# 手撕Tiny Transformer:从零拼出一个完整模型
前面几篇文章,我们已经分别手撕了 Attention、Multi-Head Attention、FFN、残差连接和 LayerNorm,以及一个Transformer Blok。
但到目前为止,它们还只是一个个零件。
这篇文章我们要做最后一步:把这些零件拼起来,写出一个最小可运行的 Tiny Transformer。
# 整体结构
一个最小版 Transformer,可以拆成四层:
Token ID
↓ Embedding
↓ Positional Encoding
↓ 多层 Transformer Block
↓ 输出层 Linear
↓ logits
2
3
4
5
6
核心变化只有一个:一开始输入是整数 Token ID,经过 Embedding 后变成向量;之后所有模块都在处理 (L, d_model) 这个矩阵。
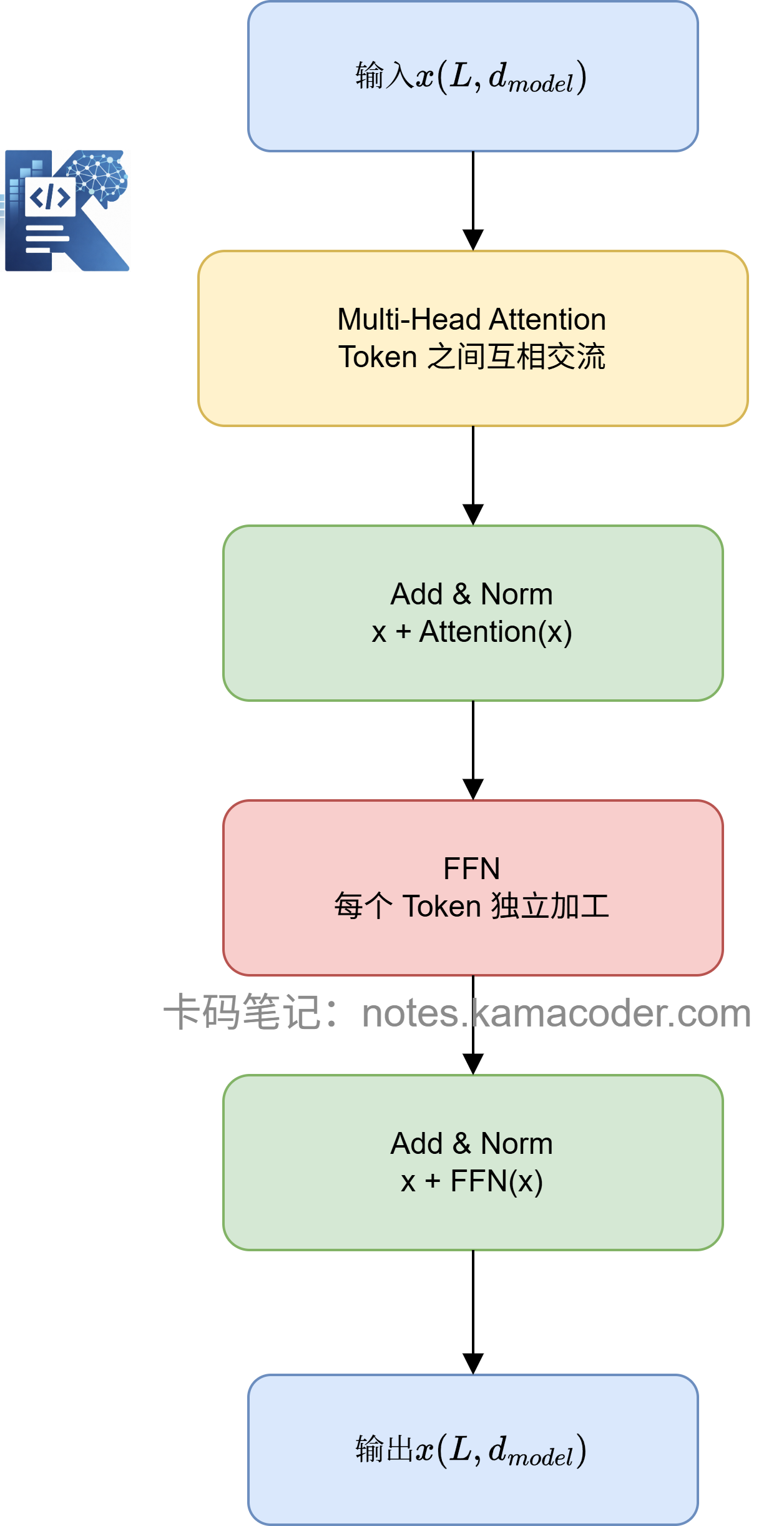
# 第一步:Embedding
模型不能直接理解文字,也不能直接理解 Token ID。比如一句话被切成:
input_ids = [3, 8, 2, 6]
这些数字只是编号,没有语义。
Embedding 要做的事,就是把每个编号查表,变成一个向量。
import numpy as np
np.random.seed(42)
vocab_size = 10
L = 4
d_model = 8
input_ids = np.array([3, 8, 2, 6])
embedding_table = np.random.randn(vocab_size, d_model)
x = embedding_table[input_ids]
print(x.shape) # (4, 8)
2
3
4
5
6
7
8
9
10
11
12
13
现在,4 个 Token,每个 Token 都变成了 8 维向量。
# 第二步:Positional Encoding
Self-Attention 本身不关心顺序。对它来说,“我喜欢你”和“你喜欢我”如果只看 Token 集合,差别并不明显。
所以我们要把位置信息加进去。
def positional_encoding(L, d_model):
pe = np.zeros((L, d_model))
for pos in range(L):
for i in range(0, d_model, 2):
pe[pos, i] = np.sin(pos / (10000 ** (i / d_model)))
if i + 1 < d_model:
pe[pos, i + 1] = np.cos(pos / (10000 ** (i / d_model)))
return pe
x = x + positional_encoding(L, d_model)
print(x.shape) # (4, 8)
2
3
4
5
6
7
8
9
10
11
注意:位置编码不是拼接,而是相加。所以 shape 不变,仍然是 (L, d_model)。
# 第三步:Transformer Block
一个 Block 里有两件事:
Attention:让 Token 之间交换信息
FFN:让每个 Token 独立加工信息
2
再加上残差连接和 LayerNorm,一个最小 Block 长这样:
class TinyBlock:
def __init__(self, d_model, d_ff):
self.Wq = np.random.randn(d_model, d_model) * 0.01
self.Wk = np.random.randn(d_model, d_model) * 0.01
self.Wv = np.random.randn(d_model, d_model) * 0.01
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros(d_ff)
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros(d_model)
def layer_norm(self, x, eps=1e-5):
mean = x.mean(axis=-1, keepdims=True)
std = x.std(axis=-1, keepdims=True)
return (x - mean) / (std + eps)
def attention(self, x):
Q = x @ self.Wq
K = x @ self.Wk
V = x @ self.Wv
scores = Q @ K.T / np.sqrt(x.shape[-1])
weights = np.exp(scores) / np.exp(scores).sum(axis=-1, keepdims=True)
return weights @ V
def ffn(self, x):
hidden = np.maximum(0, x @ self.W1 + self.b1)
return hidden @ self.W2 + self.b2
def forward(self, x):
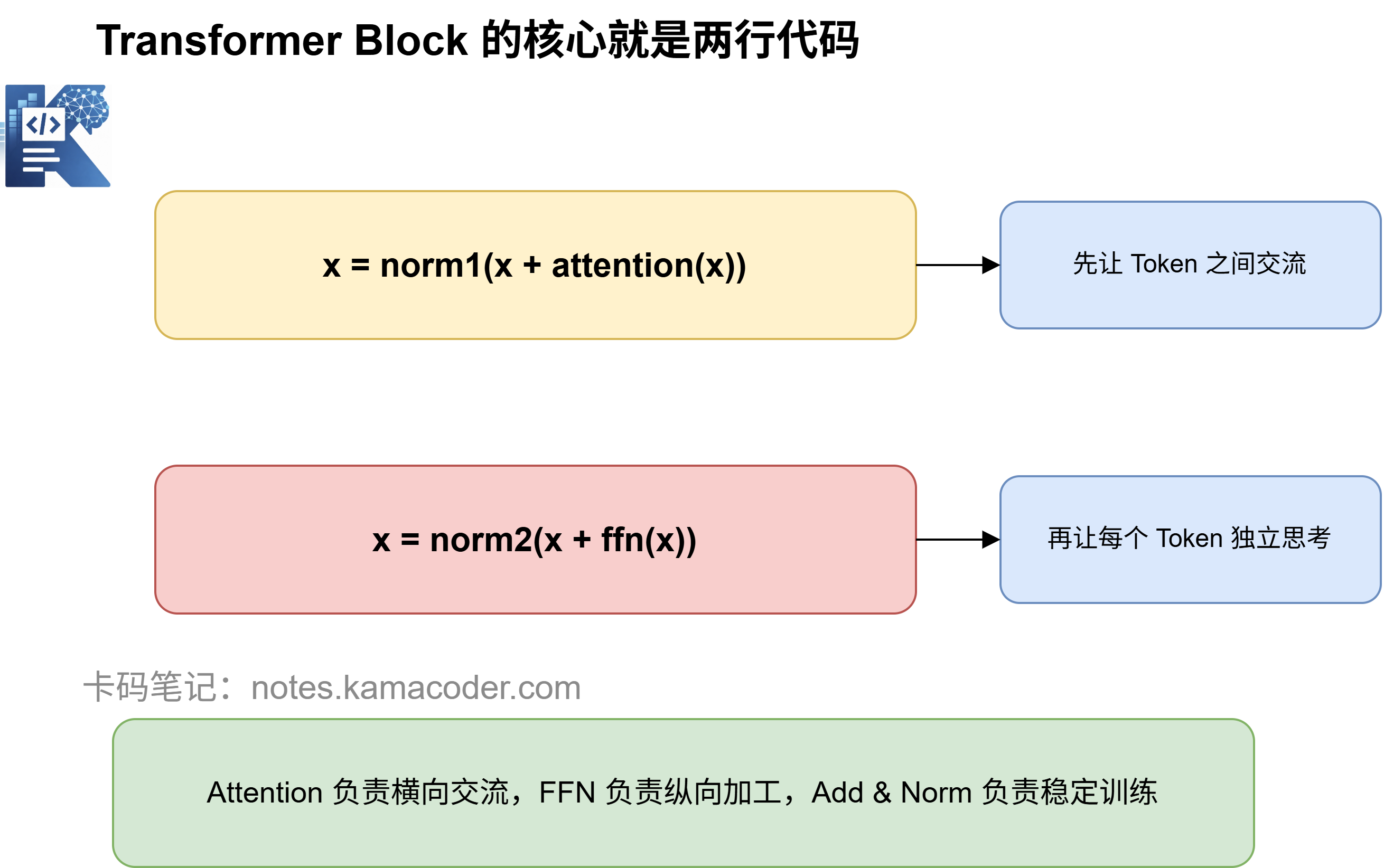
x = self.layer_norm(x + self.attention(x))
x = self.layer_norm(x + self.ffn(x))
return x
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这段代码没有多头,没有 mask,也没有训练,只保留最核心的数据流。
# 第四步:堆多层 Block
Transformer 的“深度”来自重复堆叠 Block。
blocks = [TinyBlock(d_model=8, d_ff=32) for _ in range(2)]
for block in blocks:
x = block.forward(x)
print(x.shape) # (4, 8)
2
3
4
5
6
堆两层、六层、十二层,本质都是重复同一个结构。只要每层输入输出 shape 一致,就可以一直往下接。
# 第五步:输出层
最后一步,要把每个 Token 的隐藏向量映射回词表大小。
如果词表大小是 vocab_size=10,那输出层就是:
W_out = np.random.randn(d_model, vocab_size) * 0.01
b_out = np.zeros(vocab_size)
logits = x @ W_out + b_out
print(logits.shape) # (4, 10)
2
3
4
5
logits[0] 表示第 1 个位置对词表中 10 个 Token 的打分。
打分最高的 Token,就是模型当前最想输出的结果。
# 最小可运行 Demo
把所有代码连起来:
import numpy as np
np.random.seed(42)
vocab_size = 10
L = 4
d_model = 8
d_ff = 32
num_layers = 2
input_ids = np.array([3, 8, 2, 6])
embedding_table = np.random.randn(vocab_size, d_model)
x = embedding_table[input_ids]
# positional encoding
def positional_encoding(L, d_model):
pe = np.zeros((L, d_model))
for pos in range(L):
for i in range(0, d_model, 2):
pe[pos, i] = np.sin(pos / (10000 ** (i / d_model)))
if i + 1 < d_model:
pe[pos, i + 1] = np.cos(pos / (10000 ** (i / d_model)))
return pe
x = x + positional_encoding(L, d_model)
class TinyBlock:
def __init__(self, d_model, d_ff):
self.Wq = np.random.randn(d_model, d_model) * 0.01
self.Wk = np.random.randn(d_model, d_model) * 0.01
self.Wv = np.random.randn(d_model, d_model) * 0.01
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros(d_ff)
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros(d_model)
def layer_norm(self, x, eps=1e-5):
mean = x.mean(axis=-1, keepdims=True)
std = x.std(axis=-1, keepdims=True)
return (x - mean) / (std + eps)
def attention(self, x):
Q = x @ self.Wq
K = x @ self.Wk
V = x @ self.Wv
scores = Q @ K.T / np.sqrt(x.shape[-1])
weights = np.exp(scores) / np.exp(scores).sum(axis=-1, keepdims=True)
return weights @ V
def ffn(self, x):
hidden = np.maximum(0, x @ self.W1 + self.b1)
return hidden @ self.W2 + self.b2
def forward(self, x):
x = self.layer_norm(x + self.attention(x))
x = self.layer_norm(x + self.ffn(x))
return x
blocks = [TinyBlock(d_model, d_ff) for _ in range(num_layers)]
for block in blocks:
x = block.forward(x)
W_out = np.random.randn(d_model, vocab_size) * 0.01
b_out = np.zeros(vocab_size)
logits = x @ W_out + b_out
print("最终输出 logits shape:", logits.shape)
print("每个位置预测的 token:", logits.argmax(axis=-1))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
输出示例:
最终输出 logits shape: (4, 10)
每个位置预测的 token: [5 5 4 3]
2
到这里,一个 Tiny Transformer 就真的跑起来了。
它还不会写文章,也不会聊天,因为我们没有训练它。但结构已经完整了:Embedding 负责把 ID 变成向量,位置编码负责告诉模型顺序,Block 负责反复加工信息,输出层负责把向量变回词表打分。
Transformer 最核心的秘密,其实就是这条数据流:
ID → 向量 → 加位置 → 多层加工 → 词表打分
理解了这条线,再看 GPT、BERT、LLaMA,就不再是一团黑盒了。
至此,我们的手撕代码阶段就告一段落了,接下来,我们将进入BERT / T5 / GPT / MoE的学习阶段,带大家从标准 Transformer 过渡到主流模型家族。可以点个关注不迷路哦~
评论
验证登录状态...