# 大模型简历中的"难点"怎么挖?10个典型难点示例,直接套用
之前讲四要素写法的时候,很多录友反馈:项目描述、个人工作、个人收获都能写,唯独"项目难点"不知道怎么挖。
"我的项目没什么难点啊""就是调API,能有什么难的""难点不就是幻觉吗,大家都一样"——这是我在知识星球 (opens new window)里听到最多的三句话。
说实话,不是你的项目没难点,是你不知道什么算难点。
项目难点不是"大模型存在幻觉"这种行业共识,是你在具体场景下遇到了什么问题、你怎么解决的。每个做过大模型项目的人,都踩过坑——那些坑,就是你的难点。
今天按RAG、Agent、微调、部署四个方向,给出10个典型难点,每个都是"问题→方案→效果"的完整写法,直接套用。
先看一张总览图:
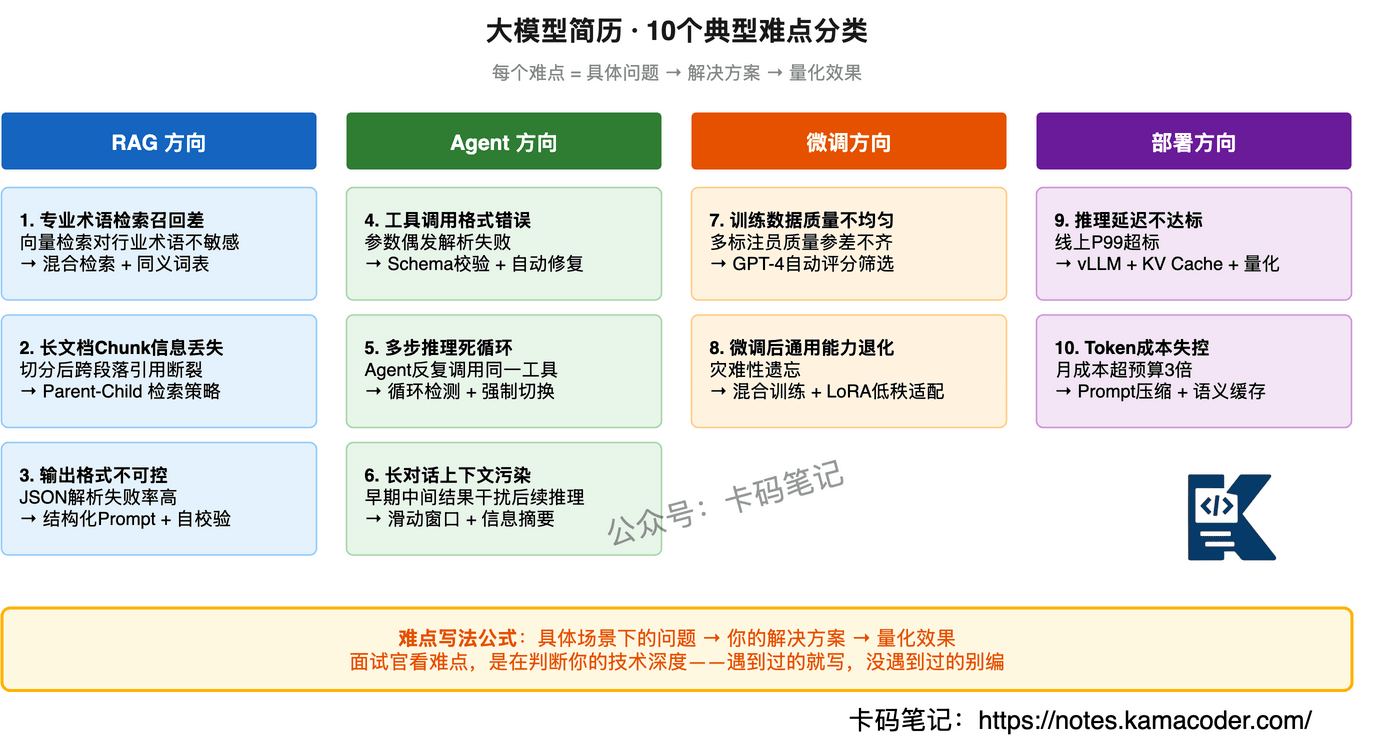
# 难点挖掘的核心思路
很多录友写难点,写成了这样:
反面写法
- 大模型存在幻觉问题
- 检索效果不太好
- 推理延迟比较高
这不是难点,这是问题描述。面试官想看的不是你遇到了什么问题——谁都会遇到——而是你怎么解决的。
难点的正确结构:具体场景下的问题 → 你的解决方案 → 量化效果
记住这个公式,下面10个难点全是按这个结构写的。
# RAG方向:3个典型难点
RAG是目前大模型项目最多的方向,难点也最集中。如果你对RAG面试追问感兴趣,可以看RAG大厂面试题汇总,里面有面试官追问的完整套路。
# 难点1:专业术语检索召回差
问题:向量检索对通用语义理解不错,但遇到行业专业术语(如医疗、法律、金融领域),召回率明显下降。用户搜"房颤消融术后抗凝方案",检索结果全是"心脏手术"的泛泛内容。
简历写法
难点:向量检索对专业术语召回率不足(医疗领域Top5召回率仅58%),通过引入BM25关键词检索+向量检索的混合策略,并针对领域术语构建同义词表,Top5召回率从58%提升至89%
面试官追问方向:BM25和向量检索的权重怎么调的?同义词表怎么维护的?为什么不用Rerank?
# 难点2:长文档Chunk切分信息丢失
问题:文档切分后,单个Chunk丢失了上下文信息。比如一份合同,第3段写的是"甲方应在上述期限内完成交付"——但"上述期限"在第1段定义的,切分后第3段的Chunk根本不知道期限是多久。
简历写法
难点:长文档Chunk切分导致跨段落引用信息丢失(合同/法规类文档尤为严重),设计Parent-Child检索策略——子Chunk用于精确匹配,命中后自动扩展至父Chunk获取完整上下文,召回率从65%提升至87%
# 难点3:大模型输出格式不可控
问题:要求模型返回JSON格式,但实际输出经常夹带解释文字、格式错乱、字段缺失。线上服务JSON解析失败率高达35%。
简历写法
难点:大模型输出JSON格式不可控(线上解析失败率35%),引入结构化Prompt约束+输出自校验+失败重试机制,解析失败率降至3%
面试官追问方向:结构化Prompt具体怎么写的?自校验逻辑是什么?重试几次?重试还失败怎么办?
# Agent方向:3个典型难点
Agent项目的难点比RAG更隐蔽,很多问题在Demo阶段根本不会暴露,上了真实场景才炸。Agent方向的面试追问可以看Agent大厂面试题汇总。
# 难点4:工具调用偶发格式错误
问题:模型生成的Function Calling参数偶尔格式不对——JSON多了个逗号、参数类型错误、必填字段缺失。Demo阶段看不出来,上量之后每100次调用有15次解析失败。
简历写法
难点:Function Calling参数格式偶发错误(100次调用约15次解析失败),引入参数Schema校验+自动修复机制(缺失字段填默认值、类型错误自动转换),调用成功率从85%提升至97%
# 难点5:多步推理死循环
问题:Agent在某些场景下陷入死循环——反复调用同一个工具、在两个步骤之间来回横跳。比如查询库存不足→建议补货→再查库存→还是不足→再建议补货……无限循环。
简历写法
难点:Agent多步推理出现死循环(相同工具连续调用3次以上),设计循环检测机制——记录最近5步的工具调用序列,检测到重复模式后强制切换推理路径或终止并返回中间结果,死循环发生率从12%降至0.5%
# 难点6:长对话上下文污染
问题:Agent执行10步以上的长任务时,早期步骤的中间结果污染了后续推理。比如第2步查到的临时数据,到第8步还在影响决策,但那个数据早就过时了。
简历写法
难点:长对话中早期中间结果污染后续推理(10步以上任务准确率下降40%),设计滑动窗口+关键信息摘要机制——只保留最近3步完整上下文,历史步骤压缩为结论摘要,长任务准确率恢复至正常水平
# 微调方向:2个典型难点
# 难点7:训练数据质量不均匀
问题:SFT训练数据来自多个标注员,标注质量参差不齐。有的标注员回答详细准确,有的敷衍了事。模型训练后输出质量不稳定,同类问题有时回答很好有时很差。
简历写法
难点:多标注员数据质量不均匀导致模型输出不稳定,设计数据清洗流程——基于GPT-4自动评分筛选高质量样本(保留评分>4的样本,淘汰率约30%),清洗后模型输出一致性评分从3.2提升至4.1(5分制)
# 难点8:微调后通用能力退化
问题:在垂直领域数据上微调后,模型在目标领域表现提升了,但通用对话能力明显下降——回答变得生硬、不会闲聊了、格式也变奇怪了。这就是灾难性遗忘。
简历写法
难点:领域微调后通用能力退化(通用评测下降15%),采用混合训练策略——领域数据与通用对话数据按7:3混合,并引入LoRA低秩适配减少参数修改范围,领域准确率提升22%的同时通用能力仅下降2%
# 部署方向:2个典型难点
# 难点9:推理延迟不满足线上要求
问题:7B模型单次推理延迟2.5秒,线上要求P99<1秒。用户等不了这么久,体验很差。
简历写法
难点:7B模型推理延迟2.5s不满足线上P99<1s要求,采用vLLM部署+KV Cache优化+INT8量化,推理延迟降至0.6s;同时引入流式输出,用户首token延迟<200ms,体感延迟大幅改善
# 难点10:Token成本失控
问题:RAG系统每次请求平均消耗4000 token,日均10万次请求,月成本超过预算3倍。老板说再不降成本就砍项目。
简历写法
难点:RAG系统Token消耗过高(单次请求平均4000 token,月成本超预算3倍),通过Prompt压缩(去除冗余检索结果)+语义缓存(相似问题命中缓存直接返回)+短文本走小模型分流,单次请求Token降至1500,月成本降低65%
# 怎么从自己的项目里挖难点
看完10个示例,你可能会说:"这些难点我的项目里没遇到啊。"
不可能。 只要你真做过项目,一定踩过坑。问自己这几个问题:
- 项目上线/演示的时候,翻车过吗? 翻车的原因就是难点
- 有没有某个环节调了很久才调好? 调的过程就是难点
- 有没有某个方案试了不行,换了另一个? 选型过程就是难点
- 有没有某个指标一开始很差,后来优化上去了? 优化过程就是难点
难点不在项目大小,在你有没有真的去解决问题。 一个课程项目,如果你认真调过检索策略、认真处理过幻觉、认真优化过延迟,这些都是实打实的难点。
# 难点写法的3个常见坑
1、难点太泛
"检索效果不好"——什么场景下不好?哪一步出了问题?是embedding选错了?chunk太大了?没有rerank?具体到某一步,面试官才觉得你真做过。
2、只写问题不写方案
"大模型存在幻觉"——这是行业共识,不是你的难点。你做了什么来降低幻觉?写出来。
3、方案没有效果
"引入了Rerank重排序"——然后呢?效果提升了多少?没有量化效果的方案,面试官不知道你做的有没有用。
项目难点是简历里最值钱的部分。 面试官看项目描述和个人工作,是在了解你做了什么;看项目难点,是在判断你的技术深度。10个典型难点,对号入座,套用到自己的项目里。
下一篇讲量化指标怎么写——解决"我的项目没有指标"的痛点。
评论
验证登录状态...