# 真实简历点评:社招3年Java转型AI,简历差在哪里?
上一篇点评了校招简历,今天看一份更有代表性的——社招3年Java后端,转型大模型方向。
这类简历在知识星球 (opens new window)里越来越多。后端干了几年,觉得AI是趋势,想转型。但简历一写,问题就来了:后端经验不知道怎么体现,大模型项目又太浅,两边都不讨好。
先看原始简历,再逐条拆。
# 原始简历
技能栏
- 熟悉Java、Spring Boot、MyBatis、MySQL
- 熟悉Redis、RabbitMQ、Elasticsearch
- 熟悉微服务架构,有Dubbo/Spring Cloud项目经验
- 了解Python,了解LangChain框架
- 了解大模型基本原理
项目一:电商订单管理系统(2023.06-2025.12)
- 负责订单模块的开发和维护
- 使用Spring Boot + MyBatis实现CRUD
- 使用Redis做缓存,提升查询性能
- 使用RabbitMQ实现异步消息处理
- 日均处理订单10万+
项目二:基于RAG的内部知识库问答系统(2026.01-至今)
- 使用LangChain搭建RAG流程
- 使用Chroma作为向量数据库
- 调用GPT-4 API实现问答
- 实现了文档上传功能
# 逐条拆问题
# 技能栏:新旧割裂,AI部分太弱
问题1:前5行全是后端,AI只有2行"了解"
面试官看完技能栏的第一印象:这是一个Java后端,顺便了解了一点AI。如果你投的是大模型岗位,这个印象是致命的。
问题2:"了解Python,了解LangChain"太弱
社招3年,技能栏写"了解",面试官会觉得你只是跑了个Demo。转型简历的技能栏,AI部分至少要写到"熟悉"级别,否则面试官不会给你机会。
问题3:后端经验没有和AI方向建立联系
你的后端经验(高并发、消息队列、缓存、微服务)其实是AI工程化落地的加分项——但技能栏里完全没体现这个关联。
# 项目一:后端项目——和AI完全无关
问题1:纯CRUD,没有技术深度
"使用Spring Boot + MyBatis实现CRUD""使用Redis做缓存"——这是3年经验该写的内容吗?太基础了。
问题2:和大模型方向零关联
如果你投的是大模型岗位,这个项目在简历上的价值接近于零。面试官不会因为你做过电商CRUD就觉得你能做大模型。
但这不意味着这个项目不能写。 关键是怎么写——后面修改版会讲。
# 项目二:RAG项目——和校招一个水平
问题1:写法和校招一模一样
"使用LangChain搭建RAG流程""调用GPT-4 API"——这和上一篇点评的校招简历几乎一样。你有3年工程经验,RAG项目应该体现出工程化能力,而不是停留在Demo水平。
问题2:没有体现后端经验的迁移
你做过高并发、做过缓存、做过消息队列——这些经验在RAG项目里完全能用上。推理延迟优化、语义缓存、异步处理——这些是校招写不出来的,但你没写。
问题3:四要素全缺
没有项目描述(面向谁?什么场景?)、没有量化指标、没有难点、没有收获。
# 转型简历的核心思路:建立"桥梁"
转型简历最大的误区是:把后端经验和AI项目完全割裂,好像自己是两个人。
正确的思路是建立桥梁——让面试官看到,你的后端经验不是包袱,是AI工程化落地的加分项。
先看一张转型简历的"桥梁"结构图:
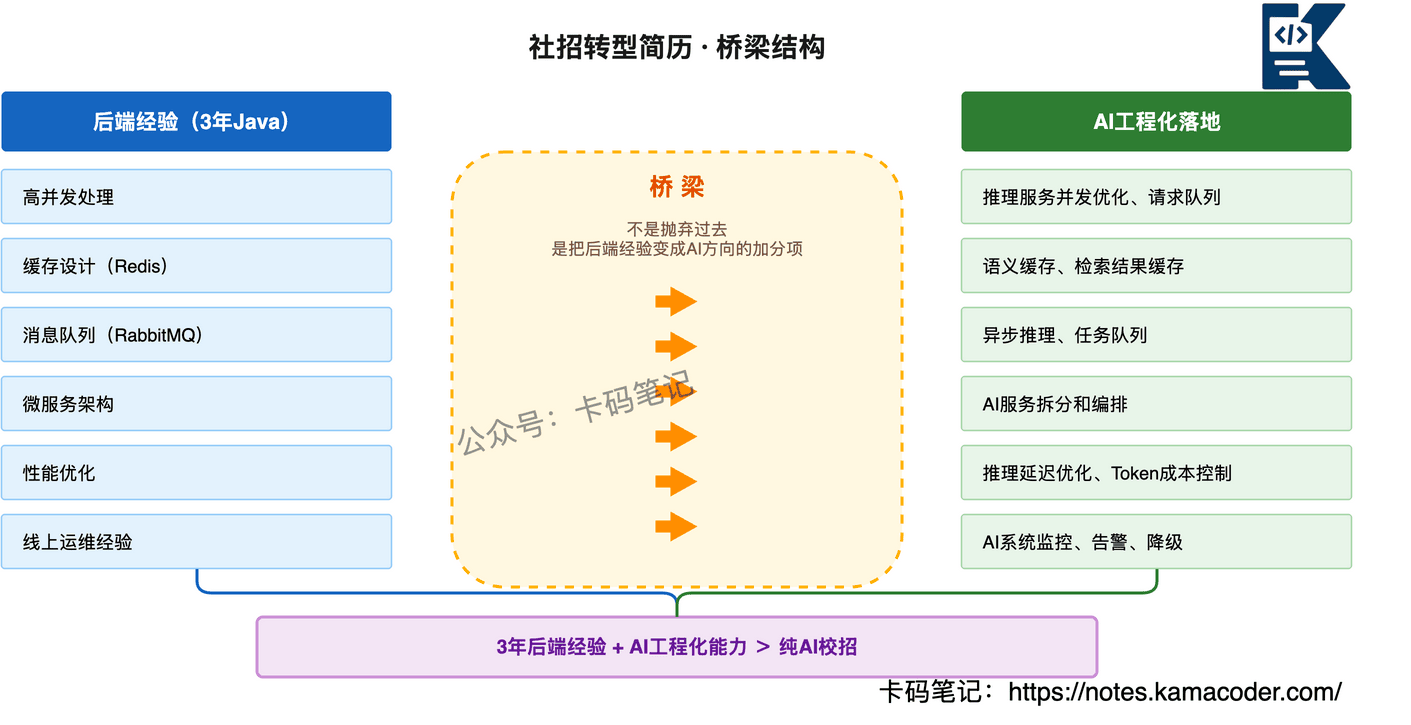
后端经验里哪些能力可以迁移到AI方向?
- 高并发处理 → 推理服务的并发优化、请求队列设计
- 缓存设计 → 语义缓存、检索结果缓存
- 消息队列 → 异步推理、任务队列
- 微服务架构 → AI服务的拆分和编排
- 性能优化 → 推理延迟优化、Token成本控制
- 线上运维经验 → AI系统的监控、告警、降级
这些迁移能力,就是你比校招强的地方。
# 修改后的简历
技能栏
- 熟悉Python/Java开发,有FastAPI + Spring Boot混合架构项目经验
- 熟悉RAG工程化落地,实践过混合检索(向量+BM25)、Rerank、Prompt优化与语义缓存
- 熟悉AI服务工程化,有推理服务部署(vLLM)、并发优化、成本控制经验
- 熟悉向量数据库(Milvus),了解HNSW索引原理
- 了解Agent开发,有Function Calling工具编排经验
- 了解大模型微调流程(SFT/LoRA)
改了什么:AI技能提到前面,后端经验融入AI语境("混合架构""AI服务工程化""并发优化"),不再是两个割裂的技能列表。
项目一:基于RAG架构的企业内部知识库问答系统(2026.01-至今)
面向公司500+员工的内部文档检索场景,支持PDF/Word/Confluence文档自动解析、语义检索与智能问答
个人工作:
- 设计向量+BM25混合检索策略,准确率从68%提升至89%
- 引入BGE-Reranker重排序,Top5召回率提升20%
- 基于后端缓存经验设计语义缓存层——相似问题(余弦相似度>0.95)命中缓存直接返回,缓存命中率38%,月Token成本降低40%
- 设计FastAPI + 异步推理架构,利用消息队列解耦请求与推理,单机QPS从12提升至35
- 封装动态Prompt模板+输出自校验,幻觉率从22%降至7%
项目难点:
- 内部文档格式混杂(PDF/Word/Confluence/飞书文档),设计多格式解析适配层,统一输出Markdown,解析覆盖率95%
- 推理延迟不满足业务要求(P99>3s),引入vLLM部署+KV Cache+流式输出,P99降至0.8s
个人收获:
- 将后端高并发和缓存经验迁移到AI系统,形成了AI服务工程化的方法论
改了什么:
- 项目描述加了场景和规模
- 个人工作里明确体现了后端经验的迁移——语义缓存、异步架构、消息队列
- 有量化指标、有难点、有收获
- 面试官一看就知道:这个人不是从零开始学AI,是把3年工程经验用在了AI上
项目二:电商订单系统智能客服模块(2025.06-2025.12)
基于原有电商订单系统,新增AI智能客服模块,支持订单查询、退款处理、物流追踪的自然语言交互
个人工作:
- 设计4类Function Calling工具(订单查询/退款申请/物流追踪/FAQ检索),工具调用成功率94%
- 基于原有订单系统API封装Agent工具层,复用已有微服务接口,开发周期缩短60%
- 实现意图识别+路由分发,简单FAQ走检索,复杂操作走Agent,Token成本降低50%
- 设计降级策略:Agent调用失败时自动转人工,保证用户体验不中断
项目难点:
- Agent需要调用多个微服务接口,接口响应时间不一致(50ms-2s),设计异步并行调用+超时降级,整体响应时间控制在3s内
- 用户意图模糊时Agent容易误调工具,引入意图确认机制(二次确认高风险操作如退款)
个人收获:
- 理解了Agent在真实业务场景中的落地挑战,积累了工具编排与降级策略的经验
改了什么:不是删掉后端项目,而是在后端项目里加入AI模块。这样一举两得——既体现了后端经验,又展示了AI能力,还说明你能在真实业务中落地AI,不是只会跑Demo。
# 转型简历的3个核心原则
1、AI项目放前面,后端项目放后面
简历的项目顺序决定了面试官的第一印象。AI项目放第一个,面试官的第一反应是"这是一个AI方向的人";后端项目放第一个,第一反应是"这是一个后端"。
2、后端经验要融入AI语境
不要把后端经验和AI经验分开写。"基于后端缓存经验设计语义缓存层""利用消息队列解耦请求与推理"——这种写法让面试官看到你的经验是连贯的,不是割裂的。
3、后端项目里加AI模块
如果你的后端项目确实和AI无关,想办法加一个AI模块进去。在电商系统里加智能客服、在运维系统里加智能告警、在CRM里加智能摘要——这比凭空编一个AI项目真实得多。
转型后面试怎么准备?Agent方向看Agent大厂面试题汇总,Harness Engineering方向看Harness Engineering面试题汇总。
社招转型简历的核心:不是抛弃过去,是把过去的经验变成AI方向的加分项。 3年后端经验 + AI工程化能力,这个组合比纯AI校招更有竞争力。
评论
验证登录状态...