# RAG项目简历怎么写?别再写"调了LangChain搭了RAG",向量检索、混合检索、Rerank亮点这么写才对
RAG项目是大模型简历里出现频率最高的项目类型,没有之一。
但我在知识星球 (opens new window)里看的简历,RAG项目写出来几乎一个样:
- 使用LangChain搭建RAG流程
- 调用OpenAI API实现问答
- 使用Milvus存储向量
- 实现文档解析和智能问答
你这么写,面试官看完就一个感觉:又一个跟着教程跑Demo的。
RAG项目确实容易上手——LangChain的pipeline跑通不难,但跑通和写好之间差了十万八千里。面试官看RAG项目,不是看你有没有搭过RAG,是看你在检索链路上做了什么决策、踩了什么坑、拿到了什么结果。
今天专门讲RAG项目怎么写出技术深度。
# RAG项目,面试官到底想看什么
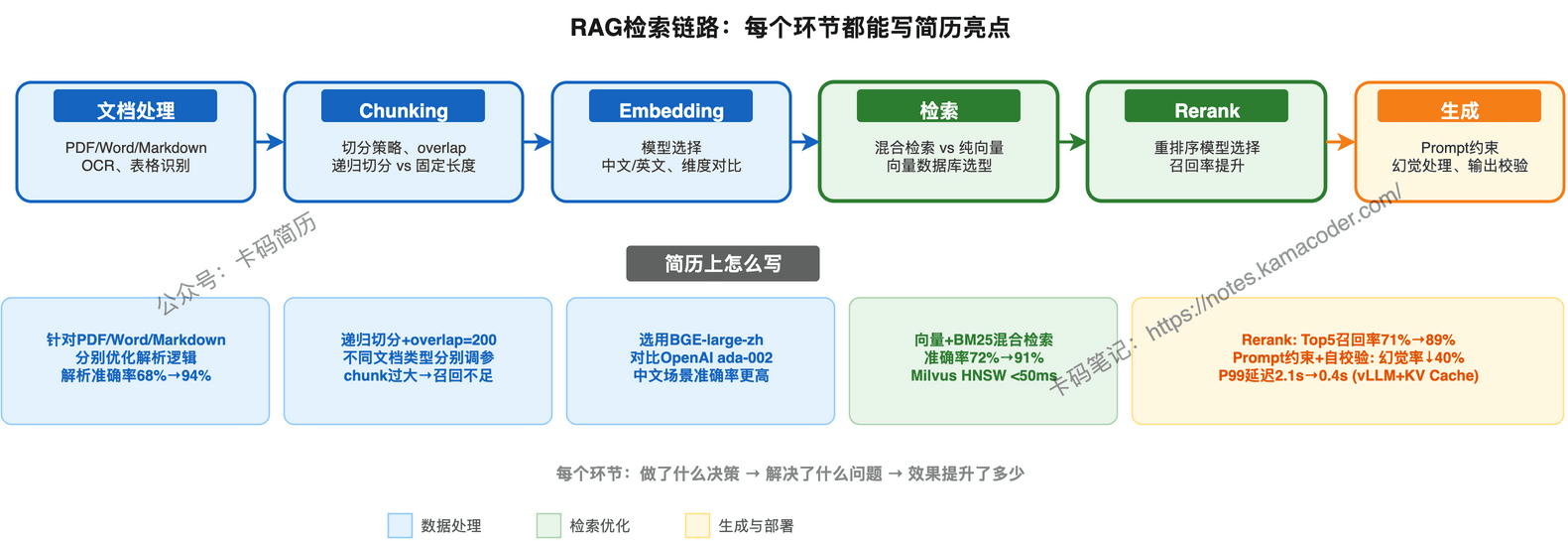
RAG的核心链路是:Query → 文档处理 → Chunking → Embedding → 检索 → Rerank → 生成。
你简历上写的每一行,都应该对应这条链路上的某个环节,并且说清楚你在那个环节做了什么决策。
面试官看RAG项目,重点就三件事:
- 检索策略你怎么设计的? 纯向量还是混合检索?为什么?Chunk怎么切的?Embedding模型怎么选的?
- 检索不准你怎么办的? Rerank加了吗?Query改写了吗?多路召回做了吗?
- 幻觉你怎么处理的? Prompt约束?输出校验?检索结果和生成结果的对齐?
每个环节你做了什么选择、解决了什么问题、效果提升了多少——这才是面试官想看的。
# RAG项目的三个技术深度维度
RAG项目要写出技术深度,从三个维度展开:
# 维度一:检索链路设计
这是最基础的。你得让面试官知道你理解RAG不是"调一次向量检索就完了"。
反面:
- 使用Milvus进行向量检索
面试官:用的什么索引?HNSW还是IVF?检索延迟多少?为什么选Milvus不选其他?
正面:
- 选用Milvus做向量存储,HNSW索引检索延迟<50ms,对比FAISS方案更适合生产环境的多副本部署需求
区别在哪?左边只说"用了什么",右边说了"选了什么、为什么选、效果怎么样"。
# 维度二:优化策略
这是拉开差距的关键。你的RAG项目有没有做过优化?优化了什么?效果如何?
反面:
- 优化了检索效果
面试官:怎么优化的?从多少优化到多少?优化了准确率还是召回率?
正面:
- 设计向量+BM25混合检索策略,准确率从72%提升至91%
- 引入BGE-Reranker对检索结果重排序,Top5召回率从71%提升至89%
- 实现Query改写+多路召回,专业术语查询的召回率提升35%
每一条都是:做了什么优化 → 拿到了什么结果。
# 维度三:量化指标
RAG项目必须有指标。没有指标的RAG项目,面试官会认为你只是跑通了流程,没有做过评估。
RAG项目常见的指标:
- 检索指标:准确率、召回率、MRR、检索延迟、QPS
- 生成指标:幻觉率、答案相关性、可读性评分
- 工程指标:端到端延迟(P50/P99)、Token成本、并发量
反面:
- 优化了系统性能
正面:
- 接口P99延迟从2.1s优化至0.4s(vLLM部署+KV Cache+流式输出)
- 单次查询Token消耗从1200降至400(Prompt压缩+上下文裁剪),推理成本降低60%
# 完整反面/正面对比
同一个RAG项目,两种写法:
反面:
基于大模型的智能问答系统
- 使用LangChain搭建RAG流程
- 调用OpenAI GPT-4 API实现问答
- 使用Milvus存储向量
- 实现文档解析和智能问答
- 部署到服务器上
正面:
基于RAG架构的企业知识库问答系统,面向10万+内部员工的知识检索场景,实现文档自动解析、语义检索与智能生成
个人工作:
- 设计向量+BM25混合检索策略,准确率从72%提升至91%
- 实现递归切分+overlap=200的Chunk策略,针对PDF/Word/Markdown分别优化解析逻辑,解析准确率从68%提升至94%
- 引入BGE-Reranker对检索结果重排序,Top5召回率从71%提升至89%
- 封装动态Prompt模板,引入RAG约束+输出自校验,幻觉率降低40%
- 接口P99延迟从2.1s优化至0.4s(vLLM部署+KV Cache+流式输出)
项目难点:
- 长文档检索召回率不足(单chunk信息丢失),通过上下文窗口扩展+Parent-Child检索策略解决
- 专业术语检索效果差(纯向量对精确匹配不敏感),增加BM25精确匹配补充
- 大模型输出格式不可控(JSON解析失败率35%),引入结构化Prompt+输出自校验,解析失败率降至5%
个人收获:
- 深入掌握RAG工程化落地,积累了向量检索调优与大模型部署经验
看出区别了吗?左边5行全是操作步骤,右边每一条都是技术决策+量化结果。
# RAG项目最容易忽略的3个亮点
写RAG项目简历时,这三个亮点很多人做了但没写出来,非常可惜:
1、文档解析的优化
PDF里有表格、图片、分栏,解析不是"用了个PDF解析库"就完了。你针对不同格式做了什么优化?OCR怎么处理的?表格怎么识别的?解析准确率多少?
这往往是RAG项目里最脏最累的活,但写出来就是亮点。
2、Chunk策略的选择
Chunk怎么切直接影响检索效果。你用的是固定长度、递归切分还是语义切分?overlap设的多少?为什么?不同文档类型分别怎么处理的?
面试官问这个,是在看你有没有真的做过RAG,而不是只跑了LangChain的默认配置。
3、幻觉处理
RAG项目最大的坑就是幻觉。你做了什么来降低幻觉?RAG约束、输出自校验、检索结果和生成结果的对齐——这些都是实打实的工程问题,写出来面试官就知道你真做过。
# 一张表总结
| 维度 | 写什么 | 不写什么 |
|---|---|---|
| 检索链路设计 | 选了什么方案、为什么选、效果如何 | 只写"用了Milvus" |
| 优化策略 | 做了什么优化、从多少到多少 | "优化了检索效果" |
| 量化指标 | 准确率/召回率/延迟/成本的具体数字 | "系统性能提升了" |
RAG项目简历的核心:不是展示你搭了RAG,是展示你在检索链路上做了什么决策、解决了什么问题、拿到了什么结果。
下一篇讲Agent项目简历怎么写。
评论
验证登录状态...