# 手撕FFN:Transformer前馈网络代码实现
上一篇文章我们把 Multi-Head Attention 从零手撕了一遍,走完了拆分 → 并行 → 拼接 → 投影的完整五步流程。
这篇文章我们来手撕 Transformer Block 里的另一个核心组件:FFN(Feed-Forward Network,前馈神经网络)。
还记得前面文章讲过的结论吗?
Self-Attention 让不同 Token 之间"互通信息",FFN 负责让每个 Token "独立思考",做非线性的深度加工。
这一篇我们就把 FFN 这个"思考模块"真正用代码实现出来,每一步都打印 shape,看数据是怎么变形的。
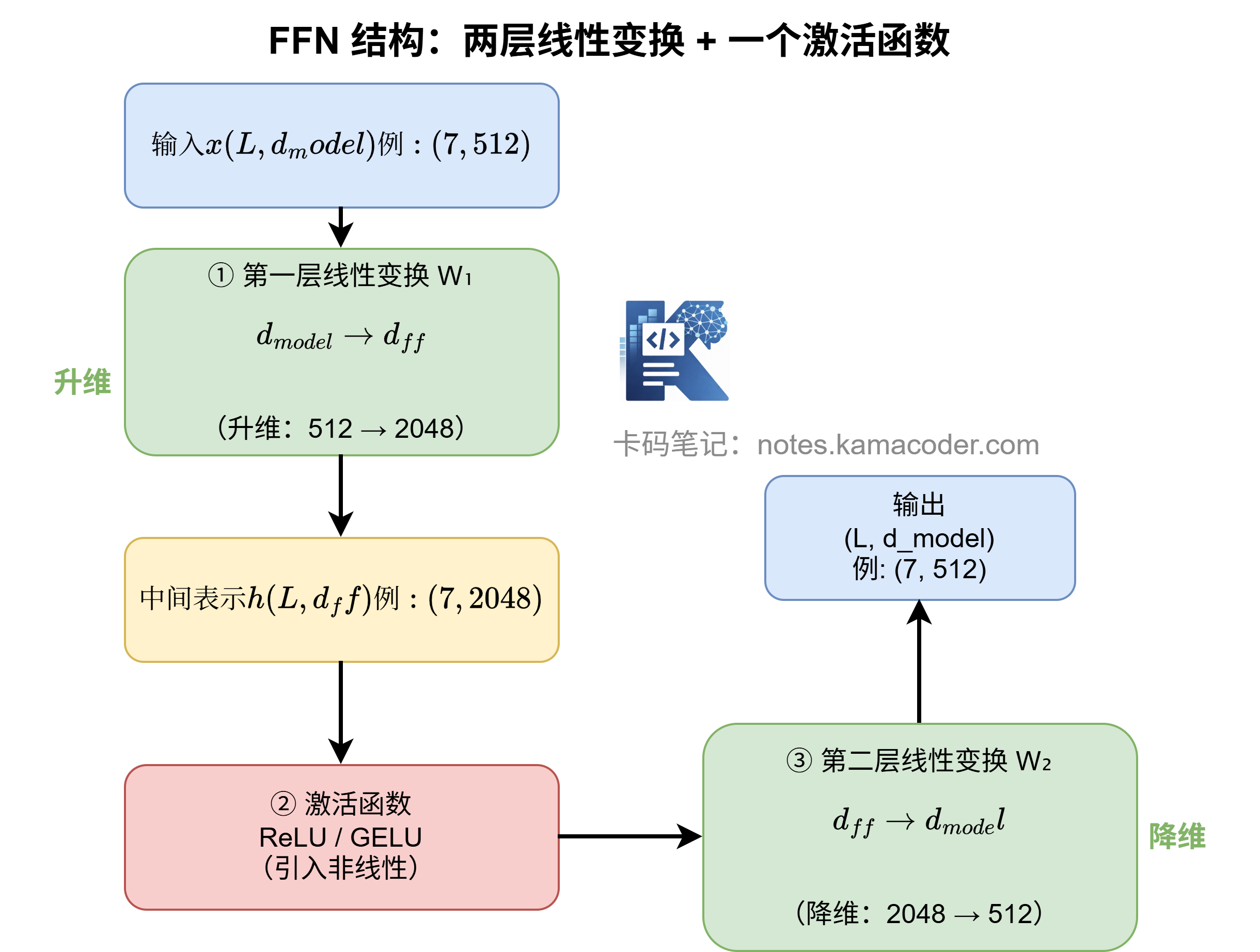
# FFN 的结构有多简单?
很简单:两层线性变换,中间夹一个激活函数。
公式写出来长这样:
拆成三步就是:
输入 x(d_model 维)
↓ 第一层线性变换 W₁(d_model → d_ff,升维)
↓ 激活函数(ReLU / GELU)
↓ 第二层线性变换 W₂(d_ff → d_model,降维)
输出(d_model 维)
2
3
4
5
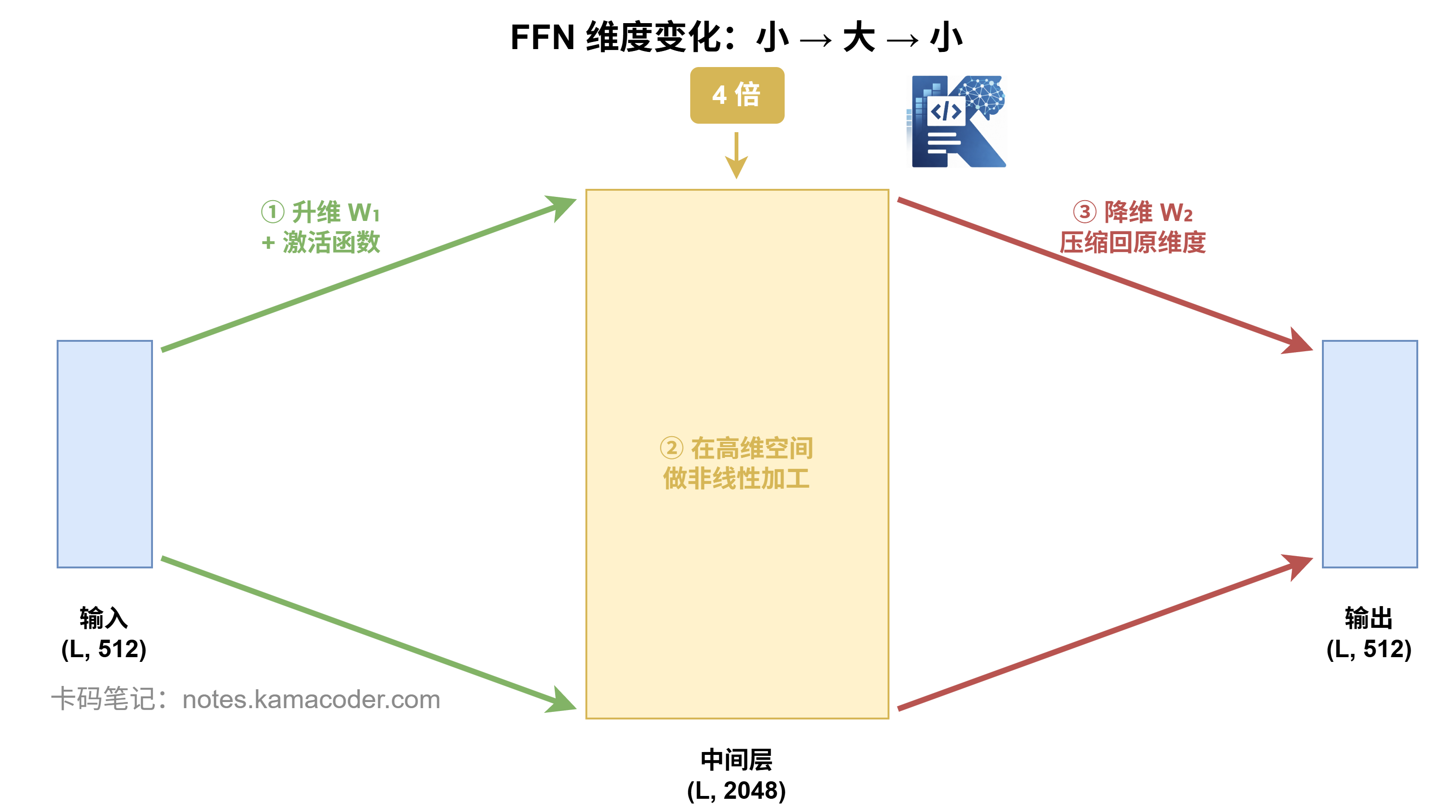
注意关键细节:中间会先升维,再降回原来的维度。
以原始 Transformer 论文为例,d_model = 512,中间层 d_ff = 2048,正好是 4 倍。我们等下会专门讲为什么要这样设计。
# 第一步:准备输入
FFN 是接在 Attention 之后的,所以它的输入就是 Attention 子层的输出。
为了方便演示,我们还是用"远方有颗苹果树"这句话,序列长度 L = 7,d_model = 8(实际中是 512,这里缩小便于观察)。
import numpy as np
# 超参数
L = 7 # 序列长度
d_model = 8 # embedding 维度
d_ff = 32 # FFN 中间层维度(通常是 d_model 的 4 倍)
np.random.seed(42)
# 模拟 Attention 子层的输出,作为 FFN 的输入
x = np.random.randn(L, d_model)
print(f"FFN 输入: {x.shape}") # (7, 8)
2
3
4
5
6
7
8
9
10
11
12
输出:
FFN 输入: (7, 8)
就是一个普通的 (L, d_model) 矩阵,7 个 Token,每个 8 维。
# 第二步:第一层线性变换(升维)
把输入从 d_model=8 升到 d_ff=32,需要一个 (8, 32) 的权重矩阵。
# 第一层权重和偏置
W1 = np.random.randn(d_model, d_ff) # (8, 32)
b1 = np.random.randn(d_ff) # (32,)
# 线性变换:x @ W1 + b1
hidden = x @ W1 + b1
print(f"[升维后] hidden: {hidden.shape}") # (7, 32)
2
3
4
5
6
7
输出:
[升维后] hidden: (7, 32)
每个 Token 从 8 维膨胀成了 32 维。这一步还只是线性变换,没有引入任何"新东西"——真正的魔法在下一步。
# 第三步:激活函数(引入非线性)
这是 FFN 最关键的一步。为什么必须加激活函数?
如果没有它,两层线性变换叠在一起,本质上还是一个线性变换:
两层线性层 = 一层线性层,白干了。所以必须在中间插一个非线性函数,让模型能学到复杂的特征组合。
常用的有两种:
- ReLU:原始 Transformer 用的,简单高效
- GELU:BERT、GPT 用的,表现更平滑
我们先用 ReLU 演示:
def relu(x):
return np.maximum(0, x)
# 应用激活函数
hidden_activated = relu(hidden)
print(f"[激活后] hidden: {hidden_activated.shape}") # (7, 32)
print(f"激活前负数个数: {(hidden < 0).sum()}")
print(f"激活后负数个数: {(hidden_activated < 0).sum()}")
2
3
4
5
6
7
8
输出:
[激活后] hidden: (7, 32)
激活前负数个数: 112
激活后负数个数: 0
2
3
ReLU 做的事很简单:负数全部变成 0,正数保持不变。形状没变,但数值分布变了——这就是"非线性"。
如果想用 GELU,可以这样写:
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2/np.pi) * (x + 0.044715 * x**3)))
2
现代大模型基本都用 GELU 或它的变体(比如 Llama 用的 SwiGLU),但原理都一样:在升维之后引入非线性。
# 第四步:第二层线性变换(降维)
升维 + 激活之后,再用一个 (32, 8) 的矩阵把维度降回 8:
# 第二层权重和偏置
W2 = np.random.randn(d_ff, d_model) # (32, 8)
b2 = np.random.randn(d_model) # (8,)
# 降维
output = hidden_activated @ W2 + b2
print(f"[降维后] output: {output.shape}") # (7, 8)
print(f"输入形状: {x.shape}")
print(f"输出形状: {output.shape}")
print(f"形状一致: {x.shape == output.shape}")
2
3
4
5
6
7
8
9
10
输出:
[降维后] output: (7, 8)
输入形状: (7, 8)
输出形状: (7, 8)
形状一致: True
2
3
4
输入是 (7, 8),输出也是 (7, 8),形状完全一致。这也是为什么 FFN 可以嵌在每一层 Transformer Block 里——它不会改变数据的"外形",只改变内在的"信息含量"。
# 为什么要扩 4 倍?
可以从两个角度理解:
① 从表达能力的角度
非线性函数需要在一个"足够宽"的空间里发挥作用。如果中间层太窄,激活函数能捕捉的特征组合就很有限;太宽又会让参数量暴涨、训练变慢。
实验证明,4 倍既有足够的表达空间,又不会太贵。
② 从计算平衡的角度
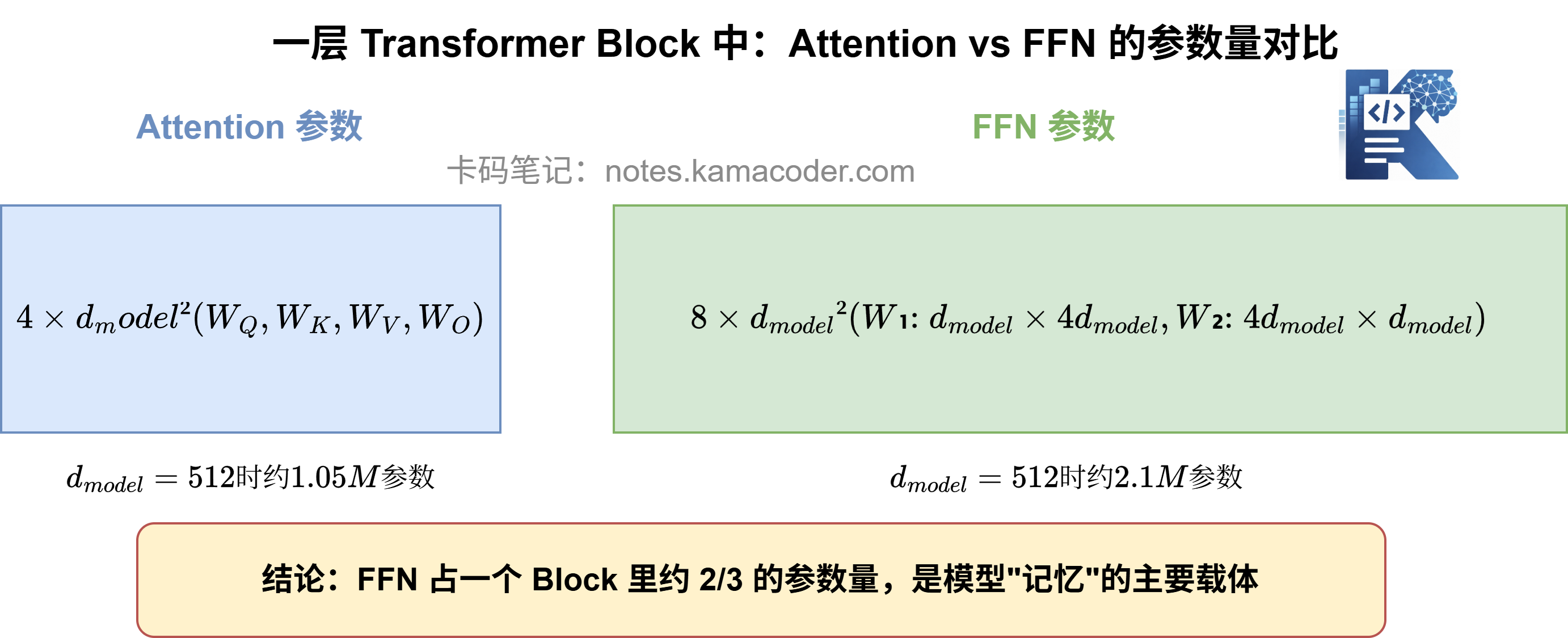
在一层 Transformer Block 里,Attention 和 FFN 的参数量大致相当:
- Attention 部分:4 个矩阵(),每个 ,共
- FFN 部分:2 个矩阵,
当 时,FFN 参数量 = ,恰好是 Attention 的 2 倍。
这也解释了一个常见的事实:Transformer 参数量里,FFN 往往占大头(约三分之二)。模型里真正的"知识存储",很大一部分就藏在 FFN 的这两个大矩阵里。
# 完整代码:把四步打包成一个类
import numpy as np
class FeedForwardNetwork:
def __init__(self, d_model, d_ff, activation='relu'):
"""
Feed-Forward Network
参数:
d_model: 输入/输出维度
d_ff: 中间层维度(通常 = 4 * d_model)
activation: 激活函数类型 'relu' 或 'gelu'
"""
# 两层线性变换的权重
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros(d_ff)
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros(d_model)
self.activation = activation
def _activate(self, x):
if self.activation == 'relu':
return np.maximum(0, x)
elif self.activation == 'gelu':
return 0.5 * x * (1 + np.tanh(
np.sqrt(2/np.pi) * (x + 0.044715 * x**3)
))
def forward(self, x):
# ① 第一层:升维
hidden = x @ self.W1 + self.b1
print(f"[①升维] {x.shape} → {hidden.shape}")
# ② 激活函数:引入非线性
hidden = self._activate(hidden)
print(f"[②激活] shape 不变: {hidden.shape}")
# ③ 第二层:降维
output = hidden @ self.W2 + self.b2
print(f"[③降维] {hidden.shape} → {output.shape}")
return output
# ——— 运行测试 ———
if __name__ == "__main__":
np.random.seed(42)
L, d_model, d_ff = 7, 8, 32
x = np.random.randn(L, d_model)
ffn = FeedForwardNetwork(d_model, d_ff, activation='gelu')
print("=== Feed-Forward Network ===")
out = ffn.forward(x)
print(f"\n输入形状: {x.shape}")
print(f"输出形状: {out.shape}")
print(f"形状一致: {x.shape == out.shape}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
运行输出:
=== Feed-Forward Network ===
[①升维] (7, 8) → (7, 32)
[②激活] shape 不变: (7, 32)
[③降维] (7, 32) → (7, 8)
输入形状: (7, 8)
输出形状: (7, 8)
形状一致: True
2
3
4
5
6
7
8
# 三步流程
| 步骤 | 操作 | 输入形状 | 输出形状 |
|---|---|---|---|
| ① 升维 | |||
| ② 激活 | ReLU / GELU | ||
| ③ 降维 |
整体流程:小 → 大 → 小,先把信息"展开"到高维空间里让激活函数加工,再"压缩"回原维度传给下一层。
FFN 看起来只是两层全连接,但它在 Transformer 里做的事绝不简单:
- 升维 + 激活 + 降维:在高维空间里用非线性提取特征,再压缩回原维度
- 引入非线性:弥补 Self-Attention"只会线性组合"的短板
- 独立加工每个 Token:Attention 负责横向交流,FFN 负责纵向深化
- 承载大部分参数:FFN 参数量约为 Attention 的 2 倍,是模型"记忆"的主要载体
一句话总结:
Attention 让 Token 互相看见,FFN 让每个 Token 真正"消化"看到的信息。
到这里,Transformer Block 的两个核心子模块——Multi-Head Attention 和 FFN——我们都手撕完了。
下一篇文章,我们会把 残差连接 + LayerNorm 也一起手撕出来,然后把这些零件拼成一个完整的 Transformer Encoder Block,大家可以点个关注不迷路~
评论
验证登录状态...