# 手撕LayerNorm与残差连接:别让基础组件被忽略
上一篇文章我们把 FFN 从零手撕了一遍,走完了升维 → 激活 → 降维的完整流程。
这篇文章我们来手撕两个长期被"配角化"的组件:残差连接(Residual Connection) 和 层归一化(LayerNorm)。
它们看起来简单,代码加起来不超过 20 行,但缺了任何一个,Transformer 就跑不深。
# 残差连接
残差连接的公式只有一行:
是子层的输出(比如 Attention 或 FFN 的结果), 是这一层的输入。两者直接相加。
就这么简单?就这么简单。
但它解决了一个深层网络的根本问题:梯度消失。
反向传播时,梯度需要从最后一层一路流回第一层。每穿过一层,就要乘一次该层的导数,如果导数很小(比如 Sigmoid 激活区域),链式相乘下来,梯度会指数级缩小,前面几层根本收不到有效的训练信号。
残差连接的巧妙在于:它给梯度提供了一条**"高速公路"**,可以绕过中间层直接流回去,不需要每一层都"乘一遍"。
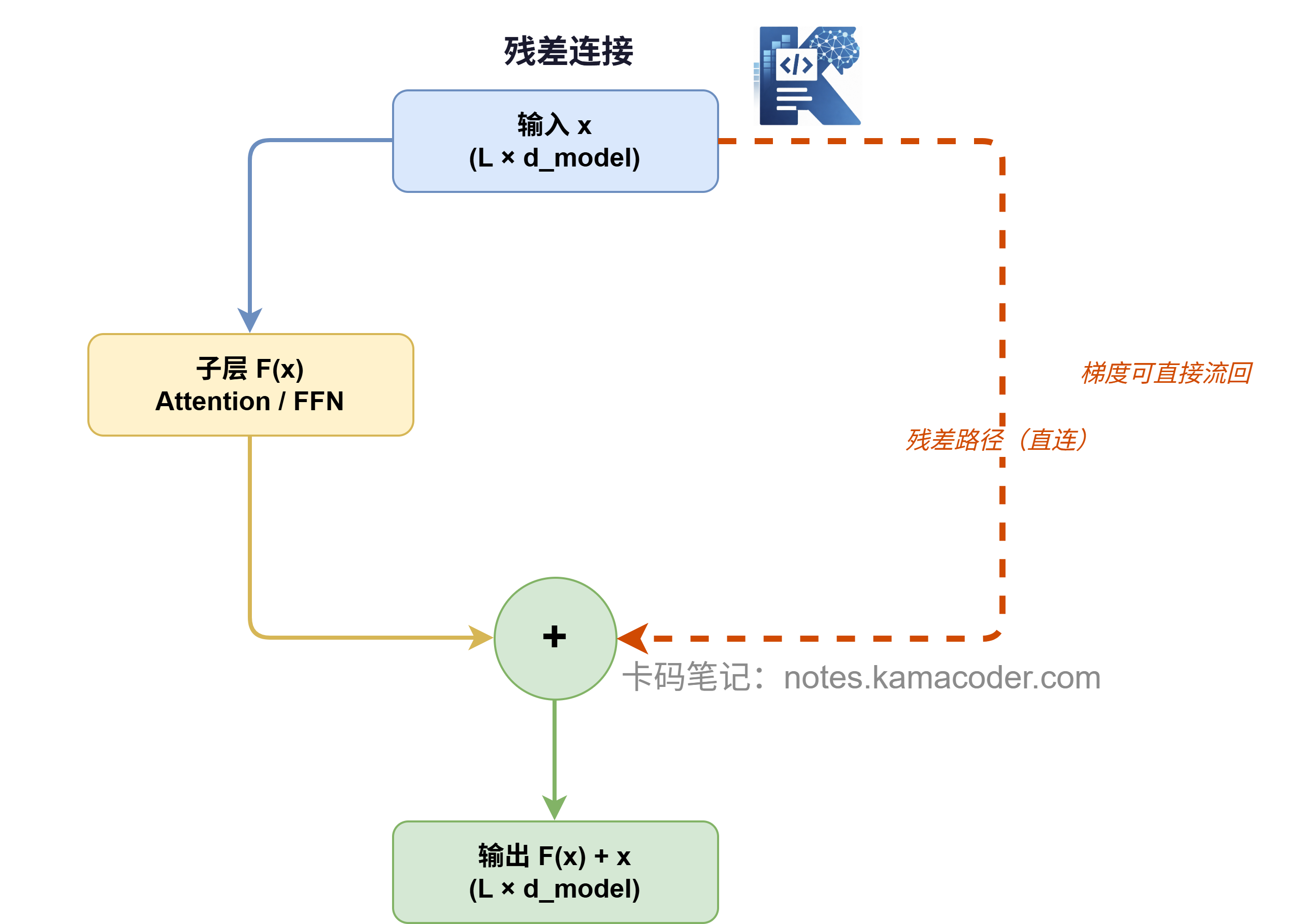
代码里实现残差非常直接:
import numpy as np
def residual_connection(x, sublayer_output):
"""
残差连接:直接相加
参数:
x: 子层的输入, shape (L, d_model)
sublayer_output: 子层的输出, shape (L, d_model)
返回:
shape (L, d_model),和输入完全一致
"""
return x + sublayer_output
# 测试
L, d_model = 7, 8
np.random.seed(42)
x = np.random.randn(L, d_model) # 子层输入
sublayer_out = np.random.randn(L, d_model) # 子层输出(模拟)
output = residual_connection(x, sublayer_out)
print(f"输入形状: {x.shape}") # (7, 8)
print(f"子层输出: {sublayer_out.shape}") # (7, 8)
print(f"残差输出: {output.shape}") # (7, 8)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
输出:
输入形状: (7, 8)
子层输出: (7, 8)
残差输出: (7, 8)
2
3
就是一个加法,形状完全不变。但正是这个加法,让 Transformer 能稳定地堆到 100 多层。
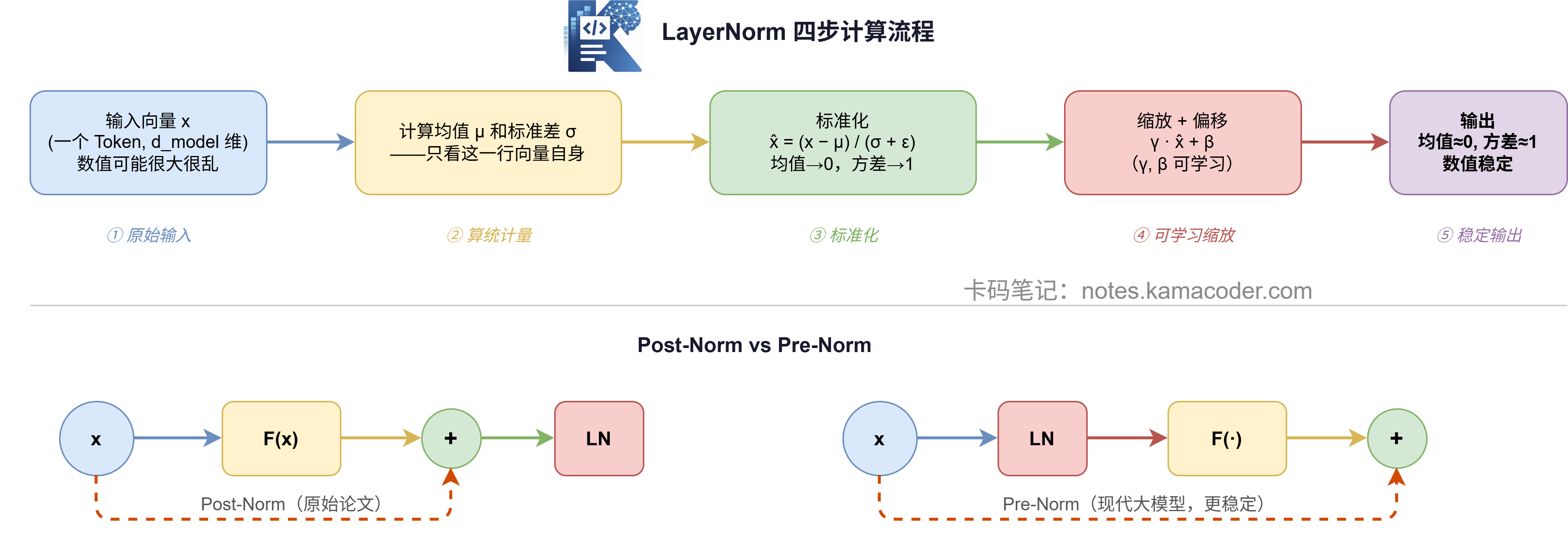
# LayerNorm
残差相加之后,数值的范围可能变得很大或者很不均匀——有的维度值极大,有的极小。进入下一层计算时,这种不稳定会严重影响训练效果。
LayerNorm 要做的事,就是把每个 Token 的向量归一化:均值变成 0,方差变成 1。
公式如下:
一共四步:
- 算这个向量的均值
- 算这个向量的标准差
- 用 标准化,每个维度都"缩"到均值 0、方差 1
- 再乘 (缩放)、加 (偏移)——这两个是可学习参数,让模型自己决定"归一化到什么程度"
其中 是一个很小的数(比如 1e-5),防止分母为 0。
class LayerNorm:
def __init__(self, d_model, eps=1e-5):
"""
LayerNorm
参数:
d_model: 向量维度
eps: 防止除零的小常数
"""
self.gamma = np.ones(d_model) # 可学习缩放参数,初始化为 1
self.beta = np.zeros(d_model) # 可学习偏移参数,初始化为 0
self.eps = eps
def forward(self, x):
"""
x: shape (L, d_model)
"""
# 对每个 Token(每一行)分别计算均值和标准差
mu = x.mean(axis=-1, keepdims=True) # (L, 1)
sigma = x.std(axis=-1, keepdims=True) # (L, 1)
# 标准化
x_norm = (x - mu) / (sigma + self.eps) # (L, d_model)
# 缩放 + 偏移(广播到每一行)
return self.gamma * x_norm + self.beta # (L, d_model)
# 测试
np.random.seed(42)
L, d_model = 7, 8
x = np.random.randn(L, d_model) * 10 # 故意放大数值,模拟数值不稳定的情况
ln = LayerNorm(d_model)
output = ln.forward(x)
print(f"归一化前 - 均值: {x.mean():.2f}, 标准差: {x.std():.2f}")
print(f"归一化后 - 均值: {output.mean():.4f}, 标准差: {output.std():.4f}")
print(f"输入形状: {x.shape}, 输出形状: {output.shape}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
输出:
归一化前 - 均值: -0.37, 标准差: 9.87
归一化后 - 均值: 0.0000, 标准差: 1.0000
输入形状: (7, 8), 输出形状: (7, 8)
2
3
输入的标准差接近 10,归一化之后变成了 1——数值被"拉"回了合理范围,而形状完全不变。
# 把两者拼在一起 Add & Norm
在 Transformer 里,残差连接和 LayerNorm 从来不分家,标准写法叫 Add & Norm:
先加(残差),再归一化(LayerNorm)。每个子模块——无论是 Attention 还是 FFN——后面都跟一个这样的结构。
def add_and_norm(x, sublayer_output, layer_norm):
"""
Add & Norm:残差连接 + LayerNorm
参数:
x: 子层输入, shape (L, d_model)
sublayer_output: 子层输出, shape (L, d_model)
layer_norm: LayerNorm 实例
返回:
shape (L, d_model)
"""
return layer_norm.forward(x + sublayer_output)
# 完整测试
np.random.seed(42)
L, d_model = 7, 8
x = np.random.randn(L, d_model)
attn_output = np.random.randn(L, d_model) # 模拟 Attention 子层的输出
ffn_output = np.random.randn(L, d_model) # 模拟 FFN 子层的输出
ln1 = LayerNorm(d_model)
ln2 = LayerNorm(d_model)
# Attention 子层 → Add & Norm
after_attn = add_and_norm(x, attn_output, ln1)
print(f"Attention 子层后: {after_attn.shape}") # (7, 8)
# FFN 子层 → Add & Norm
after_ffn = add_and_norm(after_attn, ffn_output, ln2)
print(f"FFN 子层后: {after_ffn.shape}") # (7, 8)
print(f"\n输入形状: {x.shape}")
print(f"输出形状: {after_ffn.shape}")
print(f"形状一致: {x.shape == after_ffn.shape}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
输出:
Attention 子层后: (7, 8)
FFN 子层后: (7, 8)
输入形状: (7, 8)
输出形状: (7, 8)
形状一致: True
2
3
4
5
6
# Post-Norm vs Pre-Norm
上面写的是 Post-Norm,也就是原始论文的做法:先算子层,后归一化。
但现代大模型(比如 Llama、GPT-3)基本都改成了 Pre-Norm:先归一化,再算子层。
两者差别只有一行代码,效果却不同:Pre-Norm 的训练更稳定,在层数很深(几十层以上)时尤为明显。
# Post-Norm(原始 Transformer)
def post_norm(x, sublayer_fn, layer_norm):
return layer_norm.forward(x + sublayer_fn(x))
# Pre-Norm(现代大模型)
def pre_norm(x, sublayer_fn, layer_norm):
return x + sublayer_fn(layer_norm.forward(x))
2
3
4
5
6
7
记住这两种写法的区别,面试或者读源码时会频繁遇到。
# 步骤汇总
| 组件 | 公式 | 核心作用 |
|---|---|---|
| 残差连接 | 给梯度留高速公路,防止深层网络训练崩 | |
| LayerNorm | 把每个 Token 的向量拉回均值 0、方差 1 | |
| Add & Norm | 两者捆绑,每个子层后面都挂一个 |
到这里,Transformer Block 的所有零件——Multi-Head Attention、FFN、残差连接、LayerNorm——我们都手撕完了。
下一篇文章,我们会把这些零件真正拼成一个完整的 Transformer Encoder Block,一行一行跑通完整的前向过程,大家点个关注不迷路~
评论
验证登录状态...