a = ? and b = ? order by c 能命中索引吗?
- 可以命中,当
where a = ? and b = ?对前两列都是等值匹配时,剩下的记录天然就已经按c有序,使用order by c可以继续利用索引,避免额外filesort。
# 索引的底层原理是什么?
- 以MySQL为例,InnoDB 最常用的索引结构是 B+ 树,它是一种多路平衡查找树,节点能存很多数据,树高低,IO极少,因此适合磁盘存储场景。
- B+ 树的非叶子节点只存索引,不存整行数据,所有数据都存在叶子节点上;叶子节点之间还用双向链表相连,做范围查询和排序也更方便。
# 单例模式怎么实现
- 单例模式保证一个类在程序运行期间只有一个实例,提供全局唯一访问入口,解决频繁创建和销毁全局使用的类实例问题,当需要控制实例数目节省资源时使用。常见的实现方式有懒汉式、饿汉式、双重检查锁(DCL)、静态内部类和枚举单例。
- 饿汉式是在类加载时就创建实例,是线程安全的,但是可能导致资源浪费。懒汉式则是在第一次使用时才创建实例,线程不安全,但可以延迟加载,避免了资源浪费。如果想实现线程安全的单例模式,可以使用synchronized 关键字修饰 getInstance() 方法,不过添加synchronized后会影响效率。
- 使用双重校验锁(DCL-Double Check Locking)也可以实现单例模式,能够在多线程环境下保证线程安全并具有高性能。通过synchronized保证多线程下的原子性,volatile解决指令重排问题,外加两次空检查实现。
- 静态内部类也可以实现单例,将构造函数私有,内部类仅在调用getInstance()时加载,并且类加载的阶段初始化,线程安全。
- 枚举方式实现单例由JVM保证唯一,且枚举类的构造器默认是私有,能够防止反射创建实例,支持序列化机制,防止反序列化重新创建新对象。
# 为什么要双重检测?
- 双重检测主要是为了兼顾线程安全和性能。第一重
if (instance == null)是为了避免每次获取实例都直接进入同步块,否则即使对象已经创建好了,后续所有线程也还要抢锁,开销比较大。第二重if (instance == null)是为了防止多个线程同时通过第一层判断后,排队进入同步块时重复创建对象。 - 另外双重检查锁必须配合
volatile,因为对象创建不是绝对原子操作,底层可能发生指令重排,导致别的线程拿到一个“还没完全初始化”的对象。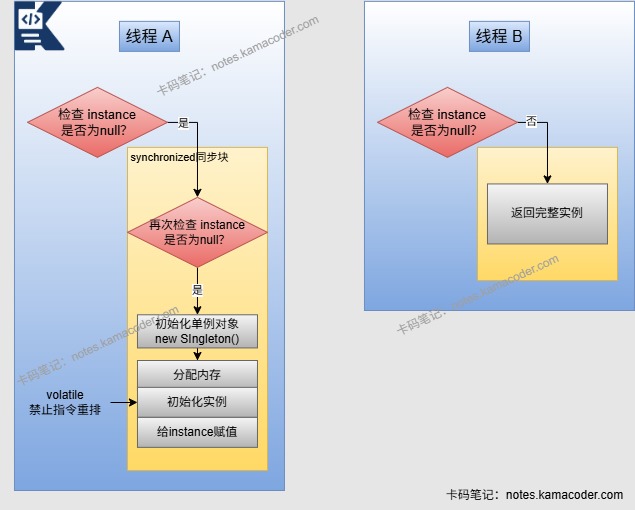
# 如果使用反射机制可以破坏单例吗?
- 如果单例只是普通私有构造器,反射依然能通过
setAccessible(true)强行调用构造器,创建出多个实例。如果不想被反射机制破坏,可以在构造器里加判断,如果实例已存在就直接抛异常。或者直接使用枚举单例。
# MySQL 事务隔离级别介绍,你平时用的哪一个
- MySQL 常见四种隔离级别是:读未提交、读已提交、可重复读、串行化。InnoDB 默认使用的是可重复读。
- 读未提交是读取其他事务未提交的修改,存在脏读、幻读、不可重复读的问题,适合对数据一致性要求极低的场景。读已提交是只能读取其他事务已提交的修改,能够解决脏读问题,但是仍有不可重复读和幻读问题。可重复读是同一事务内多次读取同一数据时结果保持一致,能够解决脏读和不可重复读问题。它是MySQL InnoDB引擎的默认隔离级别,InnoDB使用MVCC和Next-Key Locks间隙锁机制可以解决幻读。串行化会给记录加读写锁,能够完全解决脏读、不可重复读和幻读问题 ,但是并发性能差,适用于对数据一致性要求高的场景。
- 我平时更常用的是可重复读,因为这是 InnoDB 默认级别,工程里也比较常见,性能和一致性相对平衡。
# Redis 你在什么场景使用?
- 我项目里对 Redis 的使用主要还是集中在缓存场景,比如热点数据缓存、详情页缓存、配置缓存这类读多写少的数据。如果有高并发场景,也会用 Redis 做计数器、限流、分布式锁、秒杀库存预扣减。
- Redis 还可以做排行榜、延时队列、签到位图、布隆过滤器这些,但核心还是要根据业务特征去选。
# 旁路缓存会存在脏数据吗
- 会。经典旁路缓存模式是“先更新数据库,再删除缓存”,它能降低不一致概率,但不能绝对消灭脏数据。比如线程 A 更新数据库后还没删缓存,线程 B 正好读到旧缓存;或者删缓存后并发读请求又把旧数据回填进缓存,这些都可能造成短时间不一致。所以旁路缓存是实现最终一致,不是强一致。
- 常见优化方式可以选择删除缓存、延迟双删。对高一致性场景引入 MQ / binlog 异步修正,还可以缩短热点缓存 TTL,降低脏数据持续时间。
# Redis 获取缓存耗时增加了,原因可能是什么?
- 可以从网络层、Redis 实例层、数据层、客户端层这四个方向考虑。
- 网络层面可能是出现了跨机房调用、网络抖动、连接池不足、连接频繁创建销毁。Redis 实例层面可能是CPU 打满、命令慢查询、阻塞命令、AOF 重写 / RDB 快照、主从同步压力、内存淘汰、集群迁槽。在数据层面可能是:热点 key、大 key、key 过期引发回源风暴,导致看起来像是“Redis 变慢了”,其实是整体链路被拖住了。客户端层面还要看序列化、反序列化、线程池、GC、超时重试这些问题。
- 所以我一般会结合
slowlog、info、监控面板、链路追踪、网络耗时一起看,不只盯 Redis 命令本身。
# OOM 问题怎么处理
- 如果线上发现 OOM,我先确认是哪个服务或实例,必要时摘流、重启、扩容,避免流量继续堆积。
- 然后看监控,确认是瞬时流量打满、内存配置不足,还是代码层面内存泄漏。
- 如果是 Java 服务,我会先保留比如 heap dump、GC 日志、容器内存限制、监控截图等,再去做根因分析,判断是缓存堆积、大对象、线程池任务堆积、无限重试、集合没释放,还是参数配置不合理。
# OOM 问题处理,原因可能是什么,怎么处理?
- Java OOM 常见类型有堆内存溢出、元空间溢出、堆外内存溢出和线程数过多几类。大对象、集合无界增长和内存泄漏会造成堆OOM,动态代理和反射多以及类加载器泄漏会造成元空间OOM;直接内存使用过多会造成堆外OOM,不限制线程创建或者线程池不合理,阻塞堆积时会造成线程OOM。
- 堆OOM比较常见,需要定位泄漏点清理无用的引用,给集合/缓存添加大小限制或过期策略,合理的调整-Xmx。元空间OOM需要检查动态代理和重复类加载,调大-XX:MaxMetaspaceSize。排查堆外OOM需要检查NIO/Netty释放逻辑,合理设置-XX:MaxDirectMemorySize。线程OOM问题需要统一使用线程池,合理设置核心线程和最大线程数,排查IO阻塞和死锁的情况。
# 优惠券秒杀(方案描述)中,最核心的问题是什么?
- 我觉得秒杀场景最核心的不是“怎么把请求接进来”,而是高并发下库存正确性和系统稳定性。
- 库存不能超卖,这是最基本的一层;再往上还要考虑一人一单、幂等、防刷、削峰、异步化。
- 所以一个可落地的秒杀方案,要在前面做限流和校验,Redis 做库存预扣减或资格判断,还需要使用MQ 异步下单削峰,最后做数据库最终落单和状态校验。
# 你是怎么避免超卖的
- 我会做多层保护,在数据库层面,可以用:
update coupon set stock = stock - 1 where id = ? and stock > 0这种方式保证扣减库存时不会扣成负数。 - 在Redis 层面可以先做库存预扣减,快速拦住明显抢不到的请求,减轻数据库压力。另外还可以添加,一人一单校验,幂等控制,异步下单和最终一致性校正等进行配合。
# 线程池有哪些核心参数
- 线程池的构造函数有七个参数,分别是核心线程数(corePoolSize)、最大线程数(maximumPoolSize)、空闲线程存活时间(keepAliveTime)、时间单位(TimeUnit)、线程池任务队列(workQueue)、线程工厂(ThreadFactory)和拒绝策略(RejectedExecutionHandler)。
- 核心线程数是线程池中长期存活的线程数,如果线程池中的线程数量小于核心线程数,这些线程处于空闲状态也不会被销毁;最大线程数是线程池最多能创建的线程数当核心线程已满,任务队列已满时,如果当前线程小于最大线程数,就会创建新的线程执行此任务,否则触发拒绝策略。在线程数大于核心线程数时,如果每个线程的空闲时间超过了设置的空闲线程存活时间,这个线程就会被销毁,销毁线程数=当前线程数-核心线程数。空闲线程的存活时间单位是TimeUnit。线程池的任务队列在没有空闲线程执行新任务时,存储所有待执行任务。线程池通过创建线程的工厂设置线程的优先级、线程命名规则以及线程类型(用户线程/守护线程)。线程池的拒绝策略则是当线程池的任务超出线程池队列可以存储的最大值之后,执行的策略。
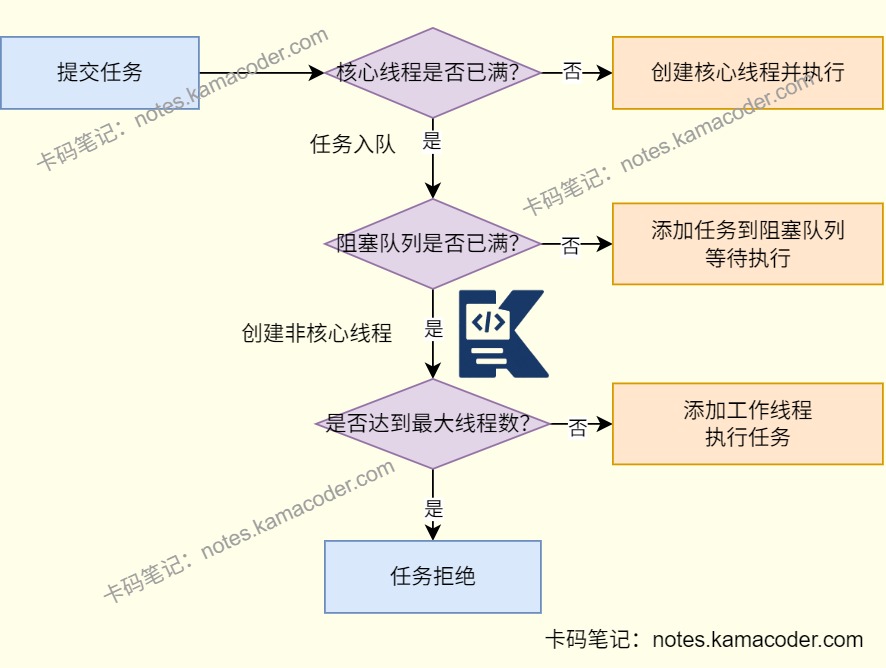
# 为什么线程池要先使用核心线程,然后队列排队,队列满才创建非核心线程,为什么要这么设计
- 这个设计是在资源稳定性、任务缓冲和吞吐能力之间做平衡。先创建核心线程,是因为线程本身创建和销毁都有成本,核心线程可以长期复用,适合作为稳定处理能力。核心线程满了先放队列,是因为队列相当于一个缓冲区,可以吸收短时间突发流量,避免任务一上来就疯狂创建线程,把 CPU 和内存打满。只有队列也满了,才继续创建非核心线程,说明这已经不是瞬时波峰,而是持续压力,线程池才会临时扩容去兜住吞吐。
- 如果一上来就创建线程,不仅上下文切换开销大,还容易让机器失稳;如果只排队不扩容,任务又可能堆太久,所以当前这套策略是一个比较合理的折中。
评论
验证登录状态...