# 大模型项目经历四要素写法详解:项目描述、个人工作、难点、收获逐个拆开
上一篇拆了三种烂写法,有录友跟我说:"Carl哥,我知道不能那么写了,但正确写法到底长什么样?能不能拆开讲讲?"
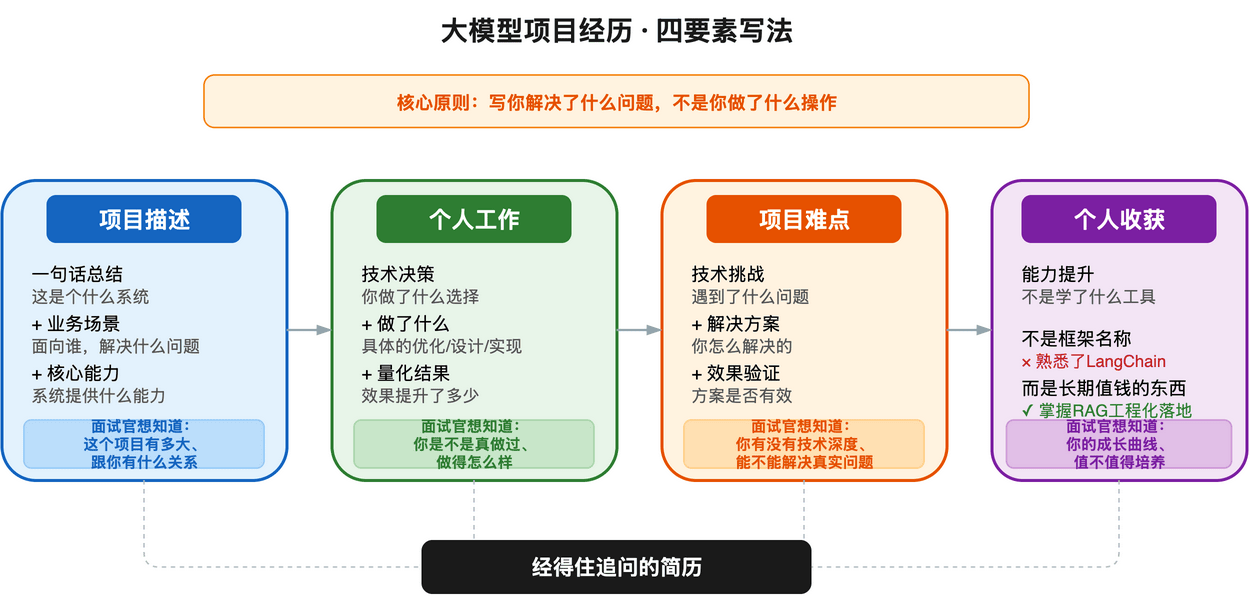
行,今天就把四要素写法在大模型项目经历上的应用,逐个要素拆开,逐条讲透。
项目描述、个人工作、项目难点、个人收获——每个要素写什么、不写什么、常见坑是什么,全给你讲清楚。
先看一张总览图:
最后附一个完整模板,直接能套。
# 要素一:项目描述——一句话让面试官知道你做了什么系统
项目描述是面试官看项目经历的第一眼。写得好,面试官知道这个项目的规模、场景、技术方向;写得差,面试官看半天不知道你做了个什么东西。
项目描述 = 一句话总结 + 业务场景 + 核心能力
- 一句话总结:这是个什么系统
- 业务场景:面向谁、解决什么问题、规模多大
- 核心能力:系统提供什么能力
反面:
基于大模型的智能问答系统
面试官看完:什么大模型?什么问答?面向谁?多大体量?跟我在家里跑的Demo有什么区别?
正面:
基于RAG架构的企业知识库问答系统,面向10万+内部员工的知识检索场景,实现文档自动解析、语义检索与智能生成
面试官一眼就知道:RAG方向、企业级、10万+用户、完整链路。
写项目描述最常见的三个坑:
只写技术不写场景。"基于RAG架构的问答系统"——没有场景,面试官不知道这个系统的价值在哪。加上"面向10万+内部员工的知识检索场景",立刻不一样。
场景太模糊。"面向企业用户"——什么企业?多大?"面向10万+内部员工的知识检索场景"才叫具体。
把功能列表当项目描述。"实现了文档解析、向量检索、智能问答"——这是功能列表,不是项目描述。项目描述是"一句话+场景+能力",功能列表放到个人工作里写。
# 要素二:个人工作——你的技术决策和结果,不是你的操作步骤
个人工作是项目经历里最重要的部分。面试官看这部分,是在判断你到底是"做了个Demo"还是"真正解决了问题"。
个人工作 = 技术决策 + 做了什么 + 结果是什么
每一条写法:做了什么技术选择/优化 → 拿到了什么结果
看张图更直观:
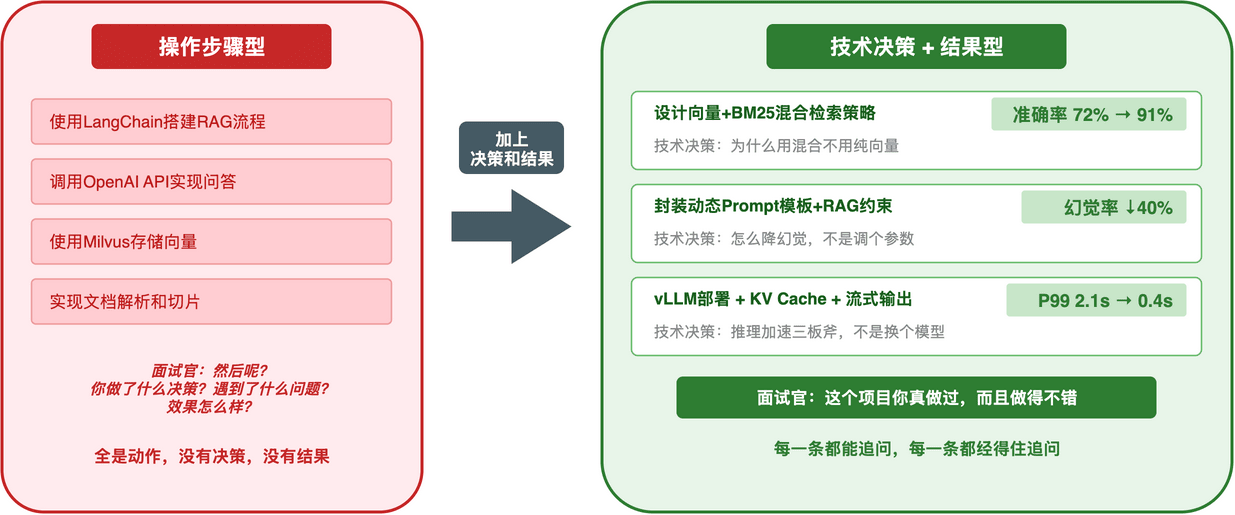
反面:
- 使用LangChain搭建RAG流程
- 调用OpenAI API实现问答
- 使用Milvus存储向量
- 实现文档解析和切片
面试官看完:LangChain的默认配置?Milvus用的什么索引?你做了什么决策?遇到问题了吗?解决了什么?
全是操作步骤,没有决策,没有结果。
正面:
- 设计向量+BM25混合检索策略,准确率从72%提升至91%
- 封装动态Prompt模板,幻觉率降低40%
- 接口P99延迟从2.1s优化至0.4s
- 实现文档自动解析(PDF/Word/Markdown),解析准确率从68%提升至94%
每一条都是:做了什么选择 → 拿到了什么结果。
写个人工作最常见的三个坑:
只有动作没有结果。"使用Milvus存储向量"——然后呢?性能怎么样?索引怎么选的?换成"选用Milvus做向量存储,HNSW索引检索延迟<50ms",面试官才知道你做了选择、拿到了结果。
只有框架没有决策。"使用LangChain搭建RAG流程"——LangChain的默认pipeline谁不会跑?换成"设计Chunk分段策略(递归切分+overlap=200),针对PDF/Word/Markdown分别优化解析逻辑",面试官才知道你动了脑子。
没有量化指标。"优化了检索效果"——怎么优化的?提升了多少?换成"准确率从72%提升至91%",有基线、有结果、有对比,面试官才能判断你的工作价值。
如果项目没有指标怎么办?
说实话,大模型项目完全没指标的情况很少。你至少能提供这些:
- 检索类:准确率、召回率、延迟、QPS
- 生成类:幻觉率、可读性评分、人工评测通过率
- 工程类:并发量、推理延迟、Token成本、部署资源占用
实在没有精确指标,给一个估算值也行:"检索延迟降低约60%"比"优化了检索速度"强100倍。
# 要素三:项目难点——面试官最想追问的部分
项目难点是面试官最想看的,也是最容易拉开差距的。
为什么?因为大模型项目天然有很多坑——检索不准、幻觉严重、延迟太高、成本失控、工具调用不稳定——你遇到过的坑、解决过的难题,就是你的技术深度。
项目难点 = 技术挑战 + 你的解决方案
每一条写法:遇到了什么问题 → 你怎么解决的
反面:
- 大模型存在幻觉问题
- 检索效果不太好
- 延迟比较高
这是在描述问题,不是在写难点。面试官想看的是你怎么解决的。
正面:
- 长文档检索召回率不足(单chunk信息丢失),通过递归切分+上下文窗口扩展解决,召回率从65%提升至87%
- 大模型输出格式不可控(JSON解析失败率35%),引入RAG约束+结构化Prompt+输出自校验,解析失败率降至5%
- 多步推理中Agent行为漂移(长对话上下文丢失),通过滑动窗口+关键信息摘要机制稳定Agent行为
每一条都是:问题 → 方案 → 效果。
写项目难点最常见的三个坑:
只写问题不写方案。"大模型存在幻觉"——这是行业共识,不是你的难点。你做了什么来降低幻觉?RAG约束?自校验?Prompt改写?写出来。
难点太泛。"检索效果不太好"——什么场景下不好?哪一步出了问题?是embedding选错了?chunk太大了?没有rerank?具体到某一步,面试官才觉得你真做过。
把通用问题当难点。"需要处理高并发"——这不是大模型项目的难点,这是所有后端项目的难点。大模型项目的难点应该跟大模型本身相关:推理延迟、Token成本、幻觉、上下文窗口限制、工具调用稳定性。
大模型项目最常见的真实难点,帮你列几个:
- 检索不准:向量检索对专业术语召回差,混合检索策略怎么设计
- 幻觉严重:RAG约束怎么加、输出怎么校验
- 输出不可控:结构化输出怎么做、解析失败怎么兜底
- 延迟太高:vLLM部署、KV Cache、流式输出、模型量化
- 成本失控:Token怎么控制、缓存怎么做、请求怎么合并
- Agent翻车:多步推理中断、工具调用死循环、上下文污染
遇到过的就写,没遇到过的别编。 面试官会顺着你的难点往下问,编的方案经不住追问。
# 要素四:个人收获——写能力提升,别写框架名称
个人收获是最容易写水的部分,但也最容易忽略。
大多数人的写法:
- 熟悉了LangChain框架
- 了解了RAG流程
- 掌握了向量数据库的使用
这不是收获,这是学了什么东西的清单。面试官看完没有任何感觉。
个人收获要写的是:你通过这个项目,能力提升了什么。
反面:
- 熟悉了LangChain框架
- 了解了RAG流程
- 掌握了向量数据库的使用
正面:
- 深入掌握RAG工程化落地,积累了向量检索调优与大模型部署经验
- 提升了AI系统的性能优化能力,从模型选型到推理加速形成完整方法论
- 理解了Agent设计的核心挑战,积累了工具编排与错误恢复的工程经验
区别在哪?左边写的是"我学了什么工具",右边写的是"我提升了什么能力"。
写个人收获最常见的坑:
写框架名称不写能力。"熟悉了LangChain"——LangChain可能半年后就过时了,但你通过用LangChain积累的"RAG工程化落地能力"是长期值钱的东西。
收获太泛。"提升了编程能力"——什么编程能力?后端开发能力?AI系统优化能力?具体一点。
收获跟项目不匹配。项目写的是RAG,收获写"提升了算法能力"——你做的是RAG应用开发,不是算法研究,收获要跟项目方向一致。
# 完整模板:直接套用
下面给一个RAG项目的完整写法模板,四个要素全有,你替换成自己的内容就行:
基于RAG架构的企业知识库问答系统,面向10万+内部员工的知识检索场景,实现文档自动解析、语义检索与智能生成
个人工作:
- 设计向量+BM25混合检索策略,准确率从72%提升至91%
- 实现递归切分+overlap=200的Chunk策略,针对PDF/Word/Markdown分别优化解析逻辑,解析准确率从68%提升至94%
- 封装动态Prompt模板,引入RAG约束+输出自校验,幻觉率降低40%
- 接口P99延迟从2.1s优化至0.4s(vLLM部署+KV Cache+流式输出)
项目难点:
- 长文档检索召回率不足(单chunk信息丢失),通过上下文窗口扩展+Parent-Child检索策略解决
- 大模型输出格式不可控(JSON解析失败率35%),引入结构化Prompt+输出自校验,解析失败率降至5%
个人收获:
- 深入掌握RAG工程化落地,积累了向量检索调优与大模型部署经验
- 理解了检索质量和生成质量的评估体系,形成了RAG系统优化的方法论
每一条都能经住追问。 面试官问"为什么用混合检索不用纯向量"——你写了准确率从72%到91%的数据;问"幻觉怎么降的"——你写了RAG约束+自校验的具体方案;问"延迟怎么优化的"——你写了vLLM+KV Cache+流式的技术路径。
这叫经得住追问的简历。
# 一张表总结
| 要素 | 写什么 | 不写什么 | 常见坑 |
|---|---|---|---|
| 项目描述 | 一句话+业务场景+核心能力 | 功能列表 | 只写技术不写场景 |
| 个人工作 | 技术决策+量化结果 | 操作步骤 | 有动作没结果 |
| 项目难点 | 挑战+方案+效果 | 问题描述 | 只写问题不写方案 |
| 个人收获 | 能力提升 | 框架名称 | 写工具不写能力 |
核心原则就一句:面试官看项目经历,不是看你做了什么操作,是看你解决了什么问题、怎么解决的、效果如何。
下一篇开始,我会按RAG、Agent、微调三个方向,分别讲项目经历怎么写出技术深度。每个方向都有不一样的亮点挖掘方式,不一样的话术,不一样的常见坑。
评论
验证登录状态...