# 小红书研发一面面经
# Java 为啥有虚拟机的这个设计?
- 虚拟机是实现“一次编写,到处运行”的核心。Java 源码先经过编译变成字节码,再由不同平台上的 JVM 去执行,这样应用就不用针对每个操作系统重新改写。还能够屏蔽底层差异。像内存管理、线程调度、类加载、垃圾回收这些复杂细节由 JVM 统一处理,业务开发不需要直接面对不同平台的系统调用差异。
- 虚拟机可以提升程序运行时能力。通过类加载机制、反射、JIT、GC、字节码增强等让 Java 在工程场景里更灵活。使用抽象层和运行时开销,换来跨平台、稳定性和生态能力。
# 介绍垃圾回收算法?
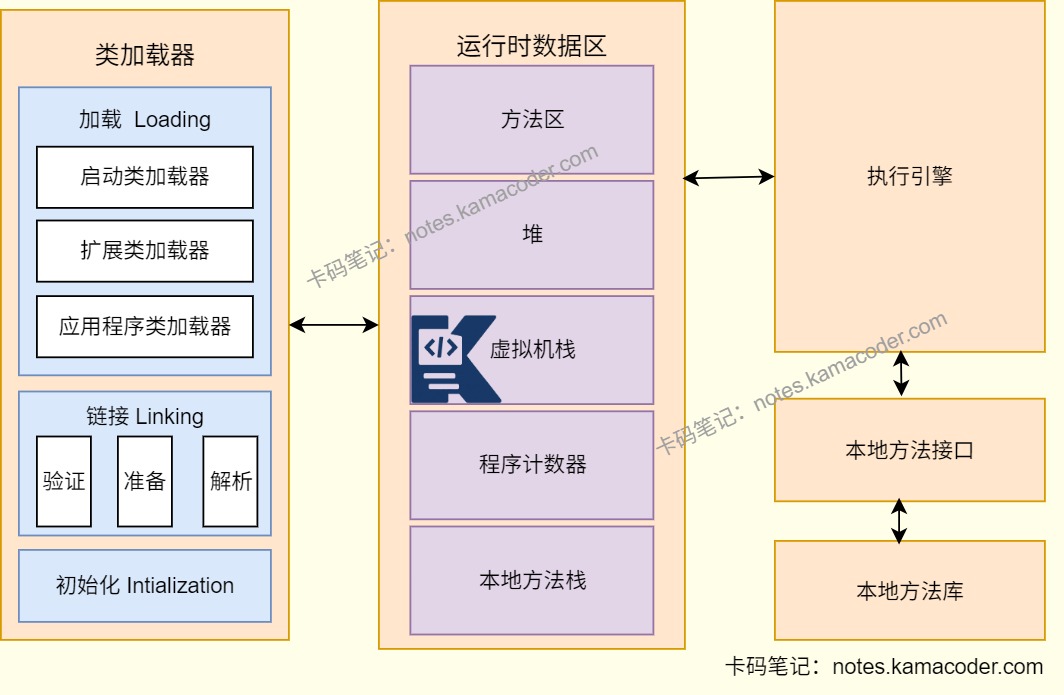
- 常见 GC 算法主要有:标记-清除、复制、标记-整理。
- 标记-清除会先标记存活对象,再清理垃圾对象,优点是实现简单,缺点是会产生内存碎片。
- 复制算法会把内存分成两块,每次只用一块,回收时把存活对象复制到另一块,优点是效率高,缺点是空间利用率低,所以更适合新生代。
- 标记-整理是在标记后把存活对象往一端压缩,再清理边界外的空间,优点是没有碎片,更适合老年代。
- 实际 JVM 里通常是分代收集,也就是新生代和老年代根据对象存活特点组合使用不同算法。
# 什么情况可能出现内存泄露
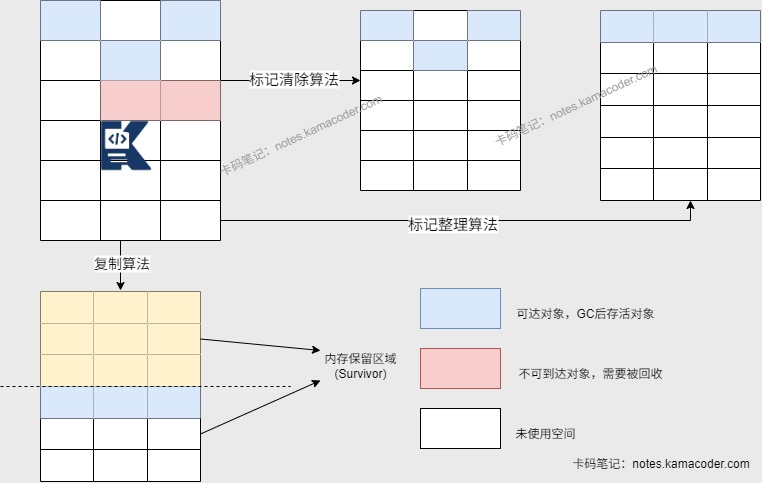
- Java的垃圾回收机制是只要对象“可达”就不会回收,所以有些对象在业务上已经没用了,但代码层面还保留着引用链时,会出现内存泄露。
- 出现内存泄漏的常见场景有:
- 静态集合、全局 Map 不断缓存对象但不清理
- 监听器、回调、连接对象注册后没释放
- 线程池里的
ThreadLocal用完没remove - 单例对象长期持有大对象引用
- 类加载器泄漏,导致相关类和对象都无法释放
# 怎么排查内存泄露?
- 如果出现堆内存持续上涨、Full GC 后还是降不下来、实例运行时间越长越容易 OOM,我就会检查是否出现了内存泄漏,结合监控和 GC 日志,确认是短时流量造成的内存顶高,还是长期无法回收。
- 如果怀疑泄露,我会导出堆转储:
jmap -dump:live,format=b,file=heap.hprof <pid> - 再用 MAT、VisualVM、YourKit 这类工具看哪类对象数量最多,哪些对象占用内存最大以及GC Root 引用链是谁在持有。然后结合代码定位,看是缓存没过期、集合没清、线程局部变量没释放,还是类加载器问题。
# Spring 的 AOP 怎么实现?
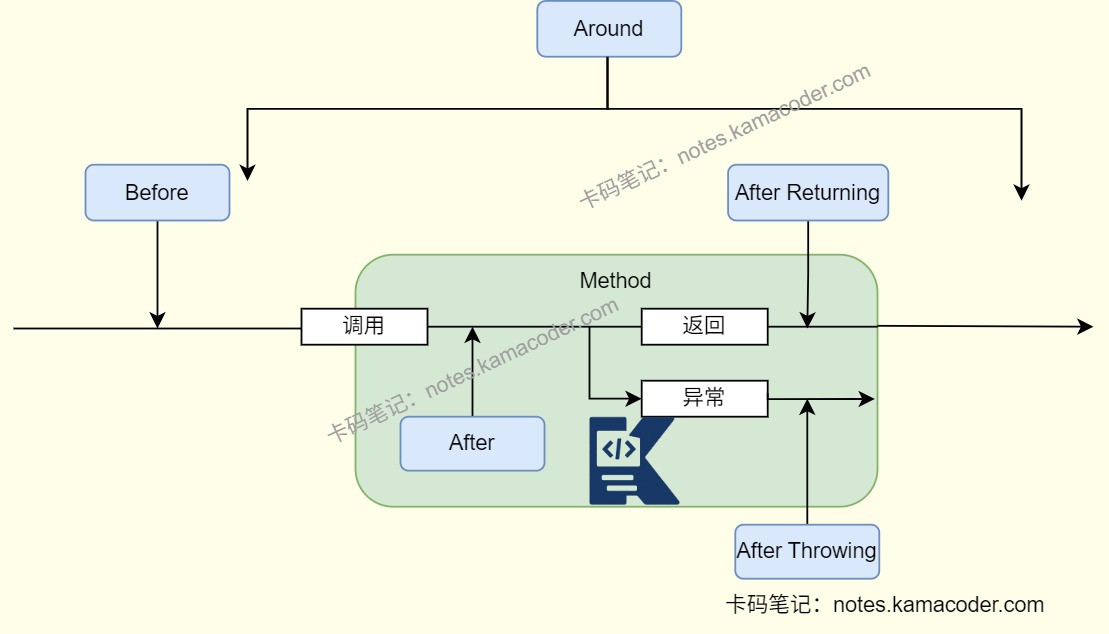
- Spring AOP 核心是动态代理,不直接改业务代码,适合方法级增强,在目标方法前后织入增强逻辑,比如日志、事务、权限、埋点。
- 项目中通用的逻辑都可以使用AOP实现,引入依赖开启AOP支持后,先规划切面范围,选择合适的位置定义切入点pointcut,如拦截Controller层,Service层或者拦截自定义注解的方法;然后编写切面类,使用@Aspect和@Component注解交给Spring管理,定义切入点后写前置/后置/环绕和异常通知就可以生效了。
- 在AOP执行时,Spring启动扫描切面和切入点表达式,然后匹配到目标Bean,如果目标类实现了接口,默认优先使用 JDK 动态代理;如果没有接口,通常使用 CGLIB 通过生成子类的方式做代理;调用方法时会先走代理增强逻辑再执行原目标方法。
# AOP 的使用上有什么区别,什么时候使用代理,什么时候使用子类?
- 目标类有接口时,Spring 默认更倾向于 JDK 动态代理,因为它是基于接口生成代理类,实现轻量,也更符合面向接口编程。目标类没有接口时,就只能走 CGLIB,用生成子类的方式来拦截方法调用。
- DK 动态代理是“代理接口”,CGLIB 是“继承目标类”;因此 CGLIB 无法代理
final class,也无法覆盖final method。
# 假设它是一个 final 类,也没有接口,能切面吗?
- 如果它是
final class,而且没有接口,那 Spring 基于代理的 AOP 就比较难做,因为 CGLIB 需要继承目标类,而final类不能被继承。适合考虑 AspectJ 编译期织入 或 加载期织入,不依赖运行时子类代理。 - 即使类不是 final,只要方法是
final,CGLIB 也不能通过重写方法来增强它。
# 还有哪些方式支持切面 AOP?
- 除了 Spring 常见的 JDK 动态代理和 CGLIB,还可以用 AspectJ。
- AspectJ 支持编译期织入、类加载期织入以及更完整的切点能力。它的增强范围比 Spring AOP 更大,不只局限于 Spring Bean 的方法调用,还能处理构造器、字段访问等更底层的切点。代价是使用和调试复杂度会更高,所以大多数业务场景还是 Spring AOP 足够。
# 循环引用是什么?循环引用的情况下,Spring 能支持正常初始化吗?
- 循环依赖就是:Bean A 依赖 Bean B,Bean B 又反过来依赖 Bean A,形成依赖环。
- Spring 可以解决对单例 Bean 的 setter / 字段注入循环依赖,但对构造器循环依赖,Spring 默认解决不了,因为对象都还没创建出来,没法提前暴露引用。
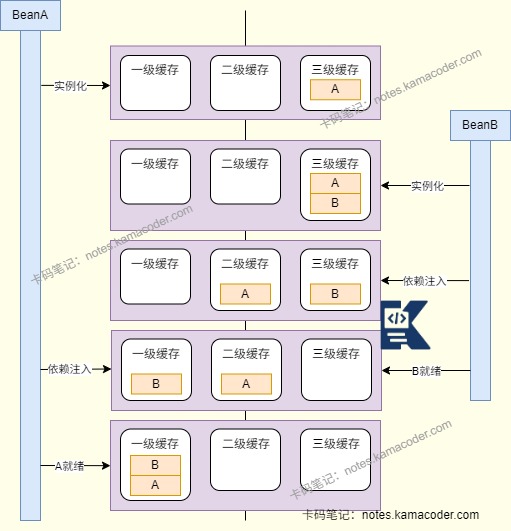
# 你说的这种循环引用是怎么解决的?
- Spring 解决单例循环依赖的核心思路是提前暴露一个还没完全初始化好的对象引用。
- 底层常说的就是三级缓存:一级缓存
singletonObjects是成品 Bean;二级缓存earlySingletonObjects是提前曝光的半成品 Bean;三级缓存singletonFactories是对象工厂,必要时可以提前生成代理对象。创建 Bean A 时,如果发现它依赖 B,就先去创建 B;如果 B 又依赖 A,这时候 Spring 会从三级缓存里拿到 A 的早期引用,先把依赖注入进去。
# FactoryBean 有什么作用?
FactoryBean不是普通 Bean,它更像是一个“生产 Bean 的工厂”。Spring 容器在获取这个 Bean 时,默认拿到的不是FactoryBean本身,而是它的getObject()返回的那个对象。如果想拿到FactoryBean本身,而不是它生产出来的对象,需要在 beanName 前面加&。- 适合处理一些创建逻辑比较复杂、需要自定义构造流程的对象,比如代理对象、第三方组件对象。
# 操作系统的内核态什么概念?
- 操作系统通常会把 CPU 的执行权限分成用户态和内核态。内核态拥有更高权限,可以执行特权指令、访问硬件、管理内存、调度进程、处理中断。用户态运行普通应用程序,权限受限,不能直接操作硬件或敏感系统资源。
- 本质上是为了安全和稳定,避免普通程序随意把整个系统搞崩。
# 你说的特权可以访问到硬件,和内核态有什么关系?
- 特权指令只能在内核态执行。比如页表切换、设备控制、中断处理、I/O 操作这类底层能力,都需要更高权限,用户态程序不能直接做。
- 所以当用户进程需要访问磁盘、网卡、文件系统时,不能自己直接碰硬件,而是要通过系统调用进入内核态,让操作系统代为执行。
# 操作系统内存是怎么分配的?
- 操作系统会为每个进程分配一套独立的虚拟地址空间,实现进程间内存隔离,同时解决外部碎片、支持磁盘换页,让每个进程都感觉拥有连续完整的地址空间。虚拟内存和物理内存都按页来划分,通过页表完成虚拟地址到物理地址的转换。
- 在进程申请内存时采用延迟分配(懒分配)策略:进程申请内存时,先分配虚拟地址空间,并不立即分配物理内存;只有当进程真正访问内存、触发缺页中断时,操作系统才会分配物理页帧,并更新页表完成映射。
# 用户进程访问系统资源,会经过什么过程?
- 用户进程如果要访问文件、网络、磁盘这类系统资源,通常会先发起系统调用。从用户态切换到内核态,常见实现方式是软中断、陷入指令这类机制。
- 进入内核后,操作系统会进行参数校验、权限检查,然后调用内核里的对应服务逻辑去操作资源。处理完成后,再把结果返回给用户进程,并从内核态切回用户态。
# B+ 树的好处有哪些?
- B+ 树更适合数据库索引,核心原因是它更适配磁盘 IO 场景。
- 非叶子节点只存索引项,不存整行数据,所以单个节点能容纳更多 key,树高更低,查找时磁盘访问次数更少。叶子节点之间是链表结构,范围查询、排序、分页扫描都更高效。
- 查询路径也比较稳定,因为所有数据都在叶子节点,性能更容易预测。
# MySQL 的事务隔离级别有哪些?
- MySQL 常见四种隔离级别是:读未提交、读已提交、可重复读、串行化。InnoDB 默认使用的是可重复读。
- 读未提交是读取其他事务未提交的修改,存在脏读、幻读、不可重复读的问题,适合对数据一致性要求极低的场景。读已提交是只能读取其他事务已提交的修改,能够解决脏读问题,但是仍有不可重复读和幻读问题。可重复读是同一事务内多次读取同一数据时结果保持一致,能够解决脏读和不可重复读问题。它是MySQL InnoDB引擎的默认隔离级别,InnoDB使用MVCC和Next-Key Locks间隙锁机制可以解决幻读。串行化会给记录加读写锁,能够完全解决脏读、不可重复读和幻读问题 ,但是并发性能差,适用于对数据一致性要求高的场景。
# 可重复读是怎么实现的?
- 可重复读的核心实现针对快照读主要依赖 MVCC + Read View。同一个事务里,第一次快照读生成一致性视图,后续快照读通常复用这个视图,所以多次查询结果保持一致。
- 针对当前读,比如
select ... for update、update这种场景,还会配合记录锁、间隙锁、Next-Key Lock 去控制并发,尽量避免幻读问题。
评论
验证登录状态...