# 手撕Multi-Head Attention:从单头扩展到多头
上一篇文章我们从零实现了最基础的 Attention,走完了 Q、K、V → Softmax → 加权求和的完整流程。
这篇文章我们把**单头 Attention 扩展成 Multi-Head Attention,**一行一行写出来,每一步都打印 shape 验证。
如果你还记得上篇的结论——单头 Attention 的问题是"视角太单一",一次计算只能关注一种语义关系。多头的解法是把维度切开,让多个头并行各司其职。
现在我们就把这个过程真正"手撕"出来。
# 多头比单头多了哪几步?
单头 Attention 的流程是:
X → (W_Q, W_K, W_V) → Q, K, V → Attention → 输出
Multi-Head Attention 只多了三步:
X → (W_Q, W_K, W_V) → Q, K, V
→ 拆分成 h 个头(reshape)
→ 每个头独立跑 Attention
→ 拼接(concat)
→ 乘输出投影矩阵 W_O
→ 最终输出
2
3
4
5
6
就这四个新动作:拆分 → 并行计算 → 拼接 → 输出投影。
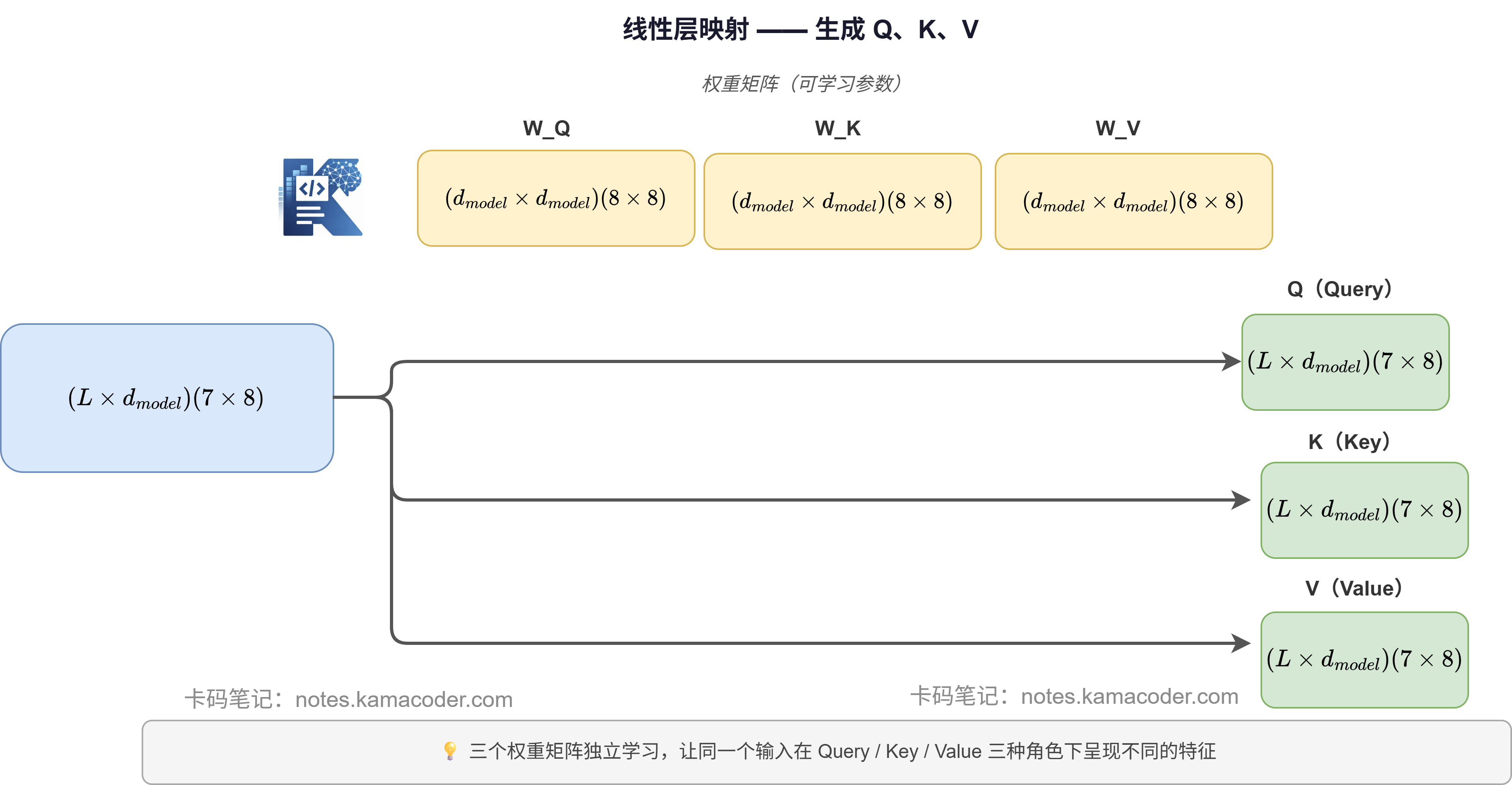
# 第一步:线性层映射,生成 Q、K、V
这一步和单头完全一样。输入 X 分别乘三个权重矩阵,得到 Q、K、V。
import numpy as np
# 超参数设置
L = 7 # 序列长度("远方有颗苹果树",7个字)
d_model = 8 # embedding 维度(实际是512,这里用8方便演示)
h = 2 # 注意力头数(实际常用8或16)
d_k = d_model // h # 每个头的维度 = 8 // 2 = 4
np.random.seed(42)
# 模拟 embedding 后的输入
X = np.random.randn(L, d_model)
print(f"输入 X: {X.shape}") # (7, 8)
# 三个权重矩阵(实际中是可学习参数)
W_Q = np.random.randn(d_model, d_model)
W_K = np.random.randn(d_model, d_model)
W_V = np.random.randn(d_model, d_model)
# 线性映射,得到 Q、K、V
Q = X @ W_Q # (7, 8) @ (8, 8) = (7, 8)
K = X @ W_K
V = X @ W_V
print(f"Q: {Q.shape}") # (7, 8)
print(f"K: {K.shape}") # (7, 8)
print(f"V: {V.shape}") # (7, 8)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
输出:
输入 X: (7, 8)
Q: (7, 8)
K: (7, 8)
V: (7, 8)
2
3
4
Q、K、V 的形状都是 (L, d_model),和单头完全一样。
区别在于下一步:单头直接拿去算 Attention,多头要先把它"切开"。
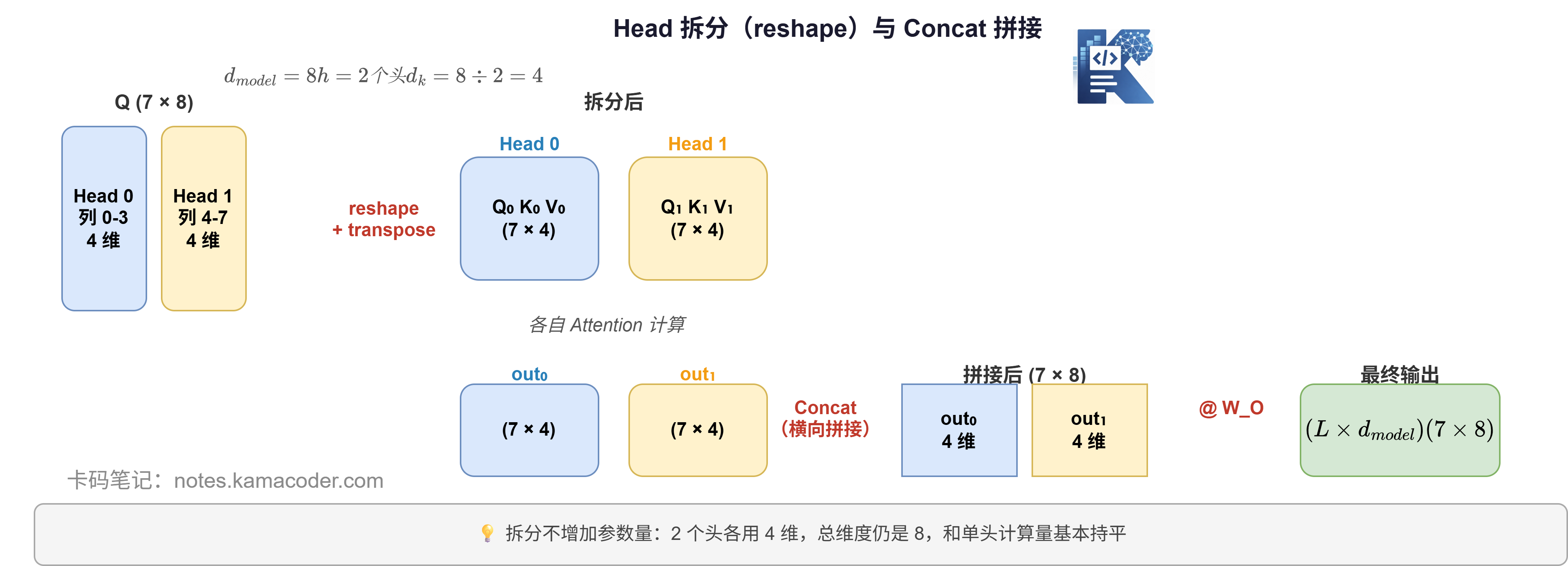
# 第二步:Head 拆分——把 d_model 切成 h 份
这是多头和单头最关键的差异所在。
以 $d_model=8、h=2 d_k = 8 ÷ 2 = 4$ 维:
# reshape: (L, d_model) → (L, h, d_k)
Q_split = Q.reshape(L, h, d_k)
K_split = K.reshape(L, h, d_k)
V_split = V.reshape(L, h, d_k)
print(f"\n拆分后:")
print(f"Q_split: {Q_split.shape}") # (7, 2, 4)
print(f"K_split: {K_split.shape}") # (7, 2, 4)
print(f"V_split: {V_split.shape}") # (7, 2, 4)
# 转置为 (h, L, d_k),方便每个头独立计算
Q_heads = Q_split.transpose(1, 0, 2)
K_heads = K_split.transpose(1, 0, 2)
V_heads = V_split.transpose(1, 0, 2)
print(f"\n转置后(便于并行计算):")
print(f"Q_heads: {Q_heads.shape}") # (2, 7, 4)
print(f"K_heads: {K_heads.shape}") # (2, 7, 4)
print(f"V_heads: {V_heads.shape}") # (2, 7, 4)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
输出:
拆分后:
Q_split: (7, 2, 4)
K_split: (7, 2, 4)
V_split: (7, 2, 4)
转置后(便于并行计算):
Q_heads: (2, 7, 4)
K_heads: (2, 7, 4)
V_heads: (2, 7, 4)
2
3
4
5
6
7
8
9
怎么理解这个 reshape?
原来的 Q 是 (7, 8),也就是 7 个 token,每个 token 8 维。
拆成 (7, 2, 4) 之后,变成:7 个 token,每个 token 有 2 个视角,每个视角 4 维。
转置成 (2, 7, 4) 之后,变成:2 个头,每个头看 7 个 token,每个 token 4 维。
这样第 0 个头和第 1 个头就可以独立并行地做 Attention 计算了。
# 第三步:每个头独立跑 Attention
拆分好之后,每个头的计算和单头完全一样:QKᵀ → 缩放 → Softmax → 加权 V。
def softmax(x):
e = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
def single_head_attention(Q, K, V):
"""单个头的 Attention,输入输出都是 (L, d_k)"""
d_k = Q.shape[-1]
scores = Q @ K.T # (L, L)
scores = scores / np.sqrt(d_k) # 缩放
weights = softmax(scores) # (L, L)
return weights @ V # (L, d_k)
# 对每个头分别计算
head_outputs = []
for i in range(h):
out_i = single_head_attention(Q_heads[i], K_heads[i], V_heads[i])
head_outputs.append(out_i)
print(f"Head {i} 输出: {out_i.shape}") # (7, 4)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
输出:
Head 0 输出: (7, 4)
Head 1 输出: (7, 4)
2
2 个头,每个头输出 (7, 4)。注意:每个头看到的是同一个句子,但是在不同的 4 维子空间里理解它,所以结果是不同的。
# 第四步:Concat 拼接——把多个头合并回来
2 个头算完了,怎么合并?横向拼接,沿着最后一个维度 concat。
# 先把 list 转成数组 (h, L, d_k)
head_outputs = np.stack(head_outputs, axis=0)
print(f"\n拼接前(stack): {head_outputs.shape}") # (2, 7, 4)
# 转置回 (L, h, d_k),再 reshape 成 (L, d_model)
head_outputs = head_outputs.transpose(1, 0, 2)
print(f"转置后: {head_outputs.shape}") # (7, 2, 4)
concat_output = head_outputs.reshape(L, d_model)
print(f"拼接后(reshape): {concat_output.shape}") # (7, 8)
2
3
4
5
6
7
8
9
10
输出:
拼接前(stack): (2, 7, 4)
转置后: (7, 2, 4)
拼接后(reshape): (7, 8)
2
3
两个头各自的 4 维输出拼在一起,重新变回了 8 维。维度和输入 X 完全一样。
# 第五步:输出投影 W_O——让多个头"融合对话"
拼接之后,还差最后一步:乘输出投影矩阵 。
# 输出投影矩阵 W_O: (d_model, d_model)
W_O = np.random.randn(d_model, d_model)
# 最终输出
final_output = concat_output @ W_O
print(f"\n输出投影后: {final_output.shape}") # (7, 8)
print(f"输入 X 形状: {X.shape}") # (7, 8)
print(f"形状是否一致: {final_output.shape == X.shape}")
2
3
4
5
6
7
8
输出:
输出投影后: (7, 8)
输入 X 形状: (7, 8)
形状是否一致: True
2
3
为什么还要乘 W_O?
Concat 之后,8 维向量的前 4 维来自 Head 0,后 4 维来自 Head 1。它们各自是独立计算的,彼此之间还没有"交流"过。
做的事,就是让不同头的信息能够互相混合,产生一个统一的表示,传给后续的 FFN 子层。
# 完整代码:把五步打包成一个函数
import numpy as np
def multi_head_attention(X, W_Q, W_K, W_V, W_O, h):
"""
Multi-Head Attention 完整实现
参数:
X: 输入矩阵, shape (L, d_model)
W_Q, W_K, W_V: 线性投影矩阵, shape (d_model, d_model)
W_O: 输出投影矩阵, shape (d_model, d_model)
h: 注意力头数
返回:
output: shape (L, d_model)
"""
L, d_model = X.shape
d_k = d_model // h
# ① 线性映射
Q = X @ W_Q
K = X @ W_K
V = X @ W_V
print(f"[①线性映射] Q/K/V: {Q.shape}")
# ② 拆分成 h 个头: (L, d_model) → (h, L, d_k)
def split_heads(M):
return M.reshape(L, h, d_k).transpose(1, 0, 2)
Q_h = split_heads(Q)
K_h = split_heads(K)
V_h = split_heads(V)
print(f"[②Head拆分] Q_h/K_h/V_h: {Q_h.shape}")
# ③ 每个头独立计算 Attention
def softmax(x):
e = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
head_outs = []
for i in range(h):
scores = Q_h[i] @ K_h[i].T / np.sqrt(d_k)
attn = softmax(scores) @ V_h[i]
head_outs.append(attn)
print(f"[③并行Attention] 每个head输出: {head_outs[0].shape}")
# ④ Concat 拼接: (h, L, d_k) → (L, d_model)
concat = np.stack(head_outs, axis=0).transpose(1, 0, 2).reshape(L, d_model)
print(f"[④Concat拼接] 拼接后: {concat.shape}")
# ⑤ 输出投影
output = concat @ W_O
print(f"[⑤输出投影] 最终输出: {output.shape}")
return output
# ——— 运行测试 ———
if __name__ == "__main__":
np.random.seed(42)
L, d_model, h = 7, 8, 2
X = np.random.randn(L, d_model)
W_Q = np.random.randn(d_model, d_model)
W_K = np.random.randn(d_model, d_model)
W_V = np.random.randn(d_model, d_model)
W_O = np.random.randn(d_model, d_model)
print("=== Multi-Head Attention ===")
out = multi_head_attention(X, W_Q, W_K, W_V, W_O, h)
print(f"\n输入形状: {X.shape}")
print(f"输出形状: {out.shape}")
print(f"形状一致: {X.shape == out.shape}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
运行输出:
=== Multi-Head Attention ===
[①线性映射] Q/K/V: (7, 8)
[②Head拆分] Q_h/K_h/V_h: (2, 7, 4)
[③并行Attention] 每个head输出: (7, 4)
[④Concat拼接] 拼接后: (7, 8)
[⑤输出投影] 最终输出: (7, 8)
输入形状: (7, 8)
输出形状: (7, 8)
形状一致: True
2
3
4
5
6
7
8
9
10
# 五步流程
| 步骤 | 操作 | 输入形状 | 输出形状 |
|---|---|---|---|
| ① 线性映射 | X 乘 | ||
| ② Head 拆分 | reshape + transpose | $ (L, d_model) $ | |
| ③ 并行 Attention | 每个头独立跑完整 Attention | ||
| ④ Concat 拼接 | transpose + reshape | ||
| ⑤ 输出投影 | 乘 | ( |
从头到尾,输入是 ,输出还是 。中间经历了一次维度的"分家"再"合并",但整体维度始终保持一致,这也是 Transformer 能一层层堆叠的基础。
这篇文章我们把 Multi-Head Attention 的五个步骤完整手撕了一遍,代码加注释不到 60 行。
核心只有一句话:
多头不是"用更多参数",而是"用同样的参数,在多个子空间里并行理解语言"。
下一篇文章,我们将带大家手撕FFN,大家可以点个关注不迷路哦~
评论
验证登录状态...